标签:信息 企业 添加 数字 电话 ret 修改 += 公司
本文代码及数据均来自于https://cuijiahua.com/blog/2017/11/ml_5_bayes_2.html
这个例子比较有实践意义,不仅使用了jieba、sklearn,并且其中用到的思想也是很实用的。
"结巴"中文分词:做最好的Python中文分词组件 "Jieba"
jieba有三种分词模式:全模式、精确模式和搜索引擎模式
示例:
#encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学",cut_all=True)
print "Full Mode:", "/ ".join(seg_list) #全模式
seg_list = jieba.cut("我来到北京清华大学",cut_all=False)
print "Default Mode:", "/ ".join(seg_list) #精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") #默认是精确模式
print ", ".join(seg_list)
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") #搜索引擎模式
print ", ".join(seg_list)输出:
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
【精确模式】: 我/ 来到/ 北京/ 清华大学
【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)
【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造本例来源:https://www.oschina.net/p/jieba
这里说的zip是Python中的一个函数,它将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表对象。
用法如下:
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]这里的zip起到的不是数据压缩作用,当然要是硬说也有压缩,两个对象压缩成一个了嘛,但是主要的功能是批量实现key:value,将变量之间的值一一对应。
with算是python中“省事”的一个典型了吧,托管了外部资源访问的异常处理、关闭等步骤
在with后面的代码块抛出异常时,exit()方法被执行。开发库时,清理资源,关闭文件等操作,都可以放在exit()方法中。
总之,with-as表达式极大的简化了每次写finally的工作,这对代码的优雅性是有极大帮助的。
如果有多项,可以这样写:With open(‘1.txt‘) as f1, open(‘2.txt‘) as f2:
do something如下代码:
file = open("1.txt") data = file.read() file.close()123上面代码存在2个问题:
(1)文件读取发生异常,但没有进行任何处理;
(2)可能忘记关闭文件句柄;改进
try: f = open('xxx') except: print('fail to open') exit(-1) try: do something except: do something finally: f.close()1234567891011虽然这段代码运行良好,但比较冗长。
而使用with的话,能够减少冗长,还能自动处理上下文环境产生的异常。如下面代码:with open("1.txt") as file: data = file.read()
原博主的算法是分布的,我也在jupyter notebook上写成了分布的形式,下面我粘贴上转换成的md文档,包括了源码、一小部分输出(太长了,影响阅读)、我加的一些注释
很长,大家做好准备
数据集已经准备好,接下来,让我们直接进入正题。切分中文语句,编写如下代码:
!下面这段代码在我的电脑上会宕机,就,恩,不运行了吧
# -*- coding: UTF-8 -*-
import os
import jieba
def TextProcessing(folder_path):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #训练集
class_list = []
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list)
class_list.append(folder)
j += 1
print(data_list)
print(class_list)
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
TextProcessing(folder_path)代码运行结果如下所示,可以看到,我们已经顺利将每个文本进行切分,并进行了类别标记。
我们将所有文本分成训练集和测试集,并对训练集中的所有单词进行词频统计,并按降序排序。也就是将出现次数多的词语在前,出现次数少的词语在后进行排序。编写代码如下:
# -*- coding: UTF-8 -*-
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
print(all_words_list)[',', '的', '\u3000', '。', '\n', ' ', ';', '&', 'nbsp', '、', '在', '了', '“', '”', '是', ':', '\x00', '和', '—', '也', '对', '就', '我', '有', '这', '上', '他', '将', '你', '不', '都', '要', '为', '中', '月', '而', '与', '自己', '一个', '中国', '(', ')', '可以', '年', '导弹', '日', ';', '从', '到', '大陆', '3', '公司', '考生', '等', '.', '人', '时', '火炮', '进行', ')', '(', '旅游', '说', '1', '台军', '会', '个', '没有', '游客', '能', '以', '把', '时间', '但', '认为', '多', '北京', '志愿', '让', '后', '还', '各种', '解放军', '《', '》', '5', '并', '被', '一种', '作战', '已经', '大', '小', '新', '地', '用', '做', '下', '很', '2', '成为', '前', '更', ',', '复习', '-', '大家', '[', ']', '企业', '来', '工作', '选择', '9', '4', '学校', '支付', '我们', '最', '如果', '远程', '…', '10', '这样', '问题', '美国', '去', '给', '可', '比赛', '又', '可能', '一定', '袁', '发展', '分析', '射程', '专业', '能力', '6', '主要', '技术', '着', '?', '!', '向', '考试', '建设', '部署', '完全', '一', '看', '很多', '黄金周', '辅导班', '五一', '因为', '他们', '通过', '使', '部分', '快', '文章', '基础', '2005', '电话', '过', '这些', '就是', '增长', '0', '毕业生', '出', '训练', '学习', '重要', '%', '钱', '分', '填报', '部队', '它', '提高', '时候', '作为', '品牌', '银行', '7', '开始', '计划', '好', '需要', '目前', '市场', 'VS', '接待', '军事', '阵地', '60', '8', ':', '比', '那些', '表现', '/', '坦克', '要求', '这个', '但是', '万人次', '用户', '由', '只有', '期间', '达到', '为了', '管理', '得', '一些', '16', '其中', '30', '科学', '比较', '几乎', '拥有', '网络', '相对', '影响', '最后', '提供', '不是', '其', '销售', '表示', '新浪', '活动', '资料', '情况', '已', '却', '所', '于', '所以', '阅读', '来源', '一旦', '她', '以上', '历史', '讲', '装备', '当', '必须', '系统', '还是', '里', '记者', '实验室', '人才', '题', '再', '考研', '则', '相关', '今年', '2006', '东莞', '该', '起', '专家', '这是', '压制', '对于', '重点', '知道', '词汇', '00', '们', '其他', '及', '上海', '招聘', 'MBA', '公里', '英语', '耿大勇', '参加', '现在', '根据', '由于', '注意', '应该', '第', '准备', '不用', '游戏', '距离', '或', '据', '11', 'A', '服务', '员工', '彻底', '手机', '大批', '岛屿', '阿里', '【', '】', '指挥', '方面', '孩子', '睡眠', '一家', '想', "'", '收入', '沿海', '力气', '摧毁', '图', '全军', '设计', '如', '建议', '什么', '平台', '一批', '机会', '了解', '香港', '不会', '同时', '置于', '全国', '大学生', '"', '数独', '数学', '挑衅', '角度', '20', '不能', '战场', '内', '利用', '才能', '许多', '而且', '还有', '不同', '然后', '地方', '老师', '家', '希望', '高']all_words_list就是将所有训练集的切分结果通过词频降序排列构成的单词合集。观察一下打印结果,不难发现,这里包含了很多标点符号,很显然,这些标点符号是不能作为新闻分类的特征的。总不能说,应为这个文章逗号多,所以它是xx类新闻吧?为了降低这些高频的符号对分类结果的影响,我们应该怎么做呢?答曰:抛弃他们! 除了这些,还有"在","了"这样对新闻分类无关痛痒的词。并且还有一些数字,数字显然也不能作为分类新闻的特征。所以要消除它们对分类结果的影响,我们可以定制一个规则。
一个简单的规则可以这样制定:首先去掉高频词,至于去掉多少个高频词,我们可以通过观察去掉高频词个数和最终检测准确率的关系来确定。除此之外,去除数字,不把数字作为分类特征。同时,去除一些特定的词语,比如:"的","一","在","不","当然","怎么"这类的对新闻分类无影响的介词、代词、连词。怎么去除这些词呢?可以使用已经整理好的stopwords_cn.txt文本。
为什么要去掉高频词?因为即使对于不同的文章,基础的词都是差不多的,我们要分辨的话应该是通过出现频率较少但是专业性也较强的词入手,而不是这些通用词,所以要把这些“高频且通用”的词去掉
所以我们可以根据这个文档,将这些单词去除,不作为分类的特征。我们取出前100个高频词汇,编写代码如下:
# -*- coding: UTF-8 -*-
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
"""
函数说明:读取文件里的内容,并去重
Parameters:
words_file - 文件路径
Returns:
words_set - 读取的内容的set集合
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def MakeWordsSet(words_file):
words_set = set() #创建set集合
with open(words_file, 'r', encoding = 'utf-8') as f: #打开文件
for line in f.readlines(): #一行一行读取
word = line.strip() #去回车
if len(word) > 0: #有文本,则添加到words_set中
words_set.add(word)
return words_set #返回处理结果
"""
函数说明:文本特征选取
Parameters:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 指定的结束语
Returns:
feature_words - 特征集
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def words_dict(all_words_list, deleteN, stopwords_set = set()):
feature_words = [] #特征列表
n = 1
#从deleteN开始读,这样就去掉高频词了,这是去词的第一步
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: #feature_words的维度为1000
break
#去除不符合要求的项
#如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
#isdigit可以判断一个字符或者字符串是不是数字
#大于1就保证了不会取到一些符号、特殊字符等,小于5是为了卡一些特殊情况
#这是去词的第二部
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
#生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
feature_words = words_dict(all_words_list, 100, stopwords_set)
print(feature_words)['支付', '工作', '目前', '选择', '仿制', '比赛', '成为', '时间', '发展', '主要', '黄金周', '美国', '远程', '可能', '建设', '品牌', '分析', '问题', '记者', '增长', '射程', '银行', '五一', '技术', '部署', '复习', '能力', '完全', '管理', '文章', '辅导班', '时候', '上海', '很多', '需要', '一定', '基础', '学习', '考试', '开始', '毕业生', '重要', '亿美元', '部队', '学校', '表示', '情况', '比较', '提高', '影响', '通过', 'VS', '现在', '表现', '部分', '阵地', '产品', '项目', '使用', '训练', '科学', '发现', '今年', '专家', '几乎', '相对', '资料', '设计', '拥有', '军事', '新浪', '希望', '要求', '最大', '必须', '坦克', '期间', '阅读', '这是', '方面', '应该', '人数', '最后', '印度', '实验室', '英语', '考研', '考古', '一次', '了解', '达到', '收入', '专业', '彻底', '万人次', '装备', '压制', '词汇', '专利', '公里', '参加', '活动', '一直', '一家', '知道', '距离', '作用', '日本', '网络', '角度', '耿大勇', '不用', '大批', '阿里', '岛屿', '计划', '准备', '机会', '国内', '重点', '全国', '销售', '力气', '非常', '接待', '指挥', '协议', 'MBA', '孩子', '沿海', '摧毁', '睡眠', '决定', '方式', '不能', '不同', '看到', '出现', '相关', '行业', '经济', '人才', '正在', '台湾', '建议', '新型', '全军', '挑衅', '置于', '获得', '提供', '不会', '全面', '大学', '招聘', '医院', '进入', '注意', '员工', '目标', '去年', '国家', '告诉', '平台', '战场', '发展观', '纳斯', '自寻死路', '世界领先', '型号', '开战', '金贵', '海量', '之内', '费多', '廉价', '左右', '考虑', '老师', '预期', '用户', '沈阳市', '药厂', '牛奶', '这种', '两个', '成功', '香港', '之后', '我国', '组织', '代表', '显示', '一下', '得到', '利用', '服务', '包括', '价值', '介绍', '军队', '喜欢', '止痛药', '消费者', '系统', '我军', '信息化', '东引岛', '研究', '增加', '知识', '顾客', '是否', '吸引', '武器', '电话', '实现', '语法', '句子', '理由', '赔偿', '分期付款', '未来', '最佳', '特别', '愿意', '结果', '本场', '镇痛药', '药物', '消费', '明显', '同比', '交易', '地方', '过程', '演练', '原因', '火力', '分钟', '写作', '对手', '营养', '辽宁队', '王治郅', '发布', '超过', '面对', '大量', '业务', '社会', '补充', '第一', '大学生', '努力', '领导', '事情', '参与', '连续', '上市', '一批', '景区', '小时', '历史', '帮助', '备考', '利苑', '学员', '认证', '数学', '詹姆斯', '埃及', '生活', '这次', '报道', '一起', '过去', '当时', '理解', '越来越', '水平', '领域', '数量', '不少', '关键', '一年', '产生', '不断', '加强', '发生', '实施', '最近', '患者', '全球', '休闲', '图库', '旅行社', '蓝军', '坚持', '不要', '来源', '今天', '经验', '各型', '客场', '免息', '感到', '姚明', '能够', '亿元', '关系', '调查', '环境', '稳定', '这家', '标志', '容易', '客户', '基本', '文化', '整个', '职业', '支持', '制药', '疼痛', '治疗', '刚刚', '关国光', '媒体', '其实', '条件', '掌握', '一样', '东莞', '复试', '统计', '教育', '推出', '医疗', '我省', '志愿', '伯德', '著名', '感受', '世界', '取得', '有限公司', '电子', '办法', '广东', '标准', '工程', '往往', '培养', '本报记者', '提升', '建立', '因素', '带来', '一场', '以下', '发挥', '投入']可以看到,我们已经滤除了那些没有用的词组,这个feature_words就是我们最终选出的用于新闻分类的特征。随后,我们就可以根据feature_words,将文本向量化,然后用于训练朴素贝叶斯分类器。这个向量化的思想和第三章的思想一致,因此不再累述。
了解了这些,我们就可以编写代码,通过观察取不同的去掉前deleteN个高频词的个数与最终检测准确率的关系,确定deleteN的取值:
# -*- coding: UTF-8 -*-
from sklearn.naive_bayes import MultinomialNB
import matplotlib.pyplot as plt
import os
import random
import jieba
"""
函数说明:中文文本处理
Parameters:
folder_path - 文本存放的路径
test_size - 测试集占比,默认占所有数据集的百分之20
Returns:
all_words_list - 按词频降序排序的训练集列表
train_data_list - 训练集列表
test_data_list - 测试集列表
train_class_list - 训练集标签列表
test_class_list - 测试集标签列表
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextProcessing(folder_path, test_size = 0.2):
folder_list = os.listdir(folder_path) #查看folder_path下的文件
data_list = [] #数据集数据
class_list = [] #数据集类别
#遍历每个子文件夹
for folder in folder_list:
new_folder_path = os.path.join(folder_path, folder) #根据子文件夹,生成新的路径
files = os.listdir(new_folder_path) #存放子文件夹下的txt文件的列表
j = 1
#遍历每个txt文件
for file in files:
if j > 100: #每类txt样本数最多100个
break
with open(os.path.join(new_folder_path, file), 'r', encoding = 'utf-8') as f: #打开txt文件
raw = f.read()
word_cut = jieba.cut(raw, cut_all = False) #精简模式,返回一个可迭代的generator
word_list = list(word_cut) #generator转换为list
data_list.append(word_list) #添加数据集数据
class_list.append(folder) #添加数据集类别
j += 1
data_class_list = list(zip(data_list, class_list)) #zip压缩合并,将数据与标签对应压缩
random.shuffle(data_class_list) #将data_class_list乱序
index = int(len(data_class_list) * test_size) + 1 #训练集和测试集切分的索引值
train_list = data_class_list[index:] #训练集
test_list = data_class_list[:index] #测试集
train_data_list, train_class_list = zip(*train_list) #训练集解压缩
test_data_list, test_class_list = zip(*test_list) #测试集解压缩
all_words_dict = {} #统计训练集词频
for word_list in train_data_list:
for word in word_list:
if word in all_words_dict.keys():
all_words_dict[word] += 1
else:
all_words_dict[word] = 1
#根据键的值倒序排序
all_words_tuple_list = sorted(all_words_dict.items(), key = lambda f:f[1], reverse = True)
all_words_list, all_words_nums = zip(*all_words_tuple_list) #解压缩
all_words_list = list(all_words_list) #转换成列表
return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list
"""
函数说明:读取文件里的内容,并去重
Parameters:
words_file - 文件路径
Returns:
words_set - 读取的内容的set集合
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def MakeWordsSet(words_file):
words_set = set() #创建set集合
with open(words_file, 'r', encoding = 'utf-8') as f: #打开文件
for line in f.readlines(): #一行一行读取
word = line.strip() #去回车
if len(word) > 0: #有文本,则添加到words_set中
words_set.add(word)
return words_set #返回处理结果
"""
函数说明:根据feature_words将文本向量化
Parameters:
train_data_list - 训练集
test_data_list - 测试集
feature_words - 特征集
Returns:
train_feature_list - 训练集向量化列表
test_feature_list - 测试集向量化列表
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def TextFeatures(train_data_list, test_data_list, feature_words):
def text_features(text, feature_words): #出现在特征集中,则置1
text_words = set(text)
features = [1 if word in text_words else 0 for word in feature_words]
return features
train_feature_list = [text_features(text, feature_words) for text in train_data_list]
test_feature_list = [text_features(text, feature_words) for text in test_data_list]
return train_feature_list, test_feature_list #返回结果
"""
函数说明:文本特征选取
Parameters:
all_words_list - 训练集所有文本列表
deleteN - 删除词频最高的deleteN个词
stopwords_set - 指定的结束语
Returns:
feature_words - 特征集
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
def words_dict(all_words_list, deleteN, stopwords_set = set()):
feature_words = [] #特征列表
n = 1
for t in range(deleteN, len(all_words_list), 1):
if n > 1000: #feature_words的维度为1000
break
#如果这个词不是数字,并且不是指定的结束语,并且单词长度大于1小于5,那么这个词就可以作为特征词
if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1 < len(all_words_list[t]) < 5:
feature_words.append(all_words_list[t])
n += 1
return feature_words
"""
函数说明:新闻分类器
Parameters:
train_feature_list - 训练集向量化的特征文本
test_feature_list - 测试集向量化的特征文本
train_class_list - 训练集分类标签
test_class_list - 测试集分类标签
Returns:
test_accuracy - 分类器精度
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-22
"""
#sklearn将朴素贝叶斯封装成了一个对象,通过MultinomialNB()调用,看下面的代码就能发现,和前面我们写的例子相比,最核心的部分只用了一行,并且只是简单的调用了端口,妙啊
#fit(训练集的特征列表,训练集的Label列表),返回一个训练好的分类器
#score(测试集的特征列表,测试集的label列表),返回分类准确率
def TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list):
#print(train_feature_list[0:10])
#通过上面这个打印命令,我们可以看到输入的也是01向量,而不是原本的数据。所以原理是通用的,只不过这里用sklearn替换了手动写的分类方法罢了
classifier = MultinomialNB().fit(train_feature_list, train_class_list)
test_accuracy = classifier.score(test_feature_list, test_class_list)
return test_accuracy
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
# 生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
test_accuracy_list = []
deleteNs = range(0, 1000, 20) #0 20 40 60 ... 980
for deleteN in deleteNs:
feature_words = words_dict(all_words_list, deleteN, stopwords_set)
train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)
test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)
test_accuracy_list.append(test_accuracy)
plt.figure()
plt.plot(deleteNs, test_accuracy_list)
plt.title('Relationship of deleteNs and test_accuracy')
plt.xlabel('deleteNs')
plt.ylabel('test_accuracy')
plt.show()[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]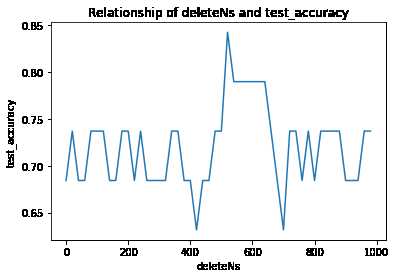
我们绘制出了deleteNs和test_accuracy的关系,这样我们就可以大致确定去掉前多少的高频词汇了。每次运行程序,绘制的图形可能不尽相同,我们可以通过多次测试,来决定这个deleteN的取值,然后确定这个参数,这样就可以顺利构建出用于新闻分类的朴素贝叶斯分类器了。我测试感觉450还不错,最差的分类准确率也可以达到百分之50以上。将if name == ‘main‘下的代码修改如下:
if __name__ == '__main__':
#文本预处理
folder_path = './SogouC/Sample' #训练集存放地址
all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = TextProcessing(folder_path, test_size=0.2)
# 生成stopwords_set
stopwords_file = './stopwords_cn.txt'
stopwords_set = MakeWordsSet(stopwords_file)
test_accuracy_list = []
feature_words = words_dict(all_words_list, 450, stopwords_set)
train_feature_list, test_feature_list = TextFeatures(train_data_list, test_data_list, feature_words)
test_accuracy = TextClassifier(train_feature_list, test_feature_list, train_class_list, test_class_list)
test_accuracy_list.append(test_accuracy)
ave = lambda c: sum(c) / len(c)
#ave 是一个匿名函数,我们将参数test_accuracy_list传入计算结果
print(ave(test_accuracy_list))标签:信息 企业 添加 数字 电话 ret 修改 += 公司
原文地址:https://www.cnblogs.com/jiading/p/11637027.html