标签:map lis arch off 成员函数 mil 语音识别 als hub
我的工程实践选题为《基于语音识别的智能聊天机器人设计 》,现在,自然语言的人机交互应用广泛,如苹果的Siri、微软的Cortana、Google Now等。传统的web服务提供商,可以通过和用户的“语音机器人”的对话,将用户引导到对应的服务上,语音助手也在今后智能硬件和智能家居的嵌入式应用中扮演重要的人机交互功能。
这个选题需要研究机器学习的基本方法,需要使用到kaldi和TensorFlow,目前仍处于调研阶段,所以在网上找到一些Tensor Flow代码并讨论其风格与改进。
一、Tensor Flow源代码分析
这是一段SSD在tensorflow models下实现的代码,目录如下,注释已给出:
(1)这个目录中包含README文件让初次接触该代码的人快速了解该代码的结构,official是官方版本,research将tf.contrib.data更新为tf.data.experimental,sample中给出的是数据样本,tutorials是辅导教程,使用distutils.version.strictversion进行版本比较。
(2)对于文件名,作者使用了完整的单词或大家都可以理解的缩写单词来命名如:sample,一个文件名包含两个及以上的单词使用下划线“_”来分隔如:ISSUE_TEMPLATE,在选择文件名的时候尽量使用意思相同的单词来命名,这样既便于书写,也利于阅读。
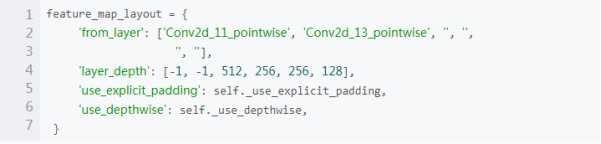
(3)对于类名/函数名/变量名,观察一小段代码可知仍然采用便于理解和记忆的单词和下划线来命名:
‘from_layer’:从mobilenet中提取的namescop的名称,如果为空则表示新生成的。其value为list,长度为6,也就是6个不同尺度的featuremap。
‘layer_depth’:表示channel的深度,为空,表示从原有的net中继承。
‘use_explicit_padding’:如果使能,选择valid pading,并在valid padding之前先做一次fixed padding,其目的是为了让经过卷积后的size与使用same padding的大小一致。
(4)对于代码的维护,作者在github上修改并维护(https://github.com/tensorflow/models)
(5)该代码格式很严谨但仍有一些注释没有做到很好,并且有些多个函数调用的时候应该在所有的后面再作注释会好一点,而文中是在中间换行做的注释,阅读起来有不连续感。
二、代码规范和风格的一般要求
标识符应当直观且可以拼读,可望文知意,不必进行“解码”。
1.标识符的长度应当符合“min-length && max-information”原则。
2.命名规则尽量与所采用的操作系统或开发工具的风格保持一致。
3.程序中不要出现仅靠大小写区分的相似的标识符。
4.变量的名字应当使用“名词”或者“形容词+名词”。
5.全局函数的名字应当使用“动词”或者“动词+名词”(动宾词组)。类的成员函数应当只使用“动词”,被省略掉的名词就是对象本身。
6.用正确的反义词组命名具有互斥意义的变量或相反动作的函数等。
7.尽量避免名字中出现数字编号,如Value1,Value2等,除非逻辑上的确需要编号。这是为了防止程序员偷懒,不肯为命名动脑筋而导致产生无意义的名字(因为用数字编号最省事)。
编写代码过程中要做到心细,养成自己的良好习惯:
1.每个函数定义结束后都要加空行。两个相对独立的程序块,变量说明之后必须加空行。
2.大括号{}分别要独占一行,互为一对要位于同一列,并且引用他们的语句左对齐。
3.减少函数本身或函数间的递归调用。
4.注释的原则是有助于对程序的阅读理解,注释语言必须准确、易懂、简洁。
5.程序应做到互相对齐,不要出现随意空格的情况。
标签:map lis arch off 成员函数 mil 语音识别 als hub
原文地址:https://www.cnblogs.com/lsxu/p/11665506.html