标签:地球 als 环境 tail 简单 文件中 代号 sdn 判断字符串
计算机发明之后需要使用0和1来表示字符,于是美国人在50年代发明了 ASCII (美国标准信息交换代码,American Standard Code for Information Interchange) 码。它由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成,每个字符占7位(1字节是8位)。比如 ‘a‘的 ASCII码10进制是97,二进制是 01100001。
ISOLatin-1(使用ASCII的文件不必有编码cookie,Latin-1仅当注释或文档字符串涉及作者名字需要Latin-1时才被使用)
可以认为ASCII是美国发明针对英语设计的,但欧洲人在用的时候出现了问题。对于一些特殊的拉丁字符,比如法文德文里某些字符,ASCII字符集就不包括。于是欧洲人发明了一种8位字符集是ISO 8859-1Latin 1,也简称为ISOLatin-1。它对ASCII做了个扩充,对于0-127之间的字符还使用ASCII里的字符不变, 把位于128-255之间的字符表示拉丁字母表中特殊语言字符。
后来计算机不断发展扩展到亚洲非洲,如何用计算机使用的二进制表示这些语言又成了问题。ISOLatin-1的8位字符集只能表示256个字符,而仅汉语就有80000以上个字符。如何把地球上绝大多数语言用一种编码方式表示出来呢? 于是发明了UNICODE编码,用2个字节(16位)以上编码地球上几乎所有地区的文字
但是,UNICODE只是理论上的编码方式,相当于给世界上每个文字打了个编号,但这编号具体如何在计算机里面存储,可以有多种实现方式。比如utf-8和gbk。
前面说了UNICODE只是给每个文字打了个编号,为啥不把这个编号直接转化成二进制存储在计算机里面呢? 比如英文字母`s`的编号是`115`, 用二进制表示是`00000000 1110011`, 中文`日`的编号是26085 (16进制是65e5) ,二进制是`11001011 1100101`。老外才没那么傻,对于老外这种日常纯粹是用英文字符的人来说明明之前1个字节就能存储一个字母,现在为了全球大一统非要存储为2个字节,相当于一个之前一个1M的文档,现在变为2M。于是老外耍了赖,英文字母`s`是`115`没错,但我就用1个字节`1110011`表示,而你中文`日`是`26085`号也没错,但是你不能在使用2个表示,而是用3个字节表示。(为了英文的特权,牺牲其他语言的存储空间的便利),这个编码方式就是UTF-8。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码。UTF-8用1到6个字节编码UNICODE字符。用在网页上可以同一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
那GBK又是如何产生的呢?
这时候中国人不干了,为啥你制定了全球大一统的规则,却为了自己的便利又破坏规则,连这点小便宜都不放过(典型的美国人作风)? 明明用2个字节就能表示中文一个汉字,现在UTF-8编码中文竟然需要2个甚至4个字节来表示。于是中国制定一套自己的规则,于是用2个字节来表示一个汉字,总共可以覆盖2万多个文字。 对于英文,好吧让一步,还保留和你UTF-8同样的方式使用一个字节来表示。
下图是把当前文章分别保存为 gbk 和 utf-8两种编码格式下文件大小的对比,表明用 gbk 确实省空间

记住:UNICODE只是给字符一个代号,而GBK和UTF-8使用不同的规则来表示同一个代号。
下面这个流程是我们写入文件到展示文件的简单描述:
乱码产生的根源就在与第2步骤和第4步。
在第2步保持文件时会把我们写入的文字使用编辑器默认的编码方式进行保存。如果大家使用的是vscode编辑器,默认的编码方式是utf-8。
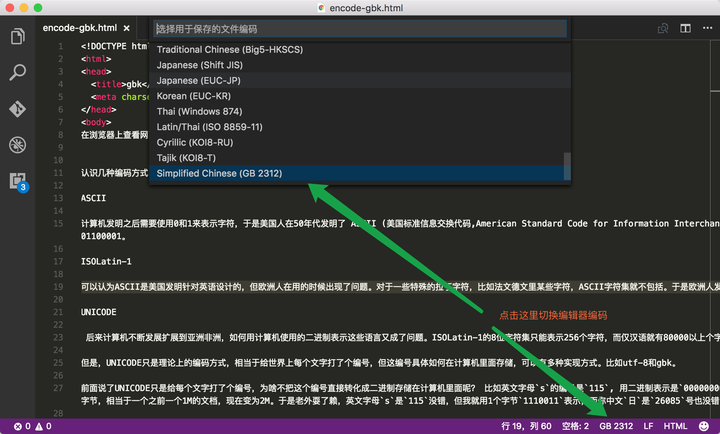
在第4步浏览器打开网页时,它并不知道你的这个文件是使用什么编码方式,于是自作主张使用了默认解码方式。如下图所示,文件保存为GBK格式,在Chrome打开时默认使用 ISO -8859的解码方式,导致编码和解码不匹配,产生乱码。
计算机内存中,统一使用Unicode编码,你在 .py 或者 .txt 键入文字的时候,计算机内存是以 Unicode 编码的方式对这些文字进行保存的。
编辑完成之后,保存的时候,再把 Unicode 编码转化为 UTF-8 保存的文件中。
另外流量网页的时候,服务器会把动态生成的 Unicode 内容,转化为 UTF-8 编码形式,再传输到浏览器,那么用户就可以看到自己能理解的语言组成的网页,比如中文、日文、韩文等等。很多网页的源代码上会有类似<meta charset=‘UTF-8‘ /> 的信息,表示该网页是 UTF-8 编码
python3 使用的是 Unicode 编码方式,也就意味着,python3 字符串支持多语言。虽然 python3 字符串类型在内存中以 Unicode 表示,但是在网络上传输或者保存到磁盘的时候,需要把 str 变为以字节为单位的 bytes。
encode() 方法
encode 方法以指定的编码格式编码字符串。返回编码后的字符串,是一个 bytes 对象。
str.encode(encoding=‘UTF-8‘,errors=‘strict‘)
encoding: 需要使用的编码,如 UTF-8,GBK
errors:可选参数,默认 strict,表示如果发生编码错误,返回一个 UnicodeError。
decode() 方法
decode 方法以指定的编码格式解码 bytes 对象,默认 UTF-8 编码,该方法返回解码后的字符串。
bytes.decode(encoding=‘UTF-8‘,errors=‘strict‘)
encoding:要使用的编码,UTF-8,GBK
error:可选参数,了解即可,默认 strict,可不写。
str = ‘我爱python‘ str_utf8 = str.encode(‘UTF-8‘) str_gbk = str.encode(‘GBK‘) print(str) print(‘str 对象类型:‘, type(str)) print(‘\r‘) print(‘UTF-8 编码:‘, str_utf8) print(‘str_utf-8 对象类型:‘, type(str_utf8)) print(‘\r‘) print(‘GBK 编码: ‘, str_gbk) print(‘str_gbk 对象类型:‘, type(str_gbk)) print(‘\r‘) print(‘UTF-8 解码:‘, str_utf8.decode(‘UTF-8‘, ‘strict‘)) print(‘GBK 解码: ‘, str_gbk.decode(‘GBK‘, ‘strict‘))
结果如下:
我爱python
str 对象类型: <class ‘str‘>
UTF-8 编码: b‘\xe6\x88\x91\xe7\x88\xb1python‘
str_utf-8 对象类型: <class ‘bytes‘>
GBK 编码: b‘\xce\xd2\xb0\xaepython‘
str_gbk 对象类型: <class ‘bytes‘>
UTF-8 解码: 我爱python
GBK 解码: 我爱python
python3 乱码
python3 内部使用 unicode 编码,外部面对各种各样乱七八糟的编码,中国最常用的是 gbk 和 utf-8。
在编辑 .py 的时候,python 默认会任务源代码文件是 ASCII 编码。如果代码只涉及的英文,那么转换没有问题,如果涉及到其他语言,比如中文,就会抛出异常。
解决方法很简单,在源码文件的前两行指定编码格式,网上有说一定放在前两行,放在第三行都不起作用。
# -*- coding: utf-8 -*-
如果在 windows 控制台运行代码,虽然程序执行了,但是屏幕上打印的不是中文,原因是 python 编码与控制台编码不一致。
Windows 控制台使用的是 gbk,而代码中使用的 utf-8,编码和解码的方式不一致,那么就不能正常的显示。
解决方法是将源码文件修改为:
# -*- coding: gbk -*-
或者另外一种方式,保持源码文件 utf-8 格式不变,在中文字符串前面添加 u 字母,表示后面的字符串以 unicode 格式存储。
a = ‘大师兄‘ b = u‘大师兄‘ print(a, type(a)) print(b, type(b)) 1 2 3 4
字符前面加 u 表明这是一个 unicode 对象,这个字会以 unicode 格式存在于内存中,而如果不加u 表明这仅仅是一个使用某种编码的字符串,编码格式取决于 python 对源码文件编码的识别。
Python 在向控制台输出 unicode 对象的时候会自动根据输出环境的编码进行转换,但如果输出的不是 unicode 对象而是普通字符串,则会直接按照字符串的编码输出字符串,从而出现乱码的现象。
decode函数也可以将一个普通字符串转换为unicode对象。
decode 将普通字符串按照参数中的编码格式进行解析,然后生成对应的 unicode 对象。
那么encode正好就是相反的功能,是将一个unicode对象转换为参数中编码格式的普通字符。
isinstance()
判断字符串是否是 unicode 的方法,python2 和 python3 略有不同,但是使用的都是 isinstance 方法。
# python2 isinstance(str, unicode) # python3 isinstance(str, str) 1 2 3 4 5
另外补充一个获取系统默认编码的方法
import sys print(sys.getdefaultencoding())
————————————————
引用:CSDN博主「Citizen_Wang」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/CityzenOldwang/article/details/78378775
标签:地球 als 环境 tail 简单 文件中 代号 sdn 判断字符串
原文地址:https://www.cnblogs.com/yanyanwang/p/11633109.html