标签:enable stc 表数 分配 工具类 提高 搜索 cpu 核数 screen
不变的东西就是一直在变化中。
想必,大家在闲暇时刻,会经常看视频,经常用的几个 APP,比如优酷、爱奇艺、腾讯等。
这些视频 APP 不仅仅可以在手机上播放,还能够支持在电视上播放。
在电视终端上播放的 APP 是独立发布的版本,跟手机端的 APP 是不一样的。
当我们看一部电影时,点击进入某一部电影,就进入到了专辑详情页页面,此时,播放器会自动播放视频。用户在手机上看到的专辑详情页,与电视上看到的专辑详情页,页面样式设计上是不同的。
我们来直观的看一下效果。
手机上的腾讯视频专辑详情页:
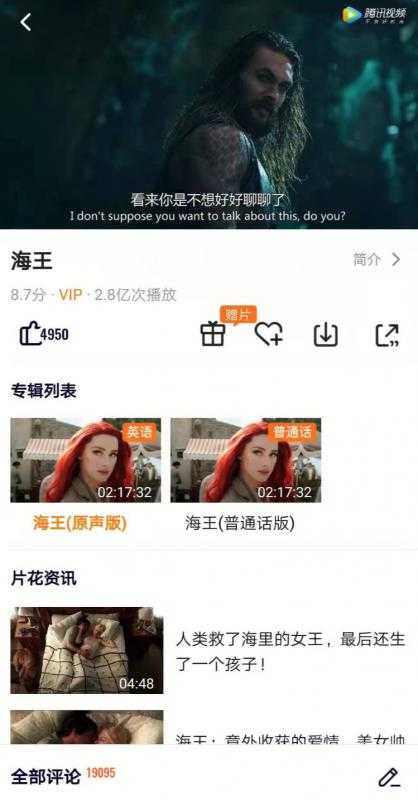
上半部分截图,下面还有为你推荐、明星演员、周边推荐、评论等功能。
相应的,在电视端的专辑详情页展示方式是不一样的。假设产品经理提出一个需求,要求对详情页做个改版。
样式要求如下图所示:

两个终端的样式对比,在电视端专辑详情页中,包含了很多板块,每个板块横向展示多个内容。
产品的设计上要求是,有的板块内容来源于推荐、有的板块来源于搜索、有的板块来源CMS(内容管理系统)。简单理解为,每个板块内容来源不同,来源于推荐、搜索等接口的内容要求是近实时的请求。
2、技术设计方案思考
考虑到产品提的这个需求,其实实现起来并不难。
主要分为了静态数据部分和动态数据部分,对于不经常变化的数据可以通过静态接口获取,对于近乎实时的数据可以通过动态接口获取。
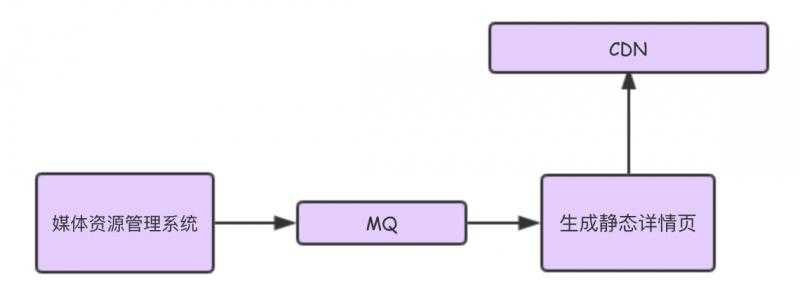
静态接口设计:
专辑本身的属性以及专辑下的视频数据,一般是不经常变化的。
在需求场景介绍中,我截图的是电影频道。如果是电视剧频道,会展示剧集列表(专辑下的所有视频,如第 1 集、第 2 集...),而视频的更新一般是不太频繁的,所以在专辑详情页剧集列表数据就可以从静态接口获取。
静态接口数据生成流程:
另外一部分,就是需要动态接口来实现,调用第三方接口获取数据,比如推荐、搜索数据。
同时,要求板块与板块之间的内容不允许重复。
动态接口设计:
方案一:
串行调用,即按照每个板块的展示先后顺序,调用相应的第三方接口获取数据。
方案二:
并行调用,即多个板块之间可以并行调用,提高整体接口响应效率。
其实以上两个方案,各有利弊。
方案一串行调用,好处是开发模型简单,按照串行方式依次调用接口,内容数据去重,聚合所有的数据返回给客户端。
但是,接口响应时间依赖于第三方接口的响应时间,通常第三方接口总是不可靠的,可能就会拉高接口整体响应时间,进而导致占用线程时间过长,影响接口整体吞吐量。
方案二并行调用,理论上是可以提高接口的整体响应时间,假设同时调用多个第三方接口,取决于最慢的接口响应时间。
并行调用时,需要考虑到「池化技术」,即不能无限制的在 JVM 进程上创建过多的线程。同时,也要考虑到板块与板块之间的内容数据,要按照产品设计上的先后顺序做去重。
根据这个需求场景,我们选择第二种方案来实现更合适一些。
选择了方案二,我们抽象出如下图所示的简易模型:
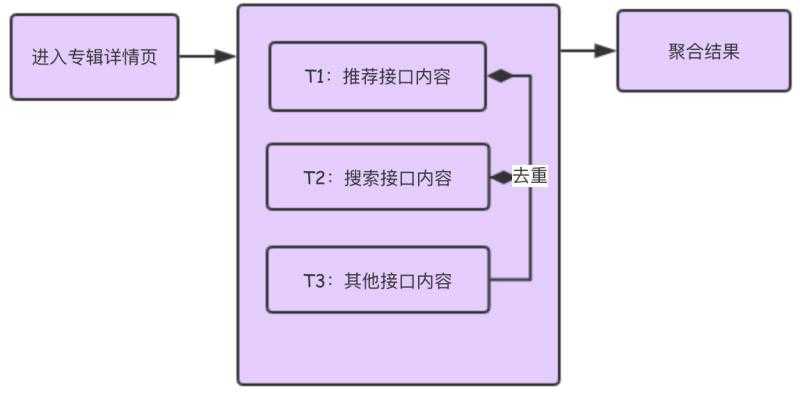
T1、T2、T3 表示多个板块内容线程。T1 线程先返回结果,T2 线程返回的结果不能与与 T1 线程返回的结果内容重复,T3 线程返回的结果不能与 T1、T2 两个线程返回的结果内容重复。
我们从技术实现上考量,当并行调用多个第三方接口时,需要获取接口的返回结果,首先想到的就是 Future ,能够实现异步获取任务结果。
另外,JDK8 提供了 CompletableFuture 易于使用的获取异步结果的工具类,解决了 Future 的一些使用上的痛点,以更优雅的方式实现组合式异步编程,同时也契合函数式编程。
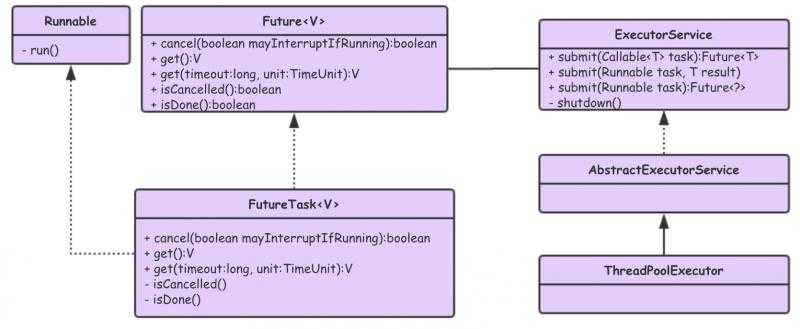
Future 接口设计:
提供了获取任务结果、取消任务、判断任务状态接口。调用获取任务结果方法,在任务未完成情况下,会导致调用阻塞。
Future 接口提供的方法:
```
// 获取任务结果
V get() throws InterruptedException, ExecutionException;
// 支持超时时间的获取任务结果
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
// 判断任务是否已完成
boolean isDone();
// 判断任务是否已取消
boolean isCancelled();
// 取消任务
boolean cancel(boolean mayInterruptIfRunning);
```
通常,我们在考虑到使用 Future 获取任务结果时,会使用 ThreadPoolExecutor 或者 FutureTask 来实现功能需求。
ThreadPoolExecutor、FutureTask 与 Future 接口关系类图:
TheadPoolExecutor 提供三个 submit 方法:
// 1. 提交无需返回值的任务,Runnable 接口 run() 方法无返回值
public Future<?> submit(Runnable task) {
}
// 2. 提交需要返回值的任务,Callable 接口 call() 方法有返回值
public <T> Future<T> submit(Callable<T> task) {
}
// 3. 提交需要返回值的任务,任务结果是第二个参数 result 对象
public <T> Future<T> submit(Runnable task, T result) {
}第 3 个 submit 方法使用示例如下所示:
static String x = "东升的思考";
public static void main(String[] args) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(1);
// 创建 Result 对象 r
Result r = new Result();
r.setName(x);
// 提交任务
Future<Result> future =
executor.submit(new Task(r), r);
Result fr = future.get();
// 下面等式成立
System.out.println(fr == r);
System.out.println(fr.getName() == x);
System.out.println(fr.getNick() == x);
}
static class Result {
private String name;
private String nick;
// ... ignore getter and setter
}
static class Task implements Runnable {
Result r;
// 通过构造函数传入 result
Task(Result r) {
this.r = r;
}
@Override
public void run() {
// 可以操作 result
String name = r.getName();
r.setNick(name);
}
}执行结果都是true。
FutureTask 设计实现:
实现了 Runnable 和 Future 两个接口。实现了 Runnable 接口,说明可以作为任务对象,直接提交给 ThreadPoolExecutor 去执行。实现了 Future 接口,说明能够获取执行任务的返回结果。
我们来根据产品的需求,使用 FutureTask 模拟两个线程,通过示例实现下功能。
结合示例代码注释理解:
public static void main(String[] args) throws Exception {
// 创建任务 T1 的 FutureTask,调用推荐接口获取数据
FutureTask<String> ft1 = new FutureTask<>(new T1Task());
// 创建任务 T1 的 FutureTask,调用搜索接口获取数据,依赖 T1 结果
FutureTask<String> ft2 = new FutureTask<>(new T2Task(ft1));
// 线程 T1 执行任务 ft1
Thread T1 = new Thread(ft1);
T1.start();
// 线程 T2 执行任务 ft2
Thread T2 = new Thread(ft2);
T2.start();
// 等待线程 T2 执行结果
System.out.println(ft2.get());
}
// T1Task 调用推荐接口获取数据
static class T1Task implements Callable<String> {
@Override
public String call() throws Exception {
System.out.println("T1: 调用推荐接口获取数据...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T1: 得到推荐接口数据...");
TimeUnit.SECONDS.sleep(10);
return " [T1 板块数据] ";
}
}
// T2Task 调用搜索接口数据,同时需要推荐接口数据
static class T2Task implements Callable<String> {
FutureTask<String> ft1;
// T2 任务需要 T1 任务的 FutureTask 返回结果去重
T2Task(FutureTask<String> ft1) {
this.ft1 = ft1;
}
@Override
public String call() throws Exception {
System.out.println("T2: 调用搜索接口获取数据...");
TimeUnit.SECONDS.sleep(1);
System.out.println("T2: 得到搜索接口的数据...");
TimeUnit.SECONDS.sleep(5);
// 获取 T2 线程的数据
System.out.println("T2: 调用 T1.get() 接口获取推荐数据");
String tf1 = ft1.get();
System.out.println("T2: 获取到推荐接口数据:" + tf1);
System.out.println("T2: 将 T1 与 T2 板块数据做去重处理");
return "[T1 和 T2 板块数据聚合结果]";
}
}执行结果如下:
> Task :FutureTaskTest.main()
T1: 调用推荐接口获取数据...
T2: 调用搜索接口获取数据...
T1: 得到推荐接口数据...
T2: 得到搜索接口的数据...
T2: 调用 T1.get() 接口获取推荐数据
T2: 获取到推荐接口数据: [T1 板块数据]
T2: 将 T1 与 T2 板块数据做去重处理
[T1 和 T2 板块数据聚合结果] 小结:
Future 表示「未来」的意思,主要是将耗时的一些操作任务,交给单独的线程去执行。从而达到异步的目的,提交任务的当前线程,在提交任务后和获取任务结果的过程中,当前线程可以继续执行其他操作,不需要在那傻等着返回执行结果。
对于 Future 设计模式,虽然我们提交任务时,不会进入任何阻塞,但是当调用方要获得这个任务的执行结果,还是可能会阻塞直至任务执行完成。
在 JDK1.5 设计之初就一直存在这个问题,发展到 JDK1.8 引入了 CompletableFuture 才得到完美的增强。
在此期间,Google 开源的 Guava 工具包提供了 ListenableFuture ,用于支持任务完成时支持回调方式,感兴趣的朋友们可以自行查阅研究。
在业务需求场景介绍中,不同板块的数据来源是不同的,并且板块与板块之间是存在数据依赖关系的。
可以理解为任务与任务之间是有时序关系的,而根据 CompletableFuture 提供的一些功能特性,是非常适合这种业务场景的。
CompletableFuture 类图:
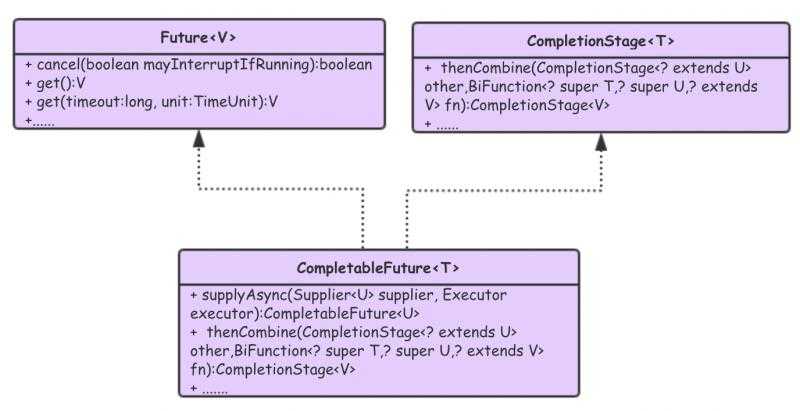
CompletableFuture 实现了 Future 和 CompletionStage 两个接口。实现 Future 接口是为了关注异步任务什么时候结束,和获取异步任务执行的结果。实现 CompletionStage 接口,其提供了非常丰富的功能,实现了串行关系、并行关系、汇聚关系等。
CompletableFuture 核心优势:
1)无需手工维护线程,给任务分配线程的工作无需开发人员关注;
2)在使用上,语义更加清晰明确;
例如:t3 = t1.thenCombine(t2, () -> { // doSomething ... } 能够明确的表述任务 3 要等任务 2 和 任务 1完成后才会开始执行。
3)代码更加简练,支持链式调用,让你更专注业务逻辑。
4)方便的处理异常情况
接下来,通过 CompletableFuture 来模拟实现专辑下多板块数据聚合处理。
代码如下所示:
public static void main(String[] args) throws Exception {
// 暂存数据
List<String> stashList = Lists.newArrayList();
// 任务 1:调用推荐接口获取数据
CompletableFuture<String> t1 =
CompletableFuture.supplyAsync(() -> {
System.out.println("T1: 获取推荐接口数据...");
sleepSeconds(5);
stashList.add("[T1 板块数据]");
return "[T1 板块数据]";
});
// 任务 2:调用搜索接口获取数据
CompletableFuture<String> t2 =
CompletableFuture.supplyAsync(() -> {
System.out.println("T2: 调用搜索接口获取数据...");
sleepSeconds(3);
return " [T2 板块数据] ";
});
// 任务 3:任务 1 和任务 2 完成后执行,聚合结果
CompletableFuture<String> t3 =
t1.thenCombine(t2, (t1Result, t2Result) -> {
System.out.println(t1Result + " 与 " + t2Result + "实现去重逻辑处理");
return "[T1 和 T2 板块数据聚合结果]";
});
// 等待任务 3 执行结果
System.out.println(t3.get(6, TimeUnit.SECONDS));
}
static void sleepSeconds(int timeout) {
try {
TimeUnit.SECONDS.sleep(timeout);
} catch (InterruptedException e) {
e.printStackTrace();
}
}执行结果如下:
> Task :CompletableFutureTest.main()
T1: 获取推荐接口数据...
T2: 调用搜索接口获取数据...
[T1 板块数据] 与 [T2 板块数据] 实现去重逻辑处理
[T1 和 T2 板块数据聚合结果]上述的示例代码在 IDEA 中新建个Class,直接复制进去,即可正常运行。
创建合理的线程池:
在生产环境下,不建议直接使用上述示例代码形式。因为示例代码中使用的
CompletableFuture.supplyAsync(() -> {});
创建 CompletableFuture 对象的 supplyAsync() 方法(这里使用的工厂方法模式),底层使用的默认线程池,不一定能满足业务需求。
结合底层源代码来看一下:
// 默认使用 ForkJoinPool 线程池
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) {
return asyncSupplyStage(asyncPool, supplier);
}创建 ForkJoinPool 线程池:
默认线程池大小是 Runtime.getRuntime().availableProcessors() - 1(CPU 核数 - 1),可以通过 JVM 参数 -Djava.util.concurrent.ForkJoinPool.common.parallelism 设置线程池大小。
JVM 参数上配置 -Djava.util.concurrent.ForkJoinPool.common.threadFactory 设置线程工厂类;配置 -Djava.util.concurrent.ForkJoinPool.common.exceptionHandler 设置异常处理类,这两个参数设置后,内部会通过系统类加载器加载 Class。
如果所有 CompletableFuture 都使用默认线程池,一旦有任务执行很慢的 I/O 操作,就会导致所有线程都阻塞在 I/O 操作上,进而影响系统整体性能。
所以,建议大家在生产环境使用时,根据不同的业务类型创建不同的线程池,以避免互相影响。
CompletableFuture 还提供了另外支持线程池的方法。
// 第二个参数支持传递 Executor 自定义线程池
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier,
Executor executor) {
return asyncSupplyStage(screenExecutor(executor), supplier);
}自定义线程池,建议参考 「阿里巴巴 Java 开发手册」,推荐使用 ThreadPoolExecutor 自定义线程池,使用有界队列,根据实际业务情况设置队列大小。
线程池大小的设置,在 「Java 并发编程实战」一书中,Brian Goetz 提供了不少优化建议。如果线程池数量过多,竞争 CPU 和内存资源,导致大量时间在上下文切换上。反之,如果线程池数量过少,无法充分利用 CPU 多核优势。
线程池大小与 CPU 处理器的利用率之比可以用下面公式估算:

异常处理:
CompletableFuture 提供了非常简单的异常处理 ,如下这些方法,支持链式编程方式。
// 类似于 try{}catch{} 中的 catch{}
public CompletionStage<T> exceptionally
(Function<Throwable, ? extends T> fn);
// 类似于 try{}finally{} 中的 finally{},不支持返回结果
public CompletionStage<T> whenComplete
(BiConsumer<? super T, ? super Throwable> action);
public CompletionStage<T> whenCompleteAsync
(BiConsumer<? super T, ? super Throwable> action);
// 类似于 try{}finally{} 中的 finally{},支持返回结果
public <U> CompletionStage<U> handle
(BiFunction<? super T, Throwable, ? extends U> fn);
public <U> CompletionStage<U> handleAsync
(BiFunction<? super T, Throwable, ? extends U> fn);循环压测任务数如下所示,每次执行压测,从 1 到 jobNum 数据叠加汇聚结果,计算耗时。
统计维度:CompletableFuture 默认线程池 与 自定义线程池。
性能测试代码:
// 性能测试代码
Arrays.asList(-3, -1, 0, 1, 2, 4, 5, 10, 16, 17, 30, 50, 100, 150, 200, 300).forEach(offset -> {
int jobNum = PROCESSORS + offset;
System.out.println(
String.format("When %s tasks => stream: %s, parallelStream: %s, future default: %s, future custom: %s",
testCompletableFutureDefaultExecutor(jobNum), testCompletableFutureCustomExecutor(jobNum)));
});
// CompletableFuture 使用默认 ForkJoinPool 线程池
private static long testCompletableFutureDefaultExecutor(int jobCount) {
List<CompletableFuture<Integer>> tasks = new ArrayList<>();
IntStream.rangeClosed(1, jobCount).forEach(value -> tasks.add(CompletableFuture.supplyAsync(CompleteableFuturePerfTest::getJob)));
long start = System.currentTimeMillis();
int sum = tasks.stream().map(CompletableFuture::join).mapToInt(Integer::intValue).sum();
checkSum(sum, jobCount);
return System.currentTimeMillis() - start;
}
// CompletableFuture 使用自定义的线程池
private static long testCompletableFutureCustomExecutor(int jobCount) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(200, 200, 5, TimeUnit.MINUTES, new ArrayBlockingQueue<>(100000), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread thread = new Thread(r);
thread.setName("CUSTOM_DAEMON_COMPLETABLEFUTURE");
thread.setDaemon(true);
return thread;
}
}, new ThreadPoolExecutor.CallerRunsPolicy());
List<CompletableFuture<Integer>> tasks = new ArrayList<>();
IntStream.rangeClosed(1, jobCount).forEach(value -> tasks.add(CompletableFuture.supplyAsync(CompleteableFuturePerfTest::getJob, threadPoolExecutor)));
long start = System.currentTimeMillis();
int sum = tasks.stream().map(CompletableFuture::join).mapToInt(Integer::intValue).sum();
checkSum(sum, jobCount);
return System.currentTimeMillis() - start;
}测试机器配置:8 核CPU,16G内存
性能测试结果:
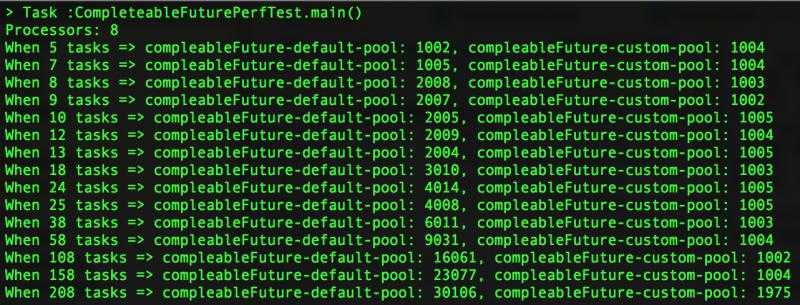
根据压测结果看到,随着压测任务数量越大,使用默认的线程池性能越差。
对象创建:
除前面提到的 supplyAsync 方法外,CompletableFuture 还提供了如下方法:
// 执行任务,CompletableFuture<Void> 无返回值,默认线程池
public static CompletableFuture<Void> runAsync(Runnable runnable) {
return asyncRunStage(asyncPool, runnable);
}
// 执行任务,CompletableFuture<Void> 无返回值,支持自定义线程池
public static CompletableFuture<Void> runAsync(Runnable runnable,
Executor executor) {
return asyncRunStage(screenExecutor(executor), runnable);
}我们在 CompletableFuture 模式实战中,提到了 CompletableFuture 实现了 CompletionStage 接口,该接口提供了非常丰富的功能。
CompletionStage 接口支持串行关系、汇聚 AND 关系、汇聚 OR 关系。
下面对这些关系的接口做个简单描述,大家在使用时可以去自行查阅 JDK API。
同时,这些关系接口中每个方法都提供了对应的 xxxAsync() 方法,表示异步化执行任务。
串行关系:
CompletionStage 描述串行关系,主要有 thenApply、thenRun、thenAccept 和 thenCompose 系列接口。
源码如下所示:
// 对应 U apply(T t) ,接收参数 T并支持返回值 U
public <U> CompletionStage<U> thenApply(Function<? super T,? extends U> fn);
public <U> CompletionStage<U> thenApplyAsync(Function<? super T,? extends U> fn);
// 不接收参数也不支持返回值
public CompletionStage<Void> thenRun(Runnable action);
public CompletionStage<Void> thenRunAsync(Runnable action);
// 接收参数但不支持返回值
public CompletionStage<Void> thenAccept(Consumer<? super T> action);
public CompletionStage<Void> thenAcceptAsync(Consumer<? super T> action);
// 组合两个依赖的 CompletableFuture 对象
public <U> CompletionStage<U> thenCompose
(Function<? super T, ? extends CompletionStage<U>> fn);
public <U> CompletionStage<U> thenComposeAsync
(Function<? super T, ? extends CompletionStage<U>> fn);汇聚 AND 关系:
CompletionStage 描述 汇聚 AND 关系,主要有 thenCombine、thenAcceptBoth 和 runAfterBoth 系列接口。
源码如下所示(省略了Async 方法):
// 当前和另外的 CompletableFuture 都完成时,两个参数传递给 fn,fn 有返回值
public <U,V> CompletionStage<V> thenCombine
(CompletionStage<? extends U> other,
BiFunction<? super T,? super U,? extends V> fn);
// 当前和另外的 CompletableFuture 都完成时,两个参数传递给 action,action 没有返回值
public <U> CompletionStage<Void> thenAcceptBoth
(CompletionStage<? extends U> other,
BiConsumer<? super T, ? super U> action);
// 当前和另外的 CompletableFuture 都完成时,执行 action
public CompletionStage<Void> runAfterBoth(CompletionStage<?> other,
Runnable action);汇聚 OR 关系:
CompletionStage 描述 汇聚 OR 关系,主要有 applyToEither、acceptEither 和 runAfterEither 系列接口。
源码如下所示(省略了Async 方法):
// 当前与另外的 CompletableFuture 任何一个执行完成,将其传递给 fn,支持返回值
public <U> CompletionStage<U> applyToEither
(CompletionStage<? extends T> other,
Function<? super T, U> fn);
// 当前与另外的 CompletableFuture 任何一个执行完成,将其传递给 action,不支持返回值
public CompletionStage<Void> acceptEither
(CompletionStage<? extends T> other,
Consumer<? super T> action);
// 当前与另外的 CompletableFuture 任何一个执行完成,直接执行 action
public CompletionStage<Void> runAfterEither(CompletionStage<?> other,
Runnable action);到此,CompletableFuture 的相关特性都介绍完了。
异步编程慢慢变得越来越成熟,Java 语言官网也开始支持异步编程模式,所以学好异步编程还是有必要的。
本文结合业务需求场景驱动,引出了 Future 设计模式实战,然后对 JDK1.8 中的 CompletableFuture 是如何使用的,核心优势、性能测试对比、使用扩展方面做了进一步剖析。
希望对大家有所帮助!
欢迎关注我的公众号,扫二维码关注解锁更多精彩文章,与你一同成长~

有了 CompletableFuture,使得异步编程没有那么难了!
标签:enable stc 表数 分配 工具类 提高 搜索 cpu 核数 screen
原文地址:https://www.cnblogs.com/ldws/p/11627139.html