标签:sys inter 集群 add eth0 ifconf pod 服务 配置
自建k8s集群,主机操作系统ubuntu16.04,k8s版本v1.14, 集群网络方案calico-3.3.6.
worker节点数50+,均为GPU物理服务器,服务器类型异构,如Nvidia P4/T4/V100等。
故障起因是k8s集群新增加了一台worker节点机器server-n1,该机器上带有8张网卡eth0~eth7,
其中eth0~eth3没有配置ip地址,eth4~eth7配置了ip地址,默认使用eth4网卡。
调度到server-n1节点上的pod,无法访问外网。调度到其他node节点上的pod均能正常访问外网。
根据故障现象,初步确定是server-n1服务器的配置问题。
kubectl get pod -n kube-system -o wide|grep server-n1
发现该节点上的calico-node状态异常,即只有1/2 个容器在Running

kubectl describe pod -n kube-system calico-node-5txhs
主要异常信息如下截图

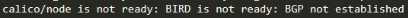
kubectl logs -n kube-system calico-node-5txhs
发现calico-node组件自动侦测到的网卡为eth7,而不是默认使用的eth4.

至此已定位到问题原因。
由于eth5~eth7网卡实际没有被使用,关闭eth5~eth7使calico-node侦测到eth4.
1.在/etc/network/interfaces文件内注释冗余网卡
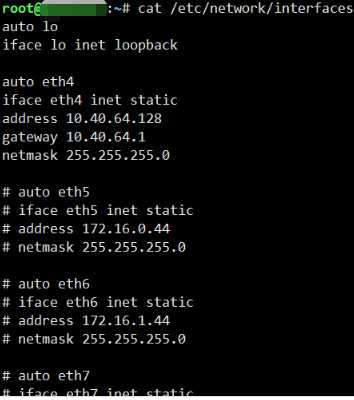
2.关闭eth5~eth7
ifconfig eth5 down
ifconfig eth6 down
ifconfig eth7 down
ip addr flush eth5
ip addr flush eth6
ip addr flush eth7
3.删除重建该机器上的calico-node
kubectl delete pod -n kube-system calico-node-5txhs

标签:sys inter 集群 add eth0 ifconf pod 服务 配置
原文地址:https://www.cnblogs.com/abcdef/p/11651974.html