标签:特定 验证 挖掘 接受 tab uri 图片 存储 抓取
? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中
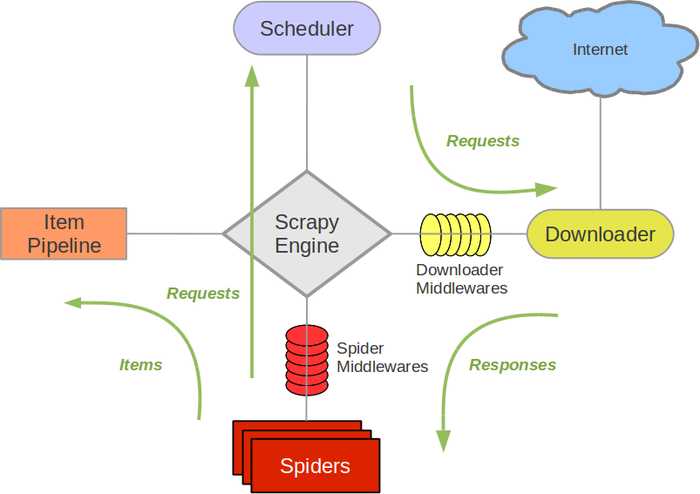
Scrapy主要包括了以下组件:
相关网站:https://scrapy-chs.readthedocs.io/zh_CN/stable/topics/architecture.html
Scrapy运行流程:
简化:
①引擎调用Spider中的start_request获取Request的一个实例化对象(通过Spider中间件),②引擎将Request的对象发送给调度器(通过调度器中间间),(引擎向调度器请求下一个Request对象并发送给调度器;重复①②),调度器会过滤掉重复的Request对象,加入到队列中,③将Request对象经过调度器中间件发送给引擎,④引擎通过下载中间件将Request对象交给下载器,下载器向互联网发送网络请求,⑤下载器把资源下载下来,并封装成响应包(Response)⑥下载器将Response对象(response)发送给引擎,⑦引擎将Response对象发送给Spider进行数据解析(如果解析得到url需要发送请求则回到①),将解析后的数据封装成Item发送给引擎,⑧引擎将(Spider返回的)爬取到的Item给ItemPipeline(管道),(process_item)进行持久化存储
标签:特定 验证 挖掘 接受 tab uri 图片 存储 抓取
原文地址:https://www.cnblogs.com/notfind/p/11636900.html