标签:缓存系统 查找 通过 用户id 否则 智能 ase mysql 散列
分布式、海量数据
新摩尔定律,根据IDC作出的预测,数据一直都在以每年50%的速度增长,也就是说每两年增加一倍,这意味着人类在最近两年产生的数据量相当于之前产生的全部数据量。
分布式环境下的RPC调用速度更慢,差不多是单机环境的100倍;但可以通过扩展,使性能线性增长。
分布式存储是云存储和大数据的基础。
分布式存储涉及的技术主要有:数据分布,均匀分布;自动容错,备份;一致性;分布式事务;负载均衡,新增服务器和集群运行中实现负载均衡。
数据模型,文件模型、对象模型、键值模型、关系弱化的表格模型、关系模型
1、分布式文件系统,存储图片、照片、视频等非结构化数据对象,这类数据以对象的形式组织,对象之间没有关联,这样的数据一般称为Blob(Binary Large Object,二进制大对象)数据。
2、对象模型与文件模型比较类似,用于存储图片、视频、文档等二进制数据块,Amazon Simple Storage(S3),Taobao File System(TFS),这些系统弱化了目录树的概念。
3、分布式键值系统,只提供基于主键的CRUD功能。一般用作缓存,比如Memcache。数据分布常用一致性哈希算法。
从数据结构的角度看,分布式键值系统与传统的哈希表比较类似,不同的是,分布式键值系统支持将数据分布到集群中的多个存储节点。
4、分布式表格系统,存储关系较为复杂的半结构化数据,往往还支持无模式,不需要预先定义列,多行之间允许包含不同列。
与分布式键值系统相比,不仅支持基于主键的CRUD,还支持主键范围查找。
与分布式数据库相比,主要支持针对单张表格的操作,不支持一些特别复杂的操作,比如多表关联,多表联接,嵌套子查询。
分布式表格系统还借鉴了很多关系数据库的技术,如支持某种程度上的事务。
典型的系统是Google Bigtable以及其开源Java实现HBase。
5、分布式数据库,MySQL数据库分片(MySQL Sharding)集群
NoSQL系统有的是键值模型,有的是表格模型。
存储引擎就是哈希表、B树等数据结构在机械磁盘、SSD等持久化介质上的实现。哈希存储引擎是哈希表的持久化实现。
哈希存储引擎不支持顺序扫描;B树存储引擎;LSM树存储引擎(Log-Structured Merge Tree),Google Bigtable、Google LevelDB。
1、Bitcask是一个基于哈希表结构的键值存储系统,它仅支持追加操作(Append-only)。
2、数据库,修改操作首先需要记录提交日志,接着修改内存中的B+树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。
3、LSM树将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘。LSM树有效地规避了磁盘随机写入问题。
LevelDB,MemTable、不可变MemTable、SSTable文件、清单文件。
写入时,先日志文件,再应用到MemTable,这样就完成了写入操作。
读取时,MemTable、不可变MemTable、SSTable。SSTable文件是按主键排序的,每个文件有最小主键和最大主键。清单文件记录最小主键和最大主键。
分布式存储系统中往往有一个总控节点用于执行工作机管理,维护数据分布信息,数据定位,负载均衡,故障检测和恢复等全局调度工作。
工作节点刚上线时,总控节点需要将数据迁移到该节点,另外,系统运行过程中也需要不断地执行迁移任务,将数据从负载较高的工作节点迁移到负载较低的工作节点。
数据分布
哈希分布
哈希取模,将集群中的服务器按0到N-1编号(N为服务器的数量),根据数据的主键(hash(key)%N)或者数据所属的用户id(hash(user_id)%N)计算哈希值,来决定将数据映射到哪一台服务器。
如果按照主键散列,那么同一个用户id下的数据可能被分散到多台服务器,这会使得一次操作同一个用户id下的多条记录变得困难;如果按照用户id散列,容易出现“数据倾斜”(data skew)问题,即某些大用户的数据量很大,无论集群的规模有多大,这些用户始终由一台服务器处理。
当服务器上线或者下线时,N值发生变化,数据映射完全被打乱。
一致性哈希,代表为Amazon的Dynamo
顺序分布,Google的Bigtable将一张大表根据主键切分为有序的范围,每个有序范围是一个子表。
主副本复制协议,同一份数据的多个副本中往往有一个副本为主副本(Primary),其他副本为备副本(Backup),由主副本将数据复制到备份副本。
复制协议分为两种,强同步复制以及异步复制,二者的区别在于用户的写请求是否需要同步到备副本才可以返回成功。
强同步复制协议可以保证主备副本之间的一致性,但是当备副本出现故障时,也可能阻塞存储系统的正常写服务,系统的整体可用性受到影响;异步复制协议的可用性相对较好,但是一致性得不到保障,主副本出现故障时还有数据丢失的可能。
主副本将写请求复制到其他备副本,常见的做法是同步操作日志。
NWR复制协议,其中,N为副本数量,W为写操作的副本数,R为读操作的副本数。NWR协议中多个副本不再区分主和备。
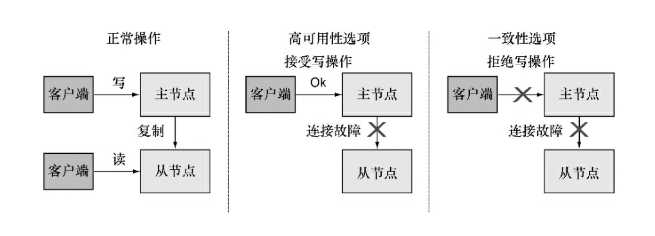
存储系统可以支持强一致性,也可以为了性能考虑只支持最终一致性。Alibaba的OceanBase系统以及Google的分布式存储系统都倾向强一致性。
CAP定理,在任何分布式数据库系统中最多只能满足3个中的2个,一致性;可用性;容错性。
CAP定理图示:
故障检测往往通过租约(Lease)协议实现,租约机制就是带有超时时间的一种授权。
Paxos协议用于多个节点之间达成一致,往往用于实现总控节点选举。Paxos协议用于确保多个节点对某个投票(例如哪个节点为主节点)达成一致。
Paxos协议实现的分布式锁服务,比如Google Chubby或者它的开源实现Apache Zookeeper。
两阶段提交协议用于保证跨多个节点操作的原子性,这些操作要么全部成功,要么全部失败;这个协议的性能很低。
在两阶段协议中,系统一般包含两类节点:一类为协调者( coordinator),通常一个系统中只有一个;另一类为事务参与者( participants, cohorts 或 workers),一般包含多个。
1、阶段1:请求阶段(Prepare Phase)。在请求阶段,协调者通知事务参与者准备提交或者取消事务,然后进入表决过程。在表决过程中,参与者将告知协调者自己的决策:同意(事务参与者本地执行成功)或者取消(事务参与者本地执行失败)。
2、阶段2:提交阶段(Commit Phase)。在提交阶段,协调者将基于第一个阶段的投票结果进行决策:提交或者取消。当且仅当所有的参与者同意提交事务协调者才通知所有的参与者提交事务,否则协调者通知所有的参与者取消事务。参与者在接收到协调者发来的消息后将执行相应的操作。
A组织B、C和D三个人去爬长城:如果所有人都同意去爬长城,那么活动将举行;如果有一人不同意去爬长城,那么活动将取消。
假如D一直不能回复邮件,那么A、B和C将不得不处于一直等待的状态。并且B和C所持有的资源一直不能释放,
A可以通过引入事务的超时机制防止资源一直不能释放的情况。
更为严重的是,假如A发完邮件后生病住院了,即使B、C和D都发邮件告诉A同意下周三去爬长城,如果A没有备份,事务将被阻塞。
两阶段提交协议可能面临两种故障:
●事务参与者发生故障。给每个事务设置一个超时时间,如果某个事务参与者一直不响应,到达超时时间后整个事务失败。
●协调者发生故障。协调者需要将事务相关信息记录到操作日志并同步到备用协调者,假如协调者发生故障,备用协调者可以接替它完成后续的工作
2PC和Paxos协议结合起来,通过2PC保证多个数据分片上的操作的原子性,通过Paxos协议实现同一个数据分片的多个副本之间的一致性。另外,通过Paxos协议解决2PC协议中协调者宕机问题。
CDN通过将网络内容发布到靠近用户的边缘节点,使不同地域的用户在访问相同网页时可以就近获取。
所谓的边缘节点是CDN服务提供商经过精心挑选的距离用户非常近的服务器节点,仅“一跳”(Single Hop)之遥。用户在访问时就无需再经过多个路由器,大大减少访问时间。
DNS在对域名解析时不再向用户返回源服务器的IP,而是返回了由智能CDN负载均衡系统选定的某个边缘节点的IP。用户利用这个IP访问边缘节点,然后该节点通过其内部DNS解析得到源服务器IP并发出请求来获取用户所需的页面,如果请求成功,边缘节点会将页面缓存下来,下次用户访问时可以直接读取,而不需要每次都访问源服务器。
相比分布式存储系统,分布式缓存系统的实现要容易很多。这是因为缓存系统不需要考虑数据持久化,如果缓存服务器出现故障,只需要简单地将它从集群中剔除即可。
OceanBase,阿里,分布式数据库,收藏夹。
实现分布式事务最直接的做法是采用两阶段提交协议;
分析,发现,虽然在线业务的数据量十分庞大,但最近一段时间(例如一天)的修改量往往并不多,采用单台更新服务器来记录最近一段时间的修改增量,而以前的数据保持不变,避免了复杂的分布式事务,高效地实现了跨行跨表事务,更新服务器上的修改增量能够定期分发到多台基线数据服务器中。
标签:缓存系统 查找 通过 用户id 否则 智能 ase mysql 散列
原文地址:https://www.cnblogs.com/Mike_Chang/p/11627029.html