标签:pen 流程图 最大 传送门 返回 onclick 下载 result 就是
特征(目的网站):简单,翻页结构,无反爬
特征(爬虫框架):极简,非分布式,无数据库
目的网站:
百度口碑医学教育网(https://koubei.baidu.com/s/med66.com?page=1&tab=comt)
爬取对象:
评论、时间、评分、内容以及评论人
爬虫框架:
极简框架(E):包括URL管理器,HTML下载器,HTML解析器,数据存储器(未使用数据库,包括结果输出,输出为html格式)以及爬虫调度器
运行流程图:
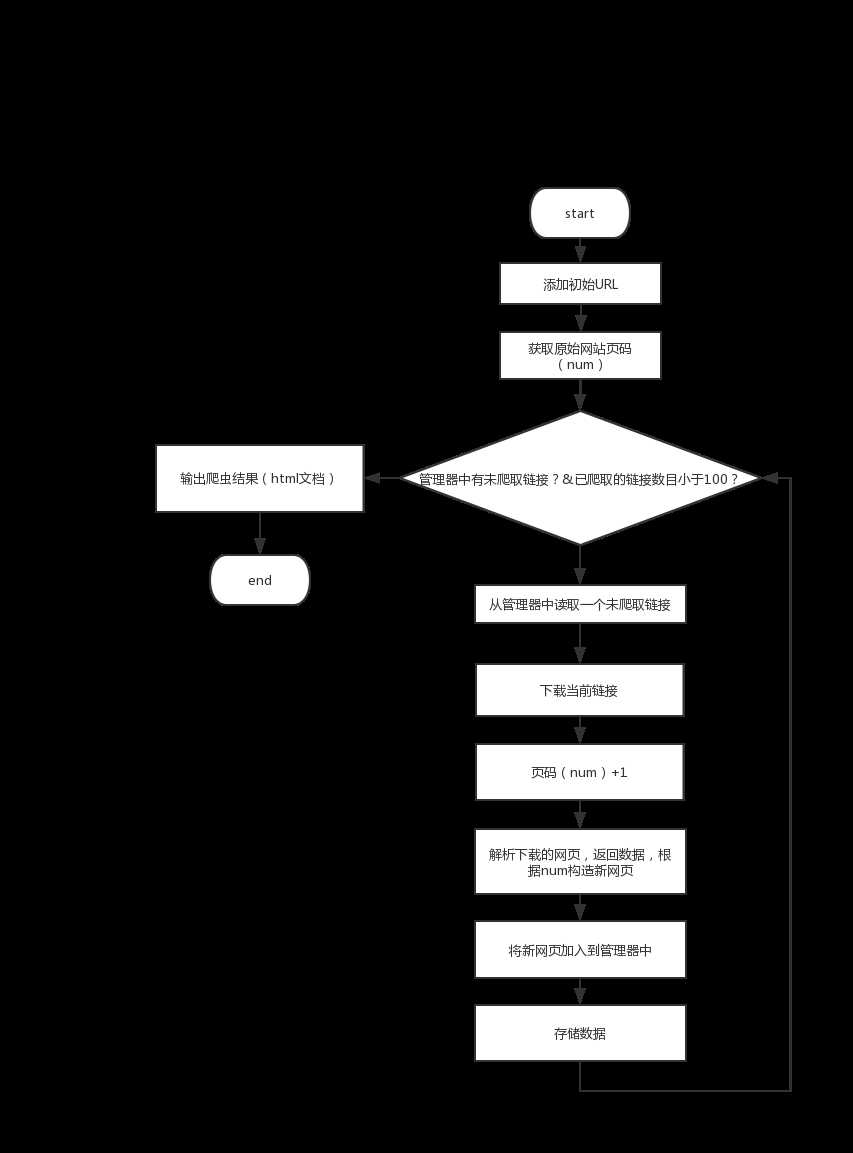
主要问题及思路:
网页解析:
1. 内容爬取
该网页解析较为简单,各个需要爬取的部分都有较为明显区分的标签,推荐先使用审查元素来找一下对应标 签,然后用查看源代码,利用Ctrl+F确定找出的标签是否完全对应所有的目的信息(不会多也 不会少)。唯一不同的是,评分不是标签里面的文本内容,而是在标签中的class属性中,其一般形式为"class = kb-i-small-star-X",X对应一个在0~5中取值(包括0和5)的数字。这个时候使用正则匹配找出其中代表评分的数字即可。对应的提取代码如下:

1 scores = soup.find_all(‘i‘, class_=re.compile(r‘kb-i-small-star-\d‘)) 2 if scores is None or len(scores) == 0: 3 data[‘score‘] = [‘无‘] 4 else: 5 for score in scores: 6 #评分在class属性里,需要提取 7 real_score = str(score[‘class‘]) 8 pattern = re.compile(r‘\d‘) 9 result = re.search(pattern, real_score) 10 score0.append(result.group()) 11 data[‘score‘] = score0
2. 新链接获取
目的是爬取该网站所有的评论、时间、评分、内容以及评论人,而源网址仅仅是其第一页的网址(网站可翻页)。无法直接从第一页的源码中获得其他页码的网址,需要另寻他法。此时注意到,每次翻页,网页URL变动都很小,如https://koubei.baidu.com/s/med66.com?page=1&tab=comt是第一页,翻到第二页时仅"page=1"变成了"page=2",于是想到了可以通过当前爬取网页构造下一个要爬取网页的URL,代码如下(来自HtmlParser.py):
1 def _get_new_urls(self, page_url, page_number): 2 new_urls = set() 3 link = ‘https://koubei.baidu.com/s/med66.com?page=%d&tab=comt‘ % page_number 4 new_urls.add(link) 5 return new_urls
在爬取上一个网页后,根据其页码数+1,构造下一个网址,爬一个加一个,直到循环结束。这是一个取巧的方法,不过应该也能应付一些简单网页。
内容输出:
1.输出文件格式
为html格式。
2.输出时遇到的问题
重点是这一段代码:
1 for data in self.datas: 2 for element in zip(data[‘time‘], data[‘score‘], data[‘user_name‘], data[‘comment‘]): 3 fout.write("<tr>") 4 fout.write("<td>%s<td/>" % data[‘url‘]) 5 fout.write("<td>%s<td/>" % element[0]) 6 fout.write("<td>%s<td/>" % element[1]) 7 fout.write("<td>%s<td/>" % element[2]) 8 fout.write("<td>%s<td/>" % element[3]) 9 fout.write("</tr>")
zip()函数值得一说,通过这个函数,将data[‘time‘], data[‘score‘], data[‘user_name‘], data[‘comment‘]四个列表并入一个循环,同时还能通过下表的方式输出四个列表相同下标的元素,使得输出非常方便。
可改进:
1. 对于通过页码构造新网址的办法,就本网页来说,尽管网站显示只有163页,但对于page=X,X大于163的URL也能返回结果(可能是服务器对page大于163的URL均定位到page163),且均为163页的结果。如果不是之前设置一次只爬一定数目的网站,这个问题将导致循环无法终止。同时,构造URL的方法是page+1,也就是说会对元URL对应的页码不断向后翻页,所以元URL必须是第一页(不过这个问题应该不是很难解决,但本次实验的框架实在太简单,后续估计不会使用,且一般不同网页的URL获取不会这么简单,所以没什么修改必要)。
2. 不知道是不是未使用数据库还是电脑的原因,本工程在爬取的过程中,爬取若干数量(数量不定,也可能有可能无)网址后就会卡住不动,所以github上的爬取结果是分两次爬的,且第二个文件内容有重复(将最大爬取数目限制在163就不会有了)。
源代码:#传送门#下的Easy_project项目。
标签:pen 流程图 最大 传送门 返回 onclick 下载 result 就是
原文地址:https://www.cnblogs.com/lk-mizi/p/11638323.html
