标签:com tail 存在 表示 十分 需要 存储空间 场景 运行时
参考博客:
双栈数据结构:
https://blog.csdn.net/hebtu666/article/details/83011115
https://blog.csdn.net/cainv89/article/details/51398148
双栈Ipv4/Ipv6实际应用场景: https://blog.csdn.net/chenycbbc0101/article/details/80228961
双栈(Dual Stack)
利用栈底位置相对不变的特性,可以让两个顺序栈共享一个空间。
具体实现方法大概有两种:
1. 一种是奇偶栈,就是所有下标为奇数的是一个栈,偶数是另一个栈。但是这样一个栈的最大存储就确定了,并没有起到互补空缺的作用,我们实现了也就没有太大意义。
2. 还有一种就是,栈底分别设在数组的头和尾。进栈往中间进就可以了。这样,整个数组存满了才会真的栈满。
这里我实现的是第二种栈底设在头尾的结构的双栈结构。
代码:
双栈结构体声明:
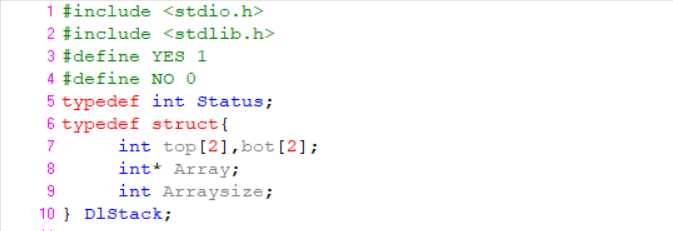
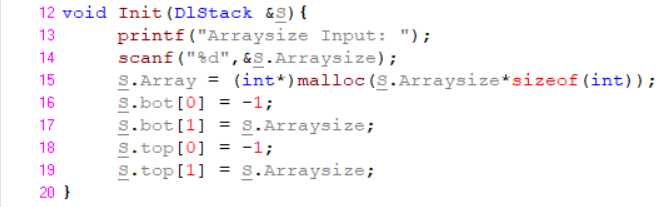
双栈初始化:
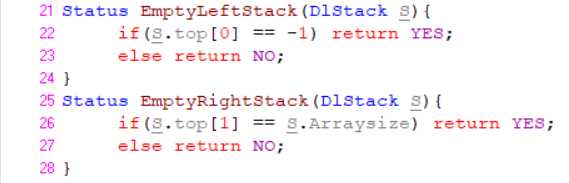
判断左右栈是否为空栈:
判断是否满栈:

元素入栈:

元素出栈:

双栈的优缺点
优点
两栈的大小不是固定不变的,在实际运算过程中,一个栈有可能进栈元素多而体积大些,另一个则可能小些。
两个栈共用一个栈空间,相互调剂,灵活性强。
缺点
运算较为复杂。
长度为定值,中途不易扩充。
注:n(n>2)个栈的情况更有所不同,采用多个栈共享栈空间的顺序存储表示方式,处理十分复杂,在插入时元素的移动量很大,因而时间代价较高。特别是当整个存储空间即将充满时,这个问题更加严重。
解决上述问题的办法就是采用链接方式作为栈的存储表示方式。
双栈的适用情况
当栈满时要发生溢出,为了避免这种情况,需要为栈设立一个足够大的空间。但如果空间设置得过大,而栈中实际只有几个元素,也是一种空间浪费。此外,程序中往往同时存在几个栈,因为各个栈所需的空间在运行中是动态变化着的。如果给几个栈分配同样大小的空间,可能实际运行时,有的栈膨胀得快,很快就产生了溢出,而其他的栈可能此时还有许多空闲空间。这时就可以利用双栈,两个栈共用一个栈空间,相互调剂,灵活性强。
标签:com tail 存在 表示 十分 需要 存储空间 场景 运行时
原文地址:https://www.cnblogs.com/Jenken-B/p/11632138.html