一、Jupyter notebook环境安装
1、Anaconda 以及 安装步骤
Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大(约 531 MB)。
下载地址:https://www.anaconda.com/distribution/
1)双击安装程序,如下图:
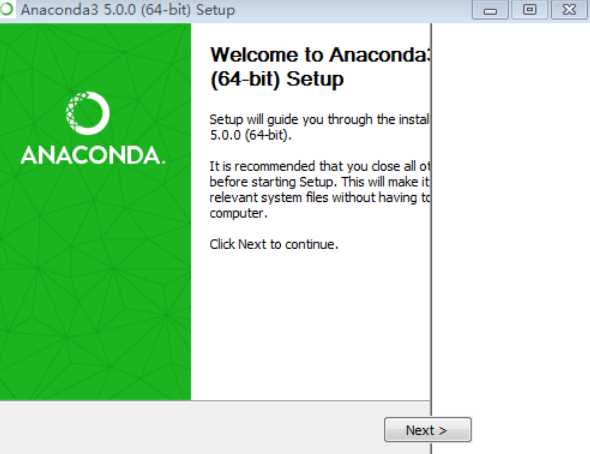
2)同意协议,如下图:
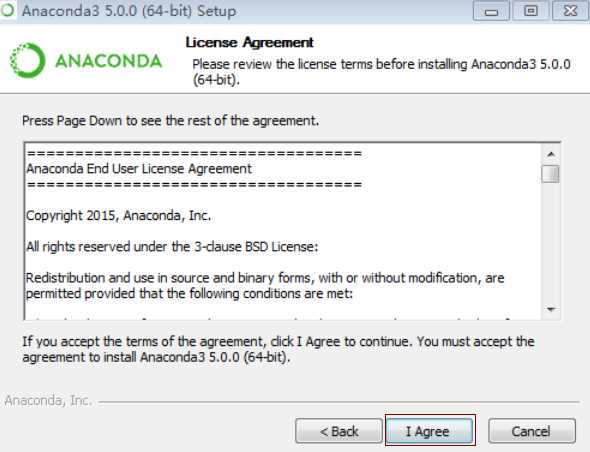
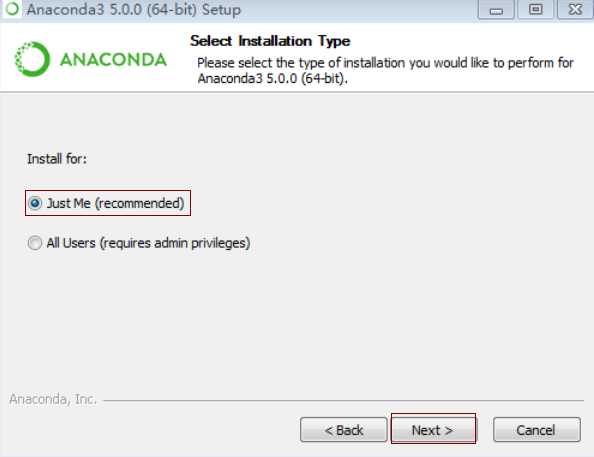
3)勾选"Just Me",即只为我这个用户安装。为所有用户(All Users)安装,要求有管理员权限,除非被要求以管理员权限安装,否则不要以管理员身份安装。
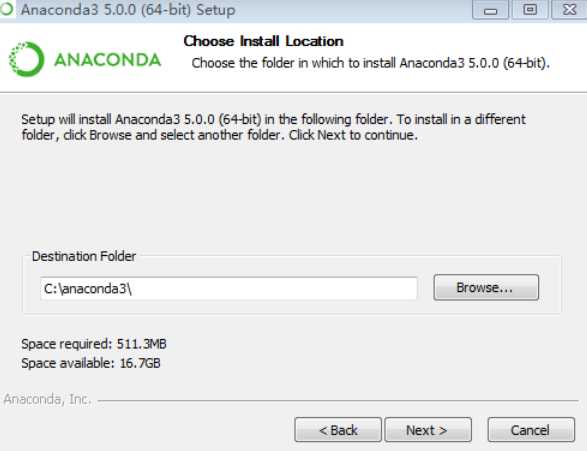
4)选择安装路径,注意,安装路径中不能有空格和中文。
5)添加环境变量
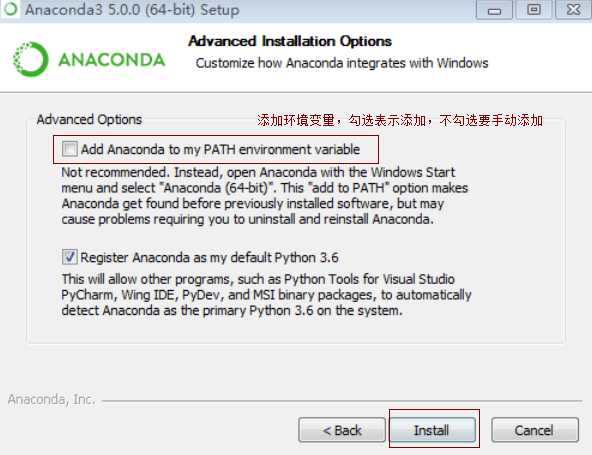
7)点击install开始安装,时间有点长,耐心等待
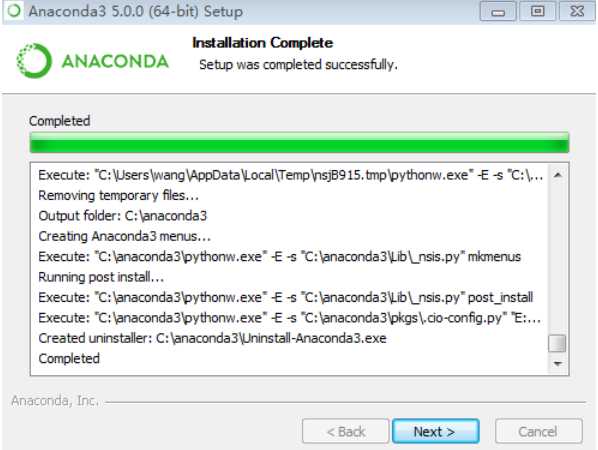
8)完成后点击next,如下图
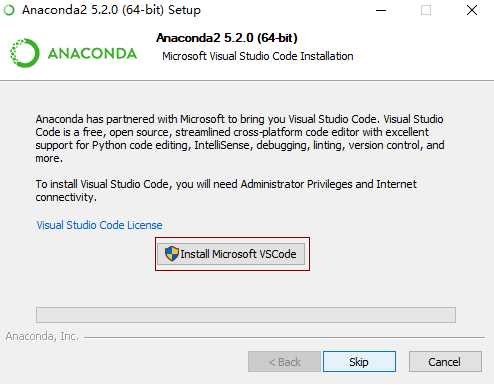
9)点击Install Microsoft VSCode,如下图
10)完成后点击next
11)全部完成后,点击Finish,两个选项不要勾选,如下图
12)配置环境变量
若上面安装过程中勾选了添加环境变量则可以跳过此步,若没有勾选则需要手动加,具体如下:
将安装目录anaconda3文件加入安装path;
将安装目录下的Scripts文件夹加入系统环境变量;
13)验证是否安装成功,找到安装程序,右击"Anaconda Prompt",选择"更多 - > 以管理员身份运行"
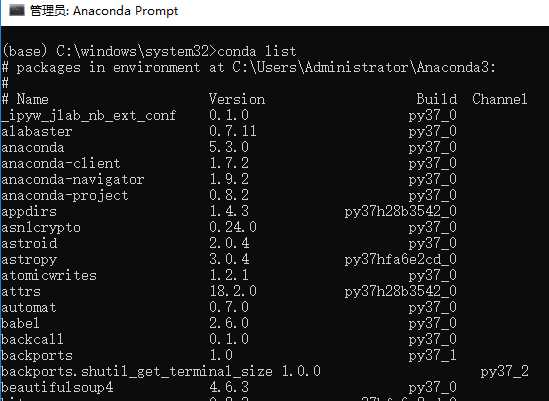
14)查看版本,输入conda list,可以查看已经安装的包名和版本号,如果结果可以正常显示,则说明安装成功,如下图
15)查看版本,如下图

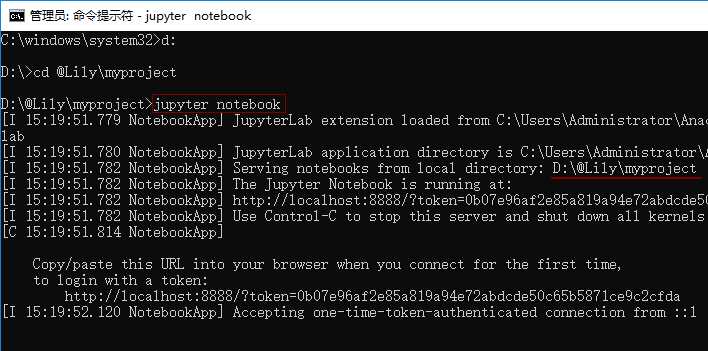
2、使用Jupyter Notebook
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行 40 多种编程语言。
Jupyter Notebook 有两种键盘输入模式。
- 编辑模式,允许你往单元中键入代码或文本;这时的单元框线是绿色的。
- 命令模式,键盘输入运行程序命令;这时的单元框线是灰色。
快捷键:
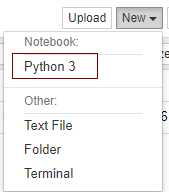
二、爬虫介绍
1、爬虫相关概念
爬虫:通过编写程序,模拟浏览器上网,然后让其去互联网爬取数据的过程。
爬虫的分类:
- 通用爬虫;即将一整张页面进行数据爬取,搜索引擎抓取系统
- 聚焦爬虫;即将网页中局部内容进行爬取,与通用爬虫有关系,要先进行通用爬虫
- 增量式;只爬取最新更新的数据,或者说只爬取没有爬取过的数据
反爬机制:对应的应用载体是门户网站。
反反爬策略:对应的应用载体是爬虫程序。
robots.txt协议:我们遇到的第一个反爬机制(https://www.taobao.com/robots.txt),遵从或者不遵从,一个防君子,不妨小人的协议。
参考博客:https://www.cnblogs.com/bobo-zhang/p/9645024.html
2、回顾http/https
参考博客:https://www.cnblogs.com/bobo-zhang/p/9645715.html
3、抓包工具fiddler安装和配置
Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的进出Fiddler的数据。 Fiddler 要比其他的网络调试器要更加简单,因为它不仅仅暴露http通讯还提供了一个用户友好的格式。
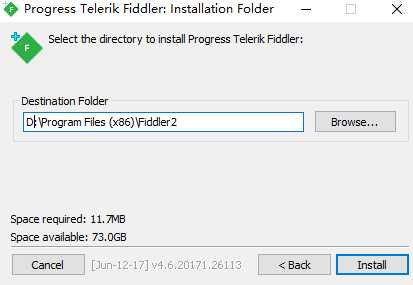
1)双击安装程序,选择安装路径,如下图
2)安装完成后关闭窗口,找到程序

3)打开程序,点击"是"
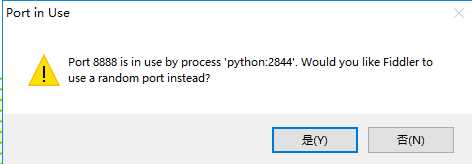
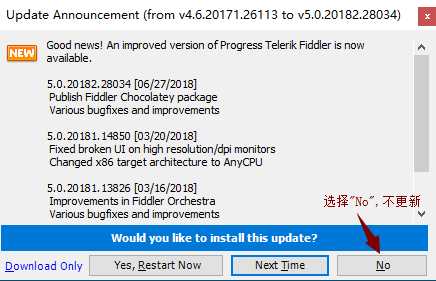
4)是否更新提示弹框,选择"No",如下图
5)点击菜单的"Tools -> Options",如下图
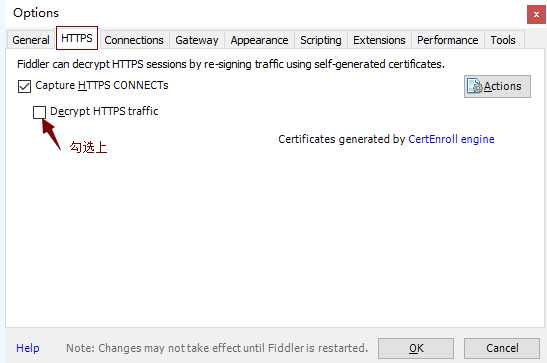
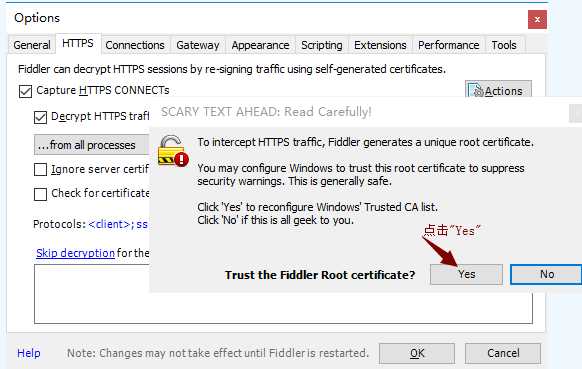
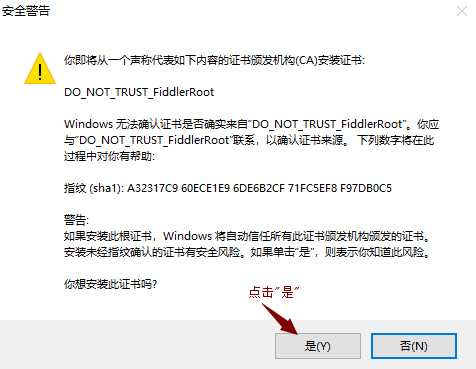
6)安装证书,如下图
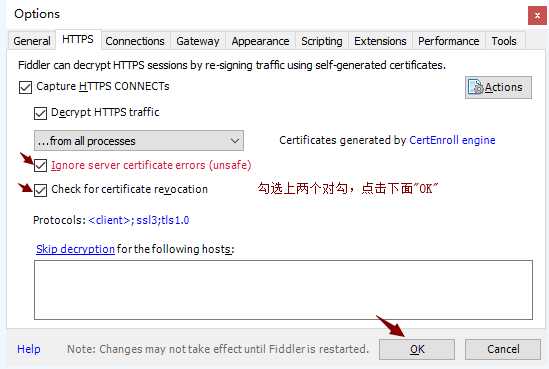
7)重启fiddler,清楚记录,我们可以在fiddler中查看,我们主要使用以下几个部分
4、requests模块
参考博客:https://www.cnblogs.com/bobo-zhang/p/9680561.html
参考博客:https://www.cnblogs.com/bobo-zhang/p/9680673.html