标签:组成 img 大小 href add 一个 ast 现在 row
(啊,图片好像还有CSDN水印呢)
主要参考资料:CLJppt。
自动机组成:状态、初始状态、终止状态、状态转移、字符集。
经典图片:
ACADD对应的SAM
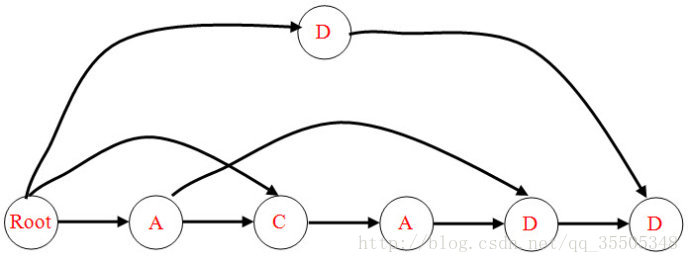
对于整个串而言,初始状态(以下简称为init)为ROOT,终止状态集合(以下简称end)为最上方及最右方的那两个写着D的圈(状态既不是字符,也不是子串,在这里把它理解为某个下标更好),所有的状态就是那七个圈,每条实线边代表从一个状态向另一个状态的状态转移。字符集不太重要,在这里为26个字母(暂不区分大小写)。
为便于阅读及写作,下文中,定义均使用
的格式进行标注。当发现有问题时,不妨回到开头再看一眼定义。
例如,上图中,如果当前状态在左下角的A这个圈,通过‘D‘可以转移到右下角倒数第二个D这个圈,通过‘C‘可以转移到。。。唯一的C所在的圈。
由于一直用**圈**表述状态实在太麻烦,因此在不引起歧义的前提下,我也会使用某个字符来表示状态。但请时刻注意,状态并非字符。
例如,上图中,从init通过字符串"AC"转移可以到达唯一的那个C。
很明显,有如下函数(伪代码):
trans(s,str)
cur = s;
for i = 0 to len(str) - 1
cur = trans(cur, str[i])
return cur就是说,\(trans(s,str)\)可以看成是一大堆\(trans(s,ch)\)的总和。
(说白了就是把x放到ROOT上开始沿着边跑,如果在end中节点上结束,就说能识别。栗子:我往一颗Trie树中插了字符串"ACADD",那这颗Trie就能识别"ACADD",不能识别"ACA"、"BC"等等奇奇怪怪的字符串)
比如,还是刚才那图,从C开始,"DD"可以被识别(因为\(trans(C\)所在的圈,\("DD") \in end\))
也就是说,当且仅当x是S的后缀时,\(x \in Reg(SAM)\)。既然能识别所有的后缀,那我们扩展end集合后,SAM也能识别S所有后缀的前缀,即S的子串。
当然我们可以把一个串的所有后缀都插入Trie树,这当然也是后缀自动机,但是时间、空间复杂度都是\(O(n^2)\)。
考虑到这样一颗Trie树会有很多重复的字符,因此我们需要最简状态后缀自动机,即状态数(就是需要的圈)最少的后缀自动机。
定义\(ST(str)\)为初始状态读入str(以下用“读入%s”表示“通过%s转移”)后到达的状态。
对于一个字符串s,如果\(s \notin Fac\),那么\(ST(s)=NULL\)(显然)。而如果\(s \in Fac\),那么\(ST(S) \not= NULL\),因为如果s是S的子串,在s后面加上一些字符就可能变为S的后缀。
考虑朴素的插入,是对每个\(s \in Fac\)都新建一个状态(既然对所有后缀建一条链,那对于某个后缀的前缀的最后一个字符,都要新建一个状态,那么可以看作对每个子串新建了一个状态),这样做是\(O(n^2)\)的。
考虑对于某个字符串\(a\),\(ST(a)\)能识别那些字符串,即从\(ST(a)\)起通过那些字符串可转移到end,即\(Reg(ST(a))\)
\(x \in Reg(SAM)\),当且仅当\(x \in Suf\)
\(x \in Reg(ST(a))\),当且仅当\(ax \in Suf\)
也就是说ax是S后缀,那么x必定也是S后缀。\(\therefore Reg(ST(a))\)是一些后缀集合。
现在,对于一个状态s,我们只关注\(Reg(s)\)。
对于某个子串a,如果\(S[l,r)==a\),那么\(ST(a)\)能识别\(Suffix(r)\)。
如果a在S中出现的位置的集合为\(\{(l,r)|S[l,r)==a\}=\{[l_1,r_1),[l_2,r_2),...,[l_n,r_n)\}\),那么\(Reg(ST(a))=\{Suffix(r_1),Suffix(r_2),...,Suffix(r_n)\}\)。
不妨令\(Right(a)=\{r_1,r_2,...,r_n\}\)。
那么\(Reg(ST(a))\)完全由\(Right(a)\)决定。
又因为我们要使状态数最少,那所有状态s应该与所有\(Reg(s)\)一一对应(首先,每个状态s一定能映射到一个Reg集合。然后,如果两个s映射到同一个Reg集合,为什么不把它们合并呢?)。也就是说,\(Reg(ST(a))==Reg(ST(b)) \Leftrightarrow ST(a)==ST(b)\)
那么对于两个子串\(a,b \in Fac\),如果\(Right(a)=Right(b)\),那么\(Reg(ST(a))=Reg(ST(b))\),即\(ST(a)=ST(b)\)。
所以一个状态s,可以由所有\(Right\)集合是\(Right(s)\)的字符串从init转移到达。记这些字符串为\(Sub(s)\)
不妨设\(r \in Right(s)\),那么如果再给出一个合法的子串长度len,那么这个子串就是\(S[r-len,r)\)。即给定某个合法的(在这里指存在某个状态s的Right集合等于它)Right集合后,再给出一个合法的长度就可以确定子串了。
考虑对于一个Right集合,如果对于串长为\(len=l\ or\ len=r\)的子串是合法的,那么对于\(len \in [l,r]\)的子串也一定合法。
一些说明:设Right集合\(R_1\)中有一元素 \(substring\underline{\;}r_{1}\) ,在 \(len=l\ or\ len=r(l<=r)\) 的情况下 \(Right(S[substring\underline{\;}r_{1}-len,substring\underline{\;}r_{1}))=R_1\) ,那么情况如图。
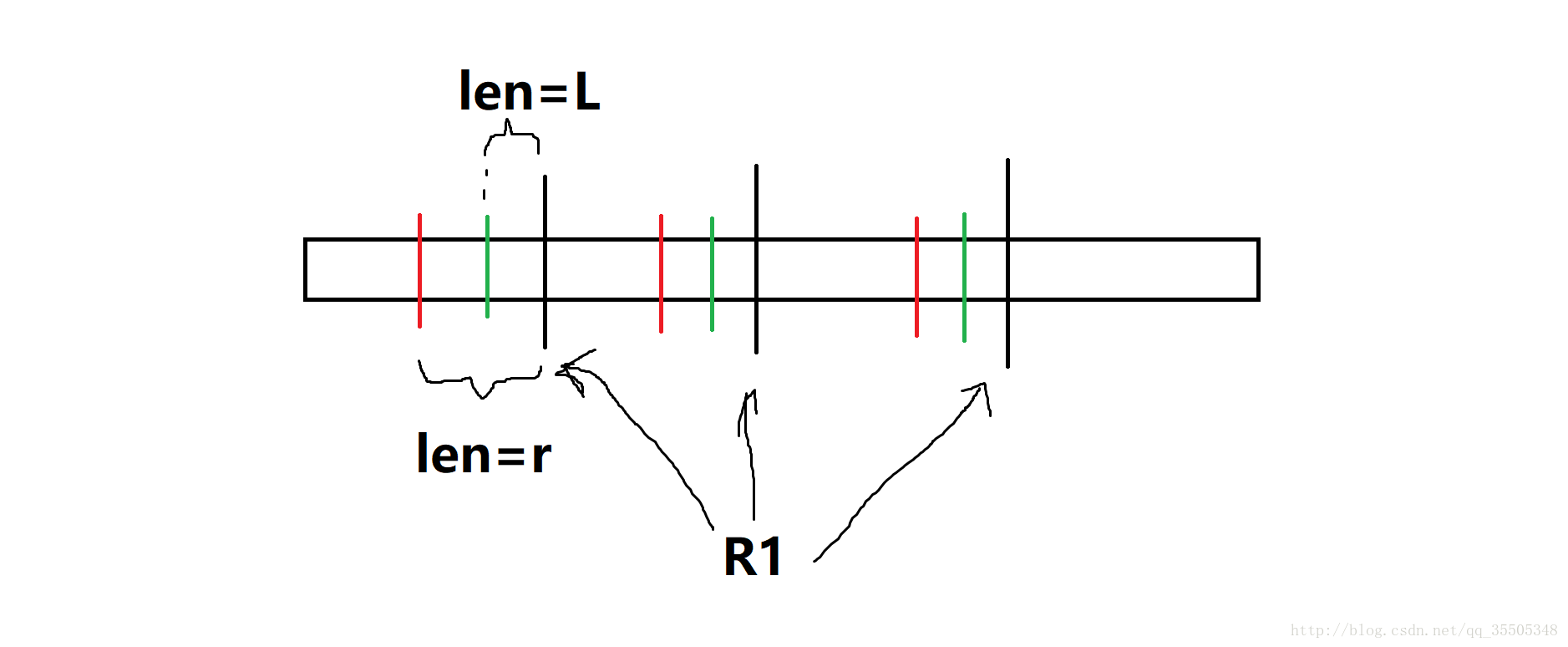
很显然,对于\(len \in [l,r],S[substring\underline{\;}r_1-len,substring\underline{\;}r_1)\),都可以且仅可以识别R1中元素开始的后缀。而对于\(len>r\),只能保证仅可以;对于\(len<l\),只能保证可以。因此在\(len \notin [l,r]\)情况下,不保证\(Right(S[substring\underline{\;}r_1-len,substring\underline{\;}r_1))=R_1\)。
所以对于一个Right集,合法的长度只能存在于一个区间内。
不妨设对于一状态s,合法的区间长度为\([Min(s),Max(s)]\)
考虑两个状态a,b,各自的Right集合分别为\(R_a,R_b\)。
假设\(R_a \cap R_b \not= \emptyset\),设\(r \in R_a \cap R_b\)。
由于\(Sub(a),Sub(b)\)不会有交集(\(trans(init,str)\)只能到达一个状态),所以\([Min(a),Max(a)]\)和\([Min(b),Max(b)]\)也不可能有交集(不然的话以r为结束的某些子串会既到达a,又到达b)。
不妨设\(Max(a)<Min(b)\),那么\(Sub(a)\)中所有串长度都小于\(Sub(b)\)中的串。由于\(Sub(a),Sub(b)\)中的串都可以接上\(Suffix(r)\)(\(Right\)定义),那么\(Sub(a)\)中串必定是\(Sub(b)\)中串的后缀。
于是\(Sub(b)\)中某串出现的位置上,\(Sub(a)\)中某串也必然能在这里出现。因此\(R_b \subset R_a\)。又\(R_a \not= R_b\),所以\(R_b \subsetneqq R_a\)。
于是,\(Fac\)中任意两串的\(Right\)集合,要么不相交,要么一个是另一个的真子集,要么完全相同。
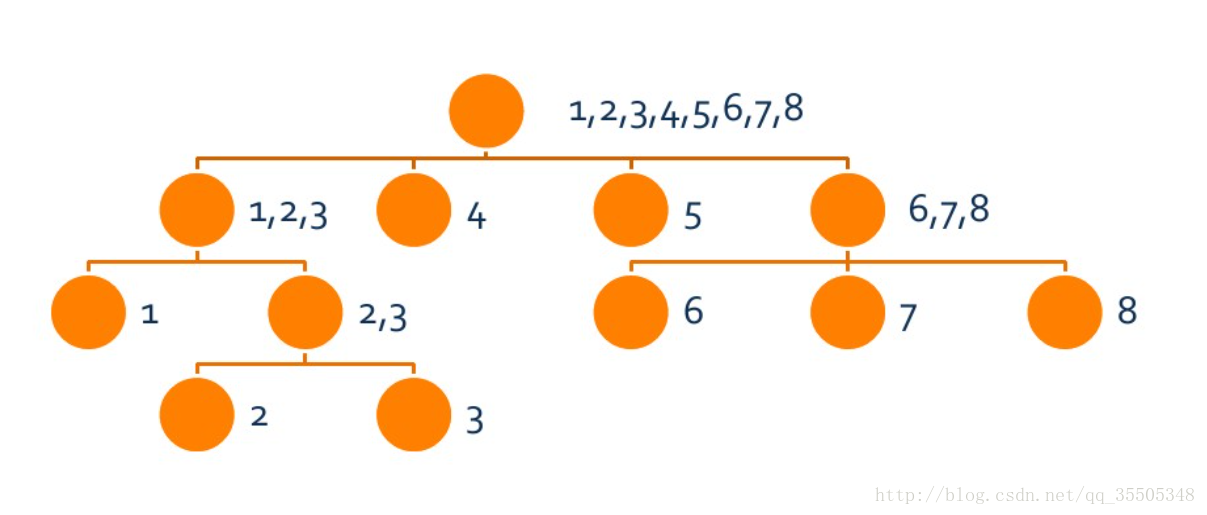
那么,如果我们把所有的\(Right\)集合组成集合,我们可以把他们组织成一个树的结构(如上图)。我们把它叫做Parent树。
很明显,这棵树叶节点有n个,而每个非叶子节点至少有两个孩子(不存在只有一个孩子),易证树的大小为\(O(n)\)级别(显然??)。
令一个状态s,令\(fa=Parent(s)\)代表唯一的那个\(Right\)集合是\(Right(s)\)父节点对应的集合的状态(这句话有点绕口,多读)。那么自然有\(Right(s) \subsetneqq Right(fa)\),并且\(Right(fa)\)的大小是其中最小的。
考虑\(len(Sub(s))\)和\(len(Sub(fa))\)。则\(len(Sub(s)) \in [Min(s),Max(s)]\)。考虑\(Min(s)-1\)为什么不可以,因为长度变短,限制条件变少,于是可出现的位置多了。假设\(Right(s)=R_1\),还是这幅图:
这是\(Min(s)-1\)的情况:
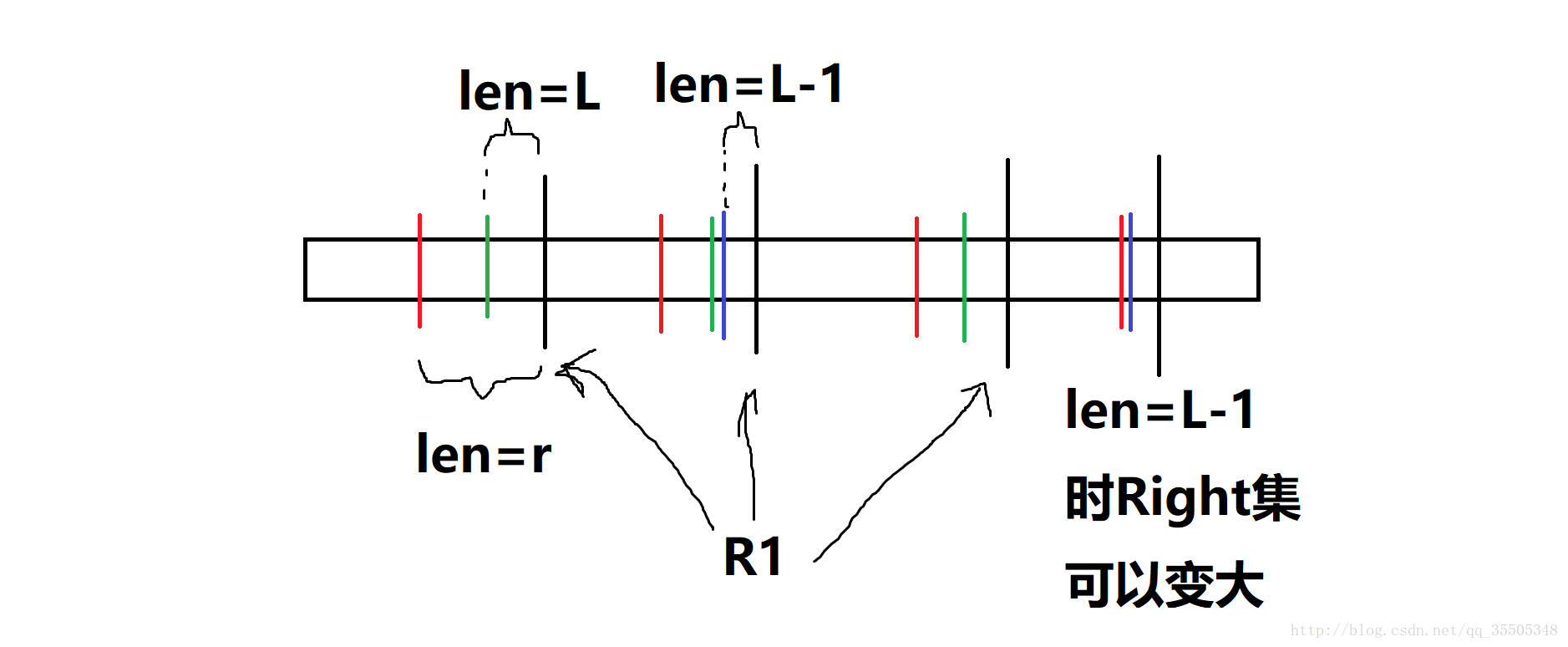
显然,这个变大后的\(Right\)集是所有包含\(R_1\)的集合中最小的一个。因此它就是\(Right(fa)\)。因此,\(Max(fa)=Min(s)-1\)。(L就是\(Min(s)\))
我们已经证明了状态数是\(O(n)\)的,为证明这是一个线性结构,还需证明它状态转移数也是\(O(n)\)的。
s->ch[a] = t)。自己看CLJ课件去!
显然法:状态是\(O(n)\)的,每个状态最多连出26条边,状态很显然是\(O(n)\)的。
对于一个状态s,它的\(Right(s)=\{r_1,r_2,...,r_n\}\),现有s->ch[a]=t,考虑t的\(Right\)集合,由于t比s多一个字符,因此它限制更多,\(Right(t)=\{r_i+1|S[r_i]==c\}\)。
终于可以把这张大图下放了。
例如,对这个"ACADD"的SAM,若s = root->ch[‘a‘],t = s->ch[‘d‘],那么\(Right(s)=\{1,3\}\)(对应的后缀为"DD","ACDD"),\(Right(t)=\{4\}\)(对应的后缀为"D"),显然符合前面所说规则。(记住下标从0开始)
同时,如果s出发有标号为x的边,那么\(Parent(s)\)出发也一定有(因为\(s \subsetneqq Parent(s)\))。
令\(f=Parent(s)\)。那么\(Right(trans(s,c)) \subset Right(trans(f,c))\)(因为\(s \subsetneqq f\))。
一个显然的推论是\(Max(t)>Max(s)\)。(对t而言,如果不考虑\(Min(t)\),那么\(len=Max(s)+1\)显然合适)
我们使用在线方法构造,即每次添加一个字符,使得当前SAM变成包含这个新字符的SAM(即,先构造\(SAM(S[0,i)\),再构造\(SAM(S[0,i+1)\))。
令当前字符串为T,新字符为x,令\(len(t)=L\)。
在\(SAM(T) \rightarrow SAM(Tx)\)的过程中,这个SAM可以多识别一些原串S的子串,这些子串都是Tx的后缀。
Tx的后缀,就是在T的后缀后面接上字符x。
考虑所有可以表示T后缀(即,\(Right\)集中包含L)的节点\(v_1,v_2,v_3,...\)。
由于必然存在一个\(Right(p)=L\)的状态p(\(p=ST(T)\)),那么由于\(v_1,v_2,v_3...\)的\(Right\)集合中都含有L,那么它们在\(Parent\)树中必然全是p的祖先(由于\(Parent树的性质\))。那么可以使用\(Parent\)函数得到它们。
同时我们添加一个字符x后,令\(np=ST(Tx)\),则此时\(Right(np)=L+1\)。
不妨设\(v_1=p,v_2=Parent(v_1),v_3=Parent(v_2),...,v_k=Parent(v_{k-1})=root\)(\(Right(root)=[0,L]\))。
考虑其中一个v的\(Right\)集合\(\{r_1,r_2,...,r_n\}(r_n=L)\),那么如果v->ch[x]=nv,则\(Right(nv)=\{r_i+1\ |\ S[r_i]==x\}\)。同时,如果v->ch[x]=NULL,那么v的\(Right\)集合内就没有一个\(r_i\)使得\(S[r_i]==x\)(先不考虑\(v_n\))。
又由于\(Right(v_1) \subsetneqq Right(v_2) \subsetneqq Right(v_3)...\),那么如果v[i]->ch[x]!=NULL,那么v[j]->ch[x]也一定不是NULL(\(j>i\))。
对于v->ch[x]==NULL的v,它的\(Right\)集合内只有\(r_n\)满足要求,所以根据之前提到的规则,使得v->ch[x]=np。
令\(v_p\)为\(v_1,v_2,v_3,...\)中第一个ch[x]!=NULL的状态。
考虑\(Right(v_p)=\{r_1,r_2,...,r_n\}\),令\(trans(v_p,x)=q\)。
那么\(Right(q)=\{r_i+1|S[r_i]==x\}\)(不考虑 \(r_n\) )。
但是,我们不一定能直接在\(Right(q)\)中插入\(L+1\)(暂且不管如何插入)。
如果在\(Right(q)\)中直接插入\(L+1\),由于限制条件增加,可能使\(Max(q)\)变小。
放图:

红色是结束在\(Right(v_p)\)位置上,长度为\(Max(v_p)\)的串,蓝色为结束在\(Right(q)\)位置上,长度为\(Max(q)\)的串。
于是强行做的话,\(Max(q)\)变小就很显然了。
当然,如果\(Max(q)==Max(v_p)+1\),就不会有这样的问题(这个很显然,把上图蓝色串开头的A改成B就行了),直接插入即可。
怎么插入?\(Parent(np)=q\)。
证明:很显然\(Right(np) \subsetneqq Right(q)\)(q不会是\(ST(T)\),\(L+1 \in Right(q)\)),所以只需证明\(Right(q)\)是所有包含\(Right(np)\)的集合中大小最小的。反证法,假设存在一个包含\(Right(np)\)的集合\(Right(f)\),且\(Parent(f)=q\),那么\(Min(f)=Max(q)+1\),于是当\(len=Max(q)+1\)时,\(len \in [Min(f),Max(f)]\)。设\(Right(q)=\{r_1,r_2,...,r_k,...,r_n\}\),\(Right(f)=\{r_1,r_2,...,r_k,r_n\}\),看图。
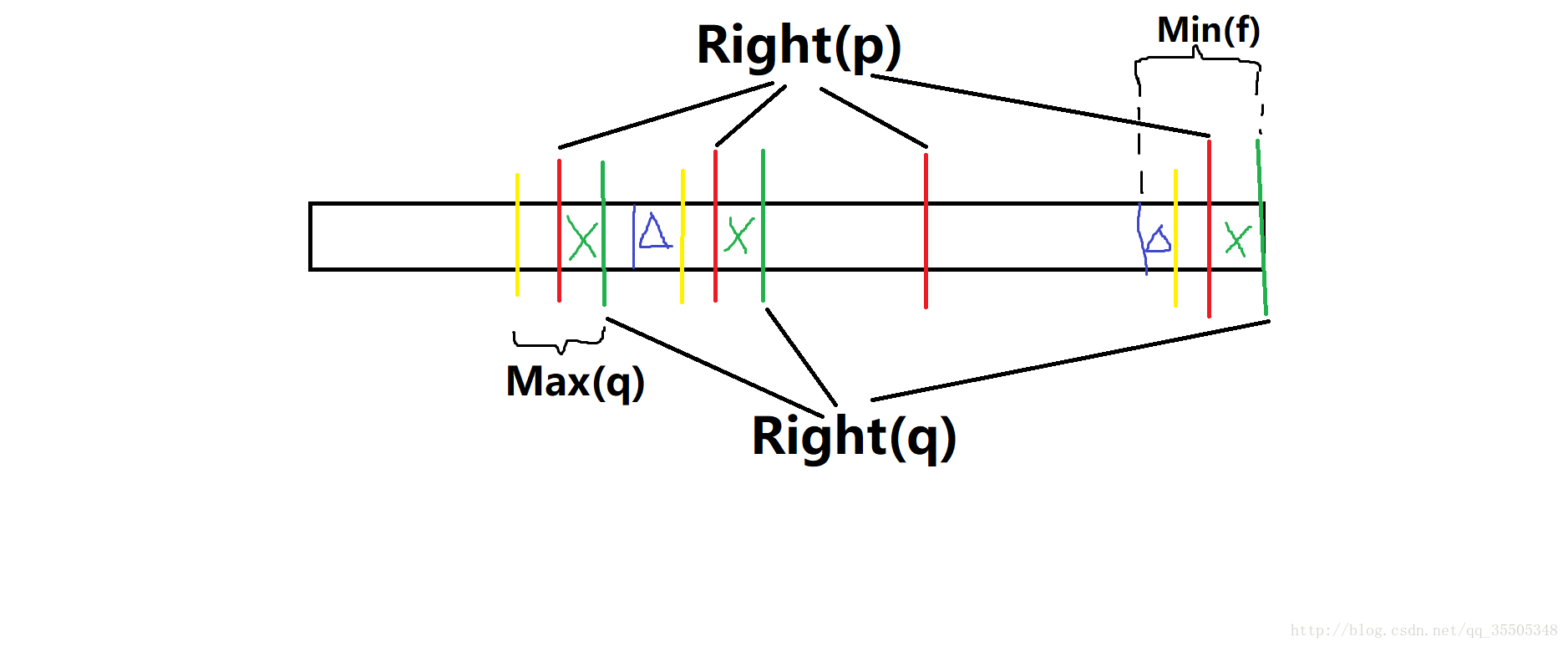
如果真是这样,\(Right(p)\)不会是图上的\(Right(p)\),其中上方左数第一条边不应该存在(左数第三条可能也不存在)。因为只需要第2、4条边就可以使
p->ch[x]!=NULL了,而这时第一条边显然还没有(加入它后Right(p)会变小)。于是产生矛盾,由此命题得证。
在2的情况下再减去一些限制条件又会怎样呢?
比如,现在没有了\(Max(q)==Max(v_p)+1\)。
这个条件这么好,没有了岂不是可惜?
没有条件,创造条件。

上图中,红色为\(Right(v_p)\),蓝色为\(Right(q)\),绿色为\(Right(nq)\)。
我们把q拆成两份:新建一个节点nq,使\(Right(nq)=Right(q) \cup \{L+1\}\)。这时,我们可以证明\(Max(nq)=Max(v_p)+1\),由于证法与上面那个证明非常类似所以不说了。
于是\(Right(q),Right(np) \subsetneqq Right(nq)\),且\(Right(np)+Right(q)=Right(nq)\)(图上可以看出)。于是,\(Parent(np)=Parent(q)=Parent(nq)\)。
又由于\(Min(q)=Min(nq)\)(感性认知),所以\(Parent(nq)=Parent(q)\)(原来的)。
然后,\(trans(nq,x)=trans(q,x)\)(因为多出来的那个点再转移过程中没有用)。
接着,我们回头考虑\(v_1,v_2,...,v_k\)这一序列。其中最早在\(v_p\)处ch[x]!=NULL。于是乎只有一段\(v_p,...,v_e\)(不是\(v_p,...,v_k\),因为\(v_e\)之后\(Right(v->ch[x])\)会更大)通过x边转移到q。那么现在把这一段的\(trans(\ast,x)\)改为nq既可。
//源文件竟有4000字了?
标签:组成 img 大小 href add 一个 ast 现在 row
原文地址:https://www.cnblogs.com/pupuvovovovo/p/11679394.html