标签:cnn info c99 拼接 自己 出现 exp att 定义
在三大特征提取器中,我们已经接触了LSTM/CNN/Transormer三种特征提取器,这一节我们将介绍如何使用BiLSTM实现序列标注中的命名实体识别任务,以及Lattice-LSTM的模型原理。
本文提到的模型在我的Github中均有相应代码实现(Lattice LSTM之后更新)
对于LSTM我就不再多做介绍了,想要了解的小伙伴可以看我之前的文章。BiLSTM就是双向LSTM,正向和反向提取句子信息,将正向和反向输出拼接在一起组成模型输出。
既然我们将BiLSTM看作特征提取器,意味着他的输出我们可以将其看作特征,作为另一个模型的输入来用。有了这种思想,我们将BiLSTM的输出输入一个简单的全连接神经网络就可以实现简单的分类了。
如果仅仅将BiLSTM最后全连接神经网络进行分类,这就意味着,每一个标签输出,只由上下文决定,即:
\[P(y_t|X, Y) = P(y_t|X)\]
但实际上,我们上一节了解到的,序列标注任务中,不同字的隐藏状态之间通常是由相互联系的,如之前提到的IOBES标注,标签S(单个实体),则其前后必定是标签O(非实体字),标签I(实体中间字),则其前后必定只会是I、B(实体开头字)、E(实体结尾字)。显然,这些信息是不会包含在上述模型中的。
为了能够考虑到隐藏状态之间的相互关系,上文介绍的CRF模型就能提供作用了。我们记得之前的CRF模型参数化条件概率定义如下:
\[P(y|x)=\frac{1}{Z}exp(\sum_j\sum_{i=1}^{n-1}\lambda_it_j(y_{i+1}, y_i, x, i)+ \sum_k\sum_{i=1}^{n}\mu_ks_k(y_i, x, i))\]
其中:
\(t_j(y_{i-1}, y_i, x, i)\)为局部特征函数,该特征由当前节点和上一个节点决定,称其为状态转移特征,用以描述相邻节点以及观测变量对当前状态的影响;
\(s_k(y_i, x, i)\)为节点特征函数,该特征函数只和当前节点有关,称其为状态特征;
\(\lambda\)和\(\mu\)是对应特征函数的参数。
实际上,特征函数\(t(·)\)就包含了我们之前提到的隐藏状态之间的相互关系,\(s(·)\)包含了观察变量的特征表示对相应隐藏状态的关系。之前我们提到过,将上述两个特征函数看作可学习参数的一部分,然后将其整合到状态转移矩阵中去了。在代码实现中,我们仅仅需要学习一个状态转移矩阵,就能实现一个完整的CRF,实际上,这个状态转移矩阵中,就包含了两个特征函数信息。CRF对LSTM信息的再利用,显然比一个简单的分类模型要强。
之前我们讨论的明明实体识别问题都是基于字的,主要是因为分词过程将引入很多误差来源,例如之前提到的OOV问题。但没有分词的过程使得基于字符的NER模型无法利用显性的词和词序信息来提取当前最有用的实体。如下图
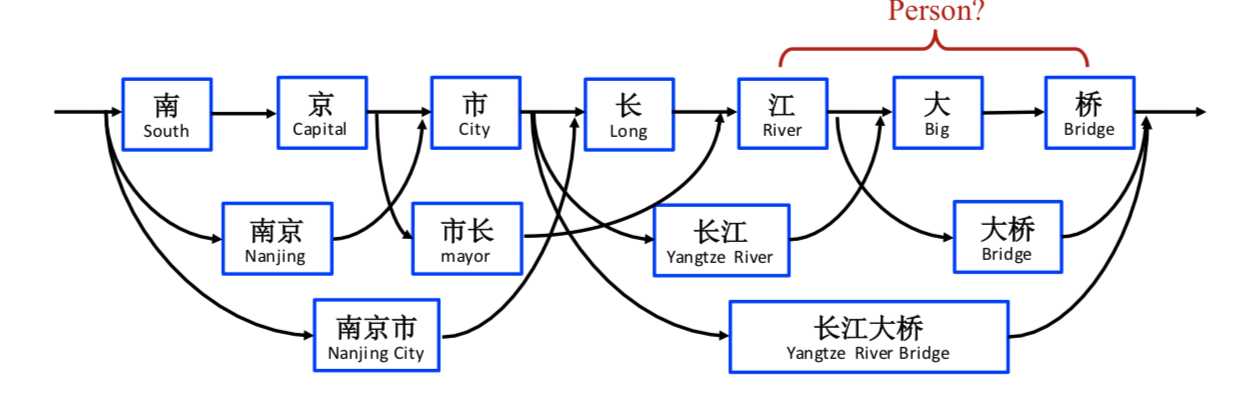
如果没有加入显性的词序信息,模型难以根据上下文判断该句应该识别出来地名“南京市/长江大桥”还是应该识别出人物“南京市长/江大桥”。Lattice LSTM的做法是构造一个潜在实体词典,当匹配到潜在实体出现的时候,将该潜在实体的信息输入到模型中辅助判断,从而实现潜在相关命名实体消歧。其大致模型结构如下图所示
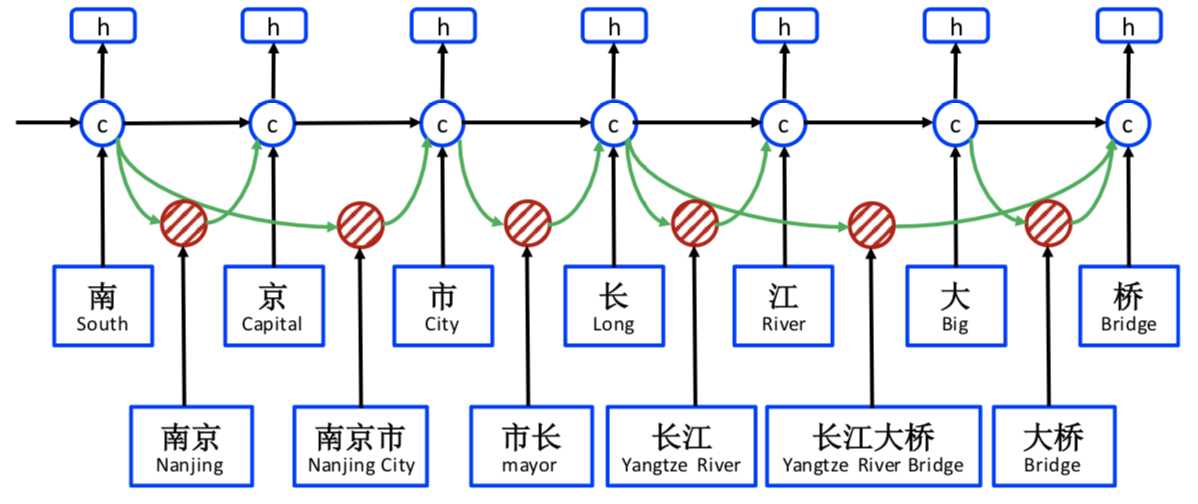
模型的细节可以参考官方给出的代码,之后我有时间再给出自己的实现。
参考链接
https://arxiv.org/pdf/1805.02023.pdf
https://www.jianshu.com/p/9c99796ff8d9
https://zhuanlan.zhihu.com/p/38941381
标签:cnn info c99 拼接 自己 出现 exp att 定义
原文地址:https://www.cnblogs.com/sandwichnlp/p/11630300.html