标签:speed regular 预测 beta set enum 代码 object init
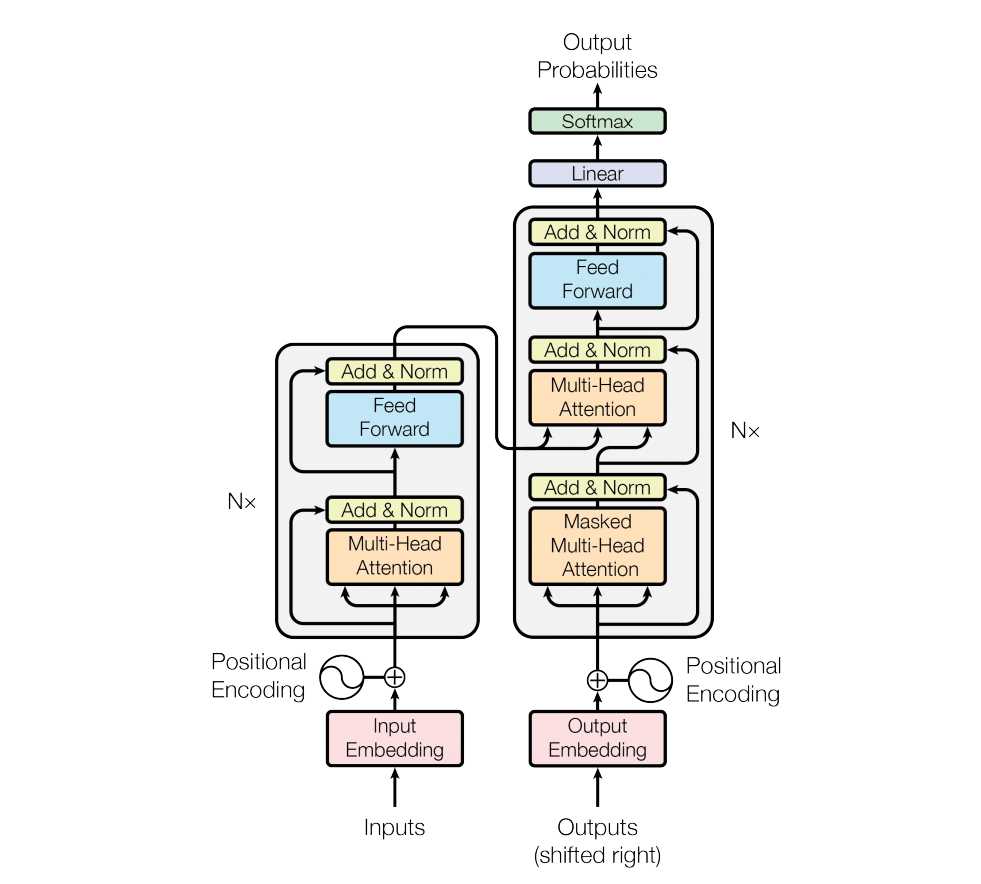
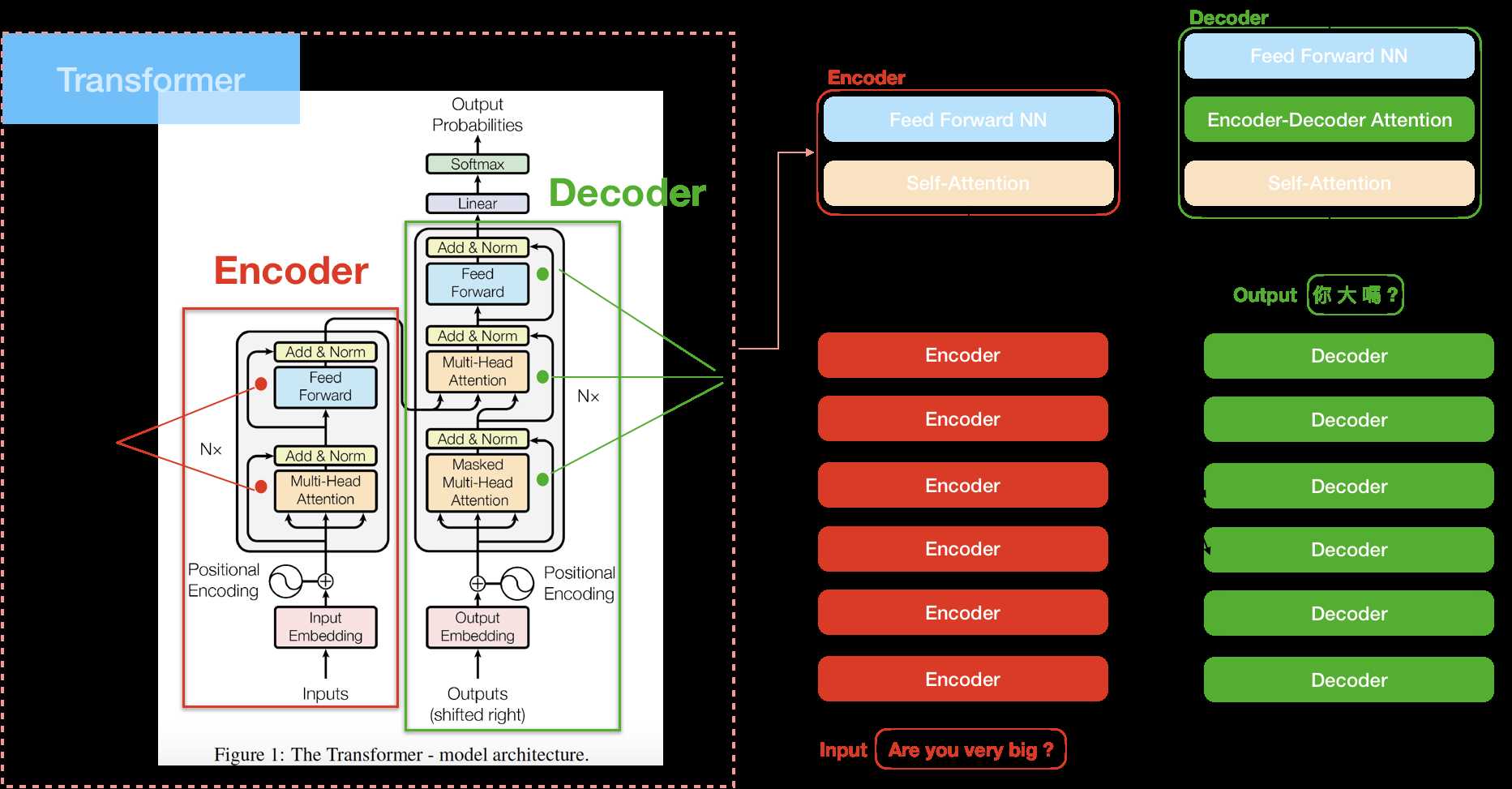
实现细节;
1.embedding 层
2.positional encoding层:添加位置信息
3,MultiHeadAttention层:encoder的self attention
4,sublayerConnection层:add&norm,使用layerNorm,
5,FeedForward层:两层全连接
6,Masked MultiHeadAttention:decoder中的self attention层,添加mask,不考虑计算当前位置的后面信息
7,MultiHeadAttention层:encoder的输出做key,value,decoder的self attention输出做query,类似于传统attention
8,generator层:最后的linear和softmax层,转为概率输出
9,预测时greedy_decode,第一个预测初始化为start字符
1 #!/usr/bin/env python 2 # coding: utf-8 3 4 import numpy as np 5 import torch 6 import torch.nn as nn 7 import torch.nn.functional as F 8 import math 9 import copy 10 import time 11 from torch.autograd import Variable 12 import matplotlib.pyplot as plt 13 import seaborn 14 seaborn.set_context(context="talk") 15 16 17 class EncoderDecoder(nn.Module): 18 """ 19 A standard Encoder-Decoder architecture. Base for this and many 20 other models. 21 """ 22 23 def __init__(self, encoder, decoder, src_embed, tgt_embed, generator): 24 super(EncoderDecoder, self).__init__() 25 self.encoder = encoder 26 self.decoder = decoder 27 self.src_embed = src_embed 28 self.tgt_embed = tgt_embed 29 self.generator = generator 30 31 def forward(self, src, tgt, src_mask, tgt_mask): 32 "Take in and process masked src and target sequences." 33 memory = self.encode(src, src_mask) 34 ret = self.decode(memory, src_mask, tgt, tgt_mask) 35 return ret 36 37 def encode(self, src, src_mask): 38 src_embedding = self.src_embed(src) 39 ret = self.encoder(src_embedding, src_mask) 40 return ret 41 42 def decode(self, memory, src_mask, tgt, tgt_mask): 43 ret = tgt_embdding = self.tgt_embed(tgt) 44 self.decoder(tgt_embdding, memory, src_mask, tgt_mask) 45 return ret 46 47 48 class Generator(nn.Module): 49 "Define standard linear + softmax generation step." 50 51 def __init__(self, d_model, vocab): 52 super(Generator, self).__init__() 53 self.proj = nn.Linear(d_model, vocab) 54 55 def forward(self, x): 56 return F.log_softmax(self.proj(x), dim=-1) 57 58 59 # The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 1, respectively. 60 61 # ## Encoder and Decoder Stacks 62 # ### Encoder 63 # The encoder is composed of a stack of $N=6$ identical layers. 64 def clones(module, N): 65 "Produce N identical layers." 66 return nn.ModuleList([copy.deepcopy(module) for _ in range(N)]) 67 68 69 class Encoder(nn.Module): 70 "Core encoder is a stack of N layers" 71 72 def __init__(self, layer, N): 73 super(Encoder, self).__init__() 74 self.layers = clones(layer, N) 75 self.norm = LayerNorm(layer.size) 76 77 def forward(self, x, mask): 78 "Pass the input (and mask) through each layer in turn." 79 for layer in self.layers: 80 x = layer(x, mask) 81 return self.norm(x) 82 83 84 #layer normalization [(cite)](https://arxiv.org/abs/1607.06450). do on 85 class LayerNorm(nn.Module): 86 "Construct a layernorm module (See citation for details)." 87 def __init__(self, features, eps=1e-6): 88 super(LayerNorm, self).__init__() 89 self.a_2 = nn.Parameter(torch.ones(features)) 90 self.b_2 = nn.Parameter(torch.zeros(features)) 91 self.eps = eps 92 93 def forward(self, x): 94 mean = x.mean(-1, keepdim=True) 95 std = x.std(-1, keepdim=True) 96 return self.a_2 * (x - mean) / (std + self.eps) + self.b_2 97 98 99 # That is, the output of each sub-layer is $\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))$, where $\mathrm{Sublayer}(x)$ is the function implemented by the sub-layer itself. We apply dropout [(cite)](http://jmlr.org/papers/v15/srivastava14a.html) to the output of each sub-layer, before it is added to the sub-layer input and normalized. 100 # To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension $d_{\text{model}}=512$. 101 class SublayerConnection(nn.Module): 102 """ 103 A residual connection followed by a layer norm. 104 Note for code simplicity the norm is first as opposed to last. 105 """ 106 107 def __init__(self, size, dropout): 108 super(SublayerConnection, self).__init__() 109 self.norm = LayerNorm(size) 110 self.dropout = nn.Dropout(dropout) 111 112 def forward(self, x, sublayer): 113 "Apply residual connection to any sublayer with the same size." 114 ret = x + self.dropout(sublayer(self.norm(x))) 115 return ret 116 117 118 # Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. 119 class EncoderLayer(nn.Module): 120 "Encoder is made up of self-attn and feed forward (defined below)" 121 122 def __init__(self, size, self_attn, feed_forward, dropout): 123 super(EncoderLayer, self).__init__() 124 self.self_attn = self_attn 125 self.feed_forward = feed_forward 126 self.sublayer = clones(SublayerConnection(size, dropout), 2) 127 self.size = size 128 129 def forward(self, x, mask): 130 "Follow Figure 1 (left) for connections." 131 x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) 132 # torch.Size([30, 10, 512]) 133 ret = self.sublayer[1](x, self.feed_forward) 134 return ret 135 136 137 # ### Decoder 138 # The decoder is also composed of a stack of $N=6$ identical layers. 139 class Decoder(nn.Module): 140 "Generic N layer decoder with masking." 141 142 def __init__(self, layer, N): 143 super(Decoder, self).__init__() 144 self.layers = clones(layer, N) 145 self.norm = LayerNorm(layer.size) 146 147 def forward(self, x, memory, src_mask, tgt_mask): 148 for layer in self.layers: 149 x = layer(x, memory, src_mask, tgt_mask) 150 return self.norm(x) 151 152 153 # In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. 154 class DecoderLayer(nn.Module): 155 "Decoder is made of self-attn, src-attn, and feed forward (defined below)" 156 157 def __init__(self, size, self_attn, src_attn, feed_forward, dropout): 158 super(DecoderLayer, self).__init__() 159 self.size = size 160 self.self_attn = self_attn 161 self.src_attn = src_attn 162 self.feed_forward = feed_forward 163 self.sublayer = clones(SublayerConnection(size, dropout), 3) 164 165 def forward(self, x, memory, src_mask, tgt_mask): 166 "Follow Figure 1 (right) for connections." 167 m = memory 168 x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) 169 x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) 170 return self.sublayer[2](x, self.feed_forward) 171 172 173 # ### Attention 174 # An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. 175 # We call our particular attention "Scaled Dot-Product Attention". The input consists of queries and keys of dimension $d_k$, and values of dimension $d_v$. We compute the dot products of the query with all keys, divide each by $\sqrt{d_k}$, and apply a softmax function to obtain the weights on the values. 176 def attention(query, key, value, mask=None, dropout=None): 177 "Compute ‘Scaled Dot Product Attention‘" 178 # query,key,value:torch.Size([30, 8, 10, 64]) 179 # decoder mask:torch.Size([30, 1, 9, 9]) 180 d_k = query.size(-1) 181 key_ = key.transpose(-2, -1) # torch.Size([30, 8, 64, 10]) 182 # torch.Size([30, 8, 10, 10]) 183 scores = torch.matmul(query, key_) / math.sqrt(d_k) 184 if mask is not None: 185 # decoder scores:torch.Size([30, 8, 9, 9]), 186 scores = scores.masked_fill(mask == 0, -1e9) 187 p_attn = F.softmax(scores, dim=-1) 188 if dropout is not None: 189 p_attn = dropout(p_attn) 190 return torch.matmul(p_attn, value), p_attn 191 192 193 class MultiHeadedAttention(nn.Module): 194 def __init__(self, h, d_model, dropout=0.1): 195 "Take in model size and number of heads." 196 super(MultiHeadedAttention, self).__init__() 197 assert d_model % h == 0 198 # We assume d_v always equals d_k 199 self.d_k = d_model // h # 64=512//8 200 self.h = h 201 self.linears = clones(nn.Linear(d_model, d_model), 4) 202 self.attn = None 203 self.dropout = nn.Dropout(p=dropout) 204 205 def forward(self, query, key, value, mask=None): 206 # query,key,value:torch.Size([30, 10, 512]) 207 if mask is not None: 208 # Same mask applied to all h heads. 209 mask = mask.unsqueeze(1) 210 nbatches = query.size(0) 211 # 1) Do all the linear projections in batch from d_model => h x d_k 212 query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) 213 for l, x in zip(self.linears, (query, key, value))] # query,key,value:torch.Size([30, 8, 10, 64]) 214 # 2) Apply attention on all the projected vectors in batch. 215 x, self.attn = attention(query, key, value, mask=mask, 216 dropout=self.dropout) 217 # 3) "Concat" using a view and apply a final linear. 218 x = x.transpose(1, 2).contiguous().view( 219 nbatches, -1, self.h * self.d_k) 220 ret = self.linears[-1](x) # torch.Size([30, 10, 512]) 221 return ret 222 223 224 # ### Applications of Attention in our Model 225 # The Transformer uses multi-head attention in three different ways: 226 # 1) In "encoder-decoder attention" layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models such as [(cite)](https://arxiv.org/abs/1609.08144). 227 # 2) The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder. 228 # 3) Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out (setting to $-\infty$) all values in the input of the softmax which correspond to illegal connections. 229 # ## Position-wise Feed-Forward Networks 230 class PositionwiseFeedForward(nn.Module): 231 "Implements FFN equation." 232 233 def __init__(self, d_model, d_ff, dropout=0.1): 234 super(PositionwiseFeedForward, self).__init__() 235 self.w_1 = nn.Linear(d_model, d_ff) 236 self.w_2 = nn.Linear(d_ff, d_model) 237 self.dropout = nn.Dropout(dropout) 238 239 def forward(self, x): 240 return self.w_2(self.dropout(F.relu(self.w_1(x)))) 241 242 243 # ## Embeddings and Softmax 244 # Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension $d_{\text{model}}$. We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [(cite)](https://arxiv.org/abs/1608.05859). In the embedding layers, we multiply those weights by $\sqrt{d_{\text{model}}}$. 245 class Embeddings(nn.Module): 246 def __init__(self, d_model, vocab): 247 super(Embeddings, self).__init__() 248 self.lut = nn.Embedding(vocab, d_model) # Embedding(11, 512) 249 self.d_model = d_model 250 251 def forward(self, x): 252 return self.lut(x) * math.sqrt(self.d_model) 253 254 255 # ## Positional Encoding 256 class PositionalEncoding(nn.Module): 257 "Implement the PE function." 258 259 def __init__(self, d_model, dropout, max_len=5000): 260 super(PositionalEncoding, self).__init__() 261 self.dropout = nn.Dropout(p=dropout) 262 263 # Compute the positional encodings once in log space. 264 pe = torch.zeros(max_len, d_model) 265 position = torch.arange(0., max_len).unsqueeze(1) 266 div_term = torch.exp(torch.arange(0., d_model, 2) 267 * -(math.log(10000.0) / d_model)) 268 269 pe[:, 0::2] = torch.sin(position * div_term) 270 pe[:, 1::2] = torch.cos(position * div_term) 271 pe = pe.unsqueeze(0) 272 self.register_buffer(‘pe‘, pe) 273 274 def forward(self, x): 275 x = x + Variable(self.pe[:, :x.size(1)], 276 requires_grad=False) 277 return self.dropout(x) 278 279 280 # We also experimented with using learned positional embeddings [(cite)](https://arxiv.org/pdf/1705.03122.pdf) instead, and found that the two versions produced nearly identical results. We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training. 281 # ## Full Model 282 def make_model(src_vocab, tgt_vocab, N=6, 283 d_model=512, d_ff=2048, h=8, dropout=0.1): 284 "Helper: Construct a model from hyperparameters." 285 c = copy.deepcopy 286 attn = MultiHeadedAttention(h, d_model) 287 ff = PositionwiseFeedForward(d_model, d_ff, dropout) 288 position = PositionalEncoding(d_model, dropout) 289 model = EncoderDecoder( 290 Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), 291 Decoder(DecoderLayer(d_model, c(attn), c(attn), 292 c(ff), dropout), N), 293 nn.Sequential(Embeddings(d_model, src_vocab), c(position)), 294 nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)), 295 Generator(d_model, tgt_vocab)) 296 297 # This was important from their code. 298 # Initialize parameters with Glorot / fan_avg. 299 for p in model.parameters(): 300 if p.dim() > 1: 301 nn.init.xavier_uniform_(p) 302 return model 303 304 # We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position $i$ can depend only on the known outputs at positions less than $i$. 305 306 307 def subsequent_mask(size): 308 "Mask out subsequent positions when decoding." 309 attn_shape = (1, size, size) 310 subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype(‘uint8‘) 311 return torch.from_numpy(subsequent_mask) == 0 312 313 # # Training 314 # This section describes the training regime for our models. 315 # > We stop for a quick interlude to introduce some of the tools 316 # needed to train a standard encoder decoder model. First we define a batch object that holds the src and target sentences for training, as well as constructing the masks. 317 # ## Batches and Masking 318 319 320 class Batch: 321 "Object for holding a batch of data with mask during training." 322 323 def __init__(self, src, trg=None, pad=0): 324 self.src = src 325 self.src_mask = (src != pad).unsqueeze(-2) 326 if trg is not None: 327 self.trg = trg[:, :-1] 328 self.trg_y = trg[:, 1:] 329 self.trg_mask = self.make_std_mask(self.trg, pad) 330 self.ntokens = (self.trg_y != pad).data.sum() 331 332 @staticmethod 333 def make_std_mask(tgt, pad): 334 "Create a mask to hide padding and future words." 335 tgt_mask = (tgt != pad).unsqueeze(-2) 336 tgt_mask = tgt_mask & Variable( 337 subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data)) 338 return tgt_mask 339 340 # Next we create a generic training and scoring function to keep track of loss. We pass in a generic loss compute function that also handles parameter updates. 341 def run_epoch(data_iter, model, loss_compute): 342 "Standard Training and Logging Function" 343 start = time.time() 344 total_tokens = 0 345 total_loss = 0 346 tokens = 0 347 for i, batch in enumerate(data_iter): 348 out = model.forward(batch.src, batch.trg, 349 batch.src_mask, batch.trg_mask)#torch.Size([30, 10]),torch.Size([30, 9]),torch.Size([30, 1, 10]),torch.Size([30, 9, 9]) 350 351 352 loss = loss_compute(out, batch.trg_y, batch.ntokens) 353 total_loss += loss 354 total_tokens += batch.ntokens 355 tokens += batch.ntokens 356 if i % 50 == 1: 357 elapsed = time.time() - start 358 print("Step: %d Loss: %f" % 359 (i, loss / batch.ntokens)) 360 start = time.time() 361 tokens = 0 362 363 return total_loss / total_tokens 364 365 366 # ## Optimizer 367 class NoamOpt: 368 "Optim wrapper that implements rate." 369 def __init__(self, model_size, factor, warmup, optimizer): 370 self.optimizer = optimizer 371 self._step = 0 372 self.warmup = warmup 373 self.factor = factor 374 self.model_size = model_size 375 self._rate = 0 376 377 def step(self): 378 "Update parameters and rate" 379 self._step += 1 380 rate = self.rate() 381 for p in self.optimizer.param_groups: 382 p[‘lr‘] = rate 383 self._rate = rate 384 self.optimizer.step() 385 386 def rate(self, step = None): 387 "Implement `lrate` above" 388 if step is None: 389 step = self._step 390 return self.factor *(self.model_size ** (-0.5) *min(step ** (-0.5), step * self.warmup ** (-1.5))) 391 392 def get_std_opt(model): 393 return NoamOpt(model.src_embed[0].d_model, 2, 4000, 394 torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)) 395 # Three settings of the lrate hyperparameters. 396 opts = [NoamOpt(512, 1, 4000, None), 397 NoamOpt(512, 1, 8000, None), 398 NoamOpt(256, 1, 4000, None)] 399 400 # ## Regularization 401 # ### Label Smoothing 402 # During training, we employed label smoothing . This hurts perplexity, as the model learns to be more unsure, but improves accuracy and BLEU score. 403 class LabelSmoothing(nn.Module): 404 "Implement label smoothing." 405 def __init__(self, size, padding_idx, smoothing=0.0): 406 super(LabelSmoothing, self).__init__() 407 self.criterion = nn.KLDivLoss(size_average=False) 408 self.padding_idx = padding_idx 409 self.confidence = 1.0 - smoothing 410 self.smoothing = smoothing 411 self.size = size 412 self.true_dist = None 413 414 def forward(self, x, target): 415 assert x.size(1) == self.size 416 true_dist = x.data.clone() 417 true_dist.fill_(self.smoothing / (self.size - 2)) 418 true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence) 419 true_dist[:, self.padding_idx] = 0 420 mask = torch.nonzero(target.data == self.padding_idx) 421 if mask.dim() > 0: 422 true_dist.index_fill_(0, mask.squeeze(), 0.0) 423 self.true_dist = true_dist 424 return self.criterion(x, Variable(true_dist, requires_grad=False)) 425 426 427 # > Here we can see an example of how the mass is distributed to the words based on confidence. 428 # crit = LabelSmoothing(5, 0, 0.4) 429 # predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0], 430 # [0, 0.2, 0.7, 0.1, 0], 431 # [0, 0.2, 0.7, 0.1, 0]]) 432 # v = crit(Variable(predict.log()), 433 # Variable(torch.LongTensor([2, 1, 0]))) 434 435 436 # crit = LabelSmoothing(5, 0, 0.1) 437 # def loss(x): 438 # d = x + 3 * 1 439 # predict = torch.FloatTensor([[0, x / d, 1 / d, 1 / d, 1 / d], 440 # ]) 441 # # print(predict) 442 # return crit(Variable(predict.log()), 443 # Variable(torch.LongTensor([1]))).item() 444 445 # # A First Example 446 # > We can begin by trying out a simple copy-task. Given a random set of input symbols from a small vocabulary, the goal is to generate back those same symbols. 447 # ## Synthetic Data 448 def data_gen(V, batch, nbatches): 449 "Generate random data for a src-tgt copy task." 450 for i in range(nbatches): 451 data = torch.from_numpy(np.random.randint(1, V, size=(batch, 10)))#torch.Size([30, 10]) 452 data[:, 0] = 1 #start 453 src = Variable(data, requires_grad=False) 454 tgt = Variable(data, requires_grad=False) 455 yield Batch(src, tgt, 0) 456 # data_gen(11,30,20) 457 458 459 # ## Loss Computation 460 class SimpleLossCompute: 461 "A simple loss compute and train function." 462 def __init__(self, generator, criterion, opt=None): 463 self.generator = generator 464 self.criterion = criterion 465 self.opt = opt 466 467 def __call__(self, x, y, norm): 468 x = self.generator(x) 469 loss = self.criterion(x.contiguous().view(-1, x.size(-1)), 470 y.contiguous().view(-1)) / norm 471 loss.backward() 472 if self.opt is not None: 473 self.opt.step() 474 self.opt.optimizer.zero_grad() 475 return loss.item() * norm 476 477 478 # ## Greedy Decoding 479 # Train the simple copy task. 480 V = 11 481 criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0) 482 model = make_model(V, V, N=2) 483 model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400, 484 torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.9, 0.98), eps=1e-9)) 485 486 for epoch in range(5): 487 model.train() 488 run_epoch(data_gen(V, 30, 20), model, 489 SimpleLossCompute(model.generator, criterion, model_opt)) 490 model.eval() 491 print(run_epoch(data_gen(V, 30, 5), model, 492 SimpleLossCompute(model.generator, criterion, None))) 493 494 495 #This code predicts a translation using greedy decoding for simplicity. 496 def greedy_decode(model, src, src_mask, max_len, start_symbol): 497 memory = model.encode(src, src_mask) 498 ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)#fill start symbol 499 for i in range(max_len-1): 500 out = model.decode(memory, src_mask, 501 Variable(ys), 502 Variable(subsequent_mask(ys.size(1)) 503 .type_as(src.data))) 504 prob = model.generator(out[:, -1]) 505 _, next_word = torch.max(prob, dim = 1) 506 next_word = next_word.data[0] 507 ys = torch.cat([ys, 508 torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1) 509 return ys 510 511 model.eval() 512 src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]) ) 513 src_mask = Variable(torch.ones(1, 1, 10) ) 514 print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1)) 515 516 517 ‘‘‘ 518 # # A Real World Example 519 # 520 # > Now we consider a real-world example using the IWSLT German-English Translation task. This task is much smaller than the WMT task considered in the paper, but it illustrates the whole system. We also show how to use multi-gpu processing to make it really fast. 521 522 #!pip install torchtext spacy 523 #!python -m spacy download en 524 #!python -m spacy download de 525 526 527 # ## Training Data and Batching 528 global max_src_in_batch, max_tgt_in_batch 529 def batch_size_fn(new, count, sofar): 530 "Keep augmenting batch and calculate total number of tokens + padding." 531 global max_src_in_batch, max_tgt_in_batch 532 if count == 1: 533 max_src_in_batch = 0 534 max_tgt_in_batch = 0 535 max_src_in_batch = max(max_src_in_batch, len(new.src)) 536 max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2) 537 src_elements = count * max_src_in_batch 538 tgt_elements = count * max_tgt_in_batch 539 540 return max(src_elements, tgt_elements) 541 542 # ## Data Loading 543 # > We will load the dataset using torchtext and spacy for tokenization. 544 545 # For data loading. 546 from torchtext import data, datasets 547 548 if True: 549 import spacy 550 spacy_de = spacy.load(‘de‘) 551 spacy_en = spacy.load(‘en‘) 552 553 def tokenize_de(text): 554 return [tok.text for tok in spacy_de.tokenizer(text)] 555 556 def tokenize_en(text): 557 return [tok.text for tok in spacy_en.tokenizer(text)] 558 559 BOS_WORD = ‘<s>‘ 560 EOS_WORD = ‘</s>‘ 561 BLANK_WORD = "<blank>" 562 SRC = data.Field(tokenize=tokenize_de, pad_token=BLANK_WORD) 563 TGT = data.Field(tokenize=tokenize_en, init_token = BOS_WORD, 564 eos_token = EOS_WORD, pad_token=BLANK_WORD) 565 566 MAX_LEN = 100 567 train, val, test = datasets.IWSLT.splits( 568 exts=(‘.de‘, ‘.en‘), fields=(SRC, TGT), 569 filter_pred=lambda x: len(vars(x)[‘src‘]) <= MAX_LEN and 570 len(vars(x)[‘trg‘]) <= MAX_LEN) 571 MIN_FREQ = 2 572 SRC.build_vocab(train.src, min_freq=MIN_FREQ) 573 TGT.build_vocab(train.trg, min_freq=MIN_FREQ) 574 575 576 # > Batching matters a ton for speed. We want to have very evenly divided batches, with absolutely minimal padding. To do this we have to hack a bit around the default torchtext batching. This code patches their default batching to make sure we search over enough sentences to find tight batches. 577 # ## Iterators 578 579 class MyIterator(data.Iterator): 580 def create_batches(self): 581 if self.train: 582 def pool(d, random_shuffler): 583 for p in data.batch(d, self.batch_size * 100): 584 p_batch = data.batch( 585 sorted(p, key=self.sort_key), 586 self.batch_size, self.batch_size_fn) 587 for b in random_shuffler(list(p_batch)): 588 yield b 589 self.batches = pool(self.data(), self.random_shuffler) 590 591 else: 592 self.batches = [] 593 for b in data.batch(self.data(), self.batch_size, 594 self.batch_size_fn): 595 self.batches.append(sorted(b, key=self.sort_key)) 596 597 def rebatch(pad_idx, batch): 598 "Fix order in torchtext to match ours" 599 src, trg = batch.src.transpose(0, 1), batch.trg.transpose(0, 1) 600 return Batch(src, trg, pad_idx) 601 602 603 # ## Multi-GPU Training 604 # > Finally to really target fast training, we will use multi-gpu. This code implements multi-gpu word generation. It is not specific to transformer so I won‘t go into too much detail. The idea is to split up word generation at training time into chunks to be processed in parallel across many different gpus. We do this using pytorch parallel primitives: 605 # 606 # * replicate - split modules onto different gpus. 607 # * scatter - split batches onto different gpus 608 # * parallel_apply - apply module to batches on different gpus 609 # * gather - pull scattered data back onto one gpu. 610 # * nn.DataParallel - a special module wrapper that calls these all before evaluating. 611 # 612 613 # Skip if not interested in multigpu. 614 class MultiGPULossCompute: 615 "A multi-gpu loss compute and train function." 616 def __init__(self, generator, criterion, devices, opt=None, chunk_size=5): 617 # Send out to different gpus. 618 self.generator = generator 619 self.criterion = nn.parallel.replicate(criterion, 620 devices=devices) 621 self.opt = opt 622 self.devices = devices 623 self.chunk_size = chunk_size 624 625 def __call__(self, out, targets, normalize): 626 total = 0.0 627 generator = nn.parallel.replicate(self.generator, 628 devices=self.devices) 629 out_scatter = nn.parallel.scatter(out, 630 target_gpus=self.devices) 631 out_grad = [[] for _ in out_scatter] 632 targets = nn.parallel.scatter(targets, 633 target_gpus=self.devices) 634 635 # Divide generating into chunks. 636 chunk_size = self.chunk_size 637 for i in range(0, out_scatter[0].size(1), chunk_size): 638 # Predict distributions 639 out_column = [[Variable(o[:, i:i+chunk_size].data, 640 requires_grad=self.opt is not None)] 641 for o in out_scatter] 642 gen = nn.parallel.parallel_apply(generator, out_column) 643 644 # Compute loss. 645 y = [(g.contiguous().view(-1, g.size(-1)), 646 t[:, i:i+chunk_size].contiguous().view(-1)) 647 for g, t in zip(gen, targets)] 648 loss = nn.parallel.parallel_apply(self.criterion, y) 649 650 # Sum and normalize loss 651 l = nn.parallel.gather(loss, 652 target_device=self.devices[0]) 653 l = l.sum()[0] / normalize 654 total += l.data[0] 655 656 # Backprop loss to output of transformer 657 if self.opt is not None: 658 l.backward() 659 for j, l in enumerate(loss): 660 out_grad[j].append(out_column[j][0].grad.data.clone()) 661 662 # Backprop all loss through transformer. 663 if self.opt is not None: 664 out_grad = [Variable(torch.cat(og, dim=1)) for og in out_grad] 665 o1 = out 666 o2 = nn.parallel.gather(out_grad, 667 target_device=self.devices[0]) 668 o1.backward(gradient=o2) 669 self.opt.step() 670 self.opt.optimizer.zero_grad() 671 return total * normalize 672 673 674 # > Now we create our model, criterion, optimizer, data iterators, and paralelization 675 # GPUs to use 676 devices = [0, 1, 2, 3] 677 if True: 678 pad_idx = TGT.vocab.stoi["<blank>"] 679 model = make_model(len(SRC.vocab), len(TGT.vocab), N=6) 680 model.cuda() 681 criterion = LabelSmoothing(size=len(TGT.vocab), padding_idx=pad_idx, smoothing=0.1) 682 criterion.cuda() 683 BATCH_SIZE = 12000 684 train_iter = MyIterator(train, batch_size=BATCH_SIZE, device=0, 685 repeat=False, sort_key=lambda x: (len(x.src), len(x.trg)), 686 batch_size_fn=batch_size_fn, train=True) 687 valid_iter = MyIterator(val, batch_size=BATCH_SIZE, device=0, 688 repeat=False, sort_key=lambda x: (len(x.src), len(x.trg)), 689 batch_size_fn=batch_size_fn, train=False) 690 model_par = nn.DataParallel(model, device_ids=devices) 691 None 692 693 694 # > Now we train the model. I will play with the warmup steps a bit, but everything else uses the default parameters. On an AWS p3.8xlarge with 4 Tesla V100s, this runs at ~27,000 tokens per second with a batch size of 12,000 695 # ## Training the System 696 #!wget https://s3.amazonaws.com/opennmt-models/iwslt.pt 697 698 if False: 699 model_opt = NoamOpt(model.src_embed[0].d_model, 1, 2000, 700 torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9)) 701 for epoch in range(10): 702 model_par.train() 703 run_epoch((rebatch(pad_idx, b) for b in train_iter), 704 model_par, 705 MultiGPULossCompute(model.generator, criterion, 706 devices=devices, opt=model_opt)) 707 model_par.eval() 708 loss = run_epoch((rebatch(pad_idx, b) for b in valid_iter), 709 model_par, 710 MultiGPULossCompute(model.generator, criterion, 711 devices=devices, opt=None)) 712 print(loss) 713 else: 714 model = torch.load("iwslt.pt") 715 716 717 # > Once trained we can decode the model to produce a set of translations. Here we simply translate the first sentence in the validation set. This dataset is pretty small so the translations with greedy search are reasonably accurate. 718 719 for i, batch in enumerate(valid_iter): 720 src = batch.src.transpose(0, 1)[:1] 721 src_mask = (src != SRC.vocab.stoi["<blank>"]).unsqueeze(-2) 722 out = greedy_decode(model, src, src_mask, 723 max_len=60, start_symbol=TGT.vocab.stoi["<s>"]) 724 print("Translation:", end="\t") 725 for i in range(1, out.size(1)): 726 sym = TGT.vocab.itos[out[0, i]] 727 if sym == "</s>": break 728 print(sym, end =" ") 729 print() 730 print("Target:", end="\t") 731 for i in range(1, batch.trg.size(0)): 732 sym = TGT.vocab.itos[batch.trg.data[i, 0]] 733 if sym == "</s>": break 734 print(sym, end =" ") 735 print() 736 break 737 738 739 # # Additional Components: BPE, Search, Averaging 740 741 # > So this mostly covers the transformer model itself. There are four aspects that we didn‘t cover explicitly. We also have all these additional features implemented in [OpenNMT-py](https://github.com/opennmt/opennmt-py). 742 # 743 # 744 745 # > 1) BPE/ Word-piece: We can use a library to first preprocess the data into subword units. See Rico Sennrich‘s [subword-nmt](https://github.com/rsennrich/subword-nmt) implementation. These models will transform the training data to look like this: 746 # ▁Die ▁Protokoll datei ▁kann ▁ heimlich ▁per ▁E - Mail ▁oder ▁FTP ▁an ▁einen ▁bestimmte n ▁Empfänger ▁gesendet ▁werden . 747 # > 2) Shared Embeddings: When using BPE with shared vocabulary we can share the same weight vectors between the source / target / generator. See the [(cite)](https://arxiv.org/abs/1608.05859) for details. To add this to the model simply do this: 748 749 if False: 750 model.src_embed[0].lut.weight = model.tgt_embeddings[0].lut.weight 751 model.generator.lut.weight = model.tgt_embed[0].lut.weight 752 753 754 # > 3) Beam Search: This is a bit too complicated to cover here. See the [OpenNMT-py](https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/translate/Beam.py) for a pytorch implementation. 755 # > 4) Model Averaging: The paper averages the last k checkpoints to create an ensembling effect. We can do this after the fact if we have a bunch of models: 756 757 def average(model, models): 758 "Average models into model" 759 for ps in zip(*[m.params() for m in [model] + models]): 760 p[0].copy_(torch.sum(*ps[1:]) / len(ps[1:])) 761 762 763 # # Results 764 # 765 # On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big) 766 # in Table 2) outperforms the best previously reported models (including ensembles) by more than 2.0 767 # BLEU, establishing a new state-of-the-art BLEU score of 28.4. The configuration of this model is 768 # listed in the bottom line of Table 3. Training took 3.5 days on 8 P100 GPUs. Even our base model 769 # surpasses all previously published models and ensembles, at a fraction of the training cost of any of 770 # the competitive models. 771 # 772 # On the WMT 2014 English-to-French translation task, our big model achieves a BLEU score of 41.0, 773 # outperforming all of the previously published single models, at less than 1/4 the training cost of the 774 # previous state-of-the-art model. The Transformer (big) model trained for English-to-French used 775 # dropout rate Pdrop = 0.1, instead of 0.3. 776 # 777 # 778 779 780 # > The code we have written here is a version of the base model. There are fully trained version of this system available here [(Example Models)](http://opennmt.net/Models-py/). 781 # > 782 # > With the addtional extensions in the last section, the OpenNMT-py replication gets to 26.9 on EN-DE WMT. Here I have loaded in those parameters to our reimplemenation. 783 784 get_ipython().system(‘wget https://s3.amazonaws.com/opennmt-models/en-de-model.pt‘) 785 786 model, SRC, TGT = torch.load("en-de-model.pt") 787 788 model.eval() 789 sent = "▁The ▁log ▁file ▁can ▁be ▁sent ▁secret ly ▁with ▁email ▁or ▁FTP ▁to ▁a ▁specified ▁receiver".split() 790 src = torch.LongTensor([[SRC.stoi[w] for w in sent]]) 791 src = Variable(src) 792 src_mask = (src != SRC.stoi["<blank>"]).unsqueeze(-2) 793 out = greedy_decode(model, src, src_mask, 794 max_len=60, start_symbol=TGT.stoi["<s>"]) 795 print("Translation:", end="\t") 796 trans = "<s> " 797 for i in range(1, out.size(1)): 798 sym = TGT.itos[out[0, i]] 799 if sym == "</s>": break 800 trans += sym + " " 801 print(trans) 802 803 804 # ## Attention Visualization 805 # 806 # > Even with a greedy decoder the translation looks pretty good. We can further visualize it to see what is happening at each layer of the attention 807 808 tgt_sent = trans.split() 809 def draw(data, x, y, ax): 810 seaborn.heatmap(data, 811 xticklabels=x, square=True, yticklabels=y, vmin=0.0, vmax=1.0, 812 cbar=False, ax=ax) 813 814 for layer in range(1, 6, 2): 815 fig, axs = plt.subplots(1,4, figsize=(20, 10)) 816 print("Encoder Layer", layer+1) 817 for h in range(4): 818 draw(model.encoder.layers[layer].self_attn.attn[0, h].data, 819 sent, sent if h ==0 else [], ax=axs[h]) 820 plt.show() 821 822 for layer in range(1, 6, 2): 823 fig, axs = plt.subplots(1,4, figsize=(20, 10)) 824 print("Decoder Self Layer", layer+1) 825 for h in range(4): 826 draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(tgt_sent)], 827 tgt_sent, tgt_sent if h ==0 else [], ax=axs[h]) 828 plt.show() 829 print("Decoder Src Layer", layer+1) 830 fig, axs = plt.subplots(1,4, figsize=(20, 10)) 831 for h in range(4): 832 draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(sent)], 833 sent, tgt_sent if h ==0 else [], ax=axs[h]) 834 plt.show() 835 836 ‘‘‘
标签:speed regular 预测 beta set enum 代码 object init
原文地址:https://www.cnblogs.com/buyizhiyou/p/11649817.html