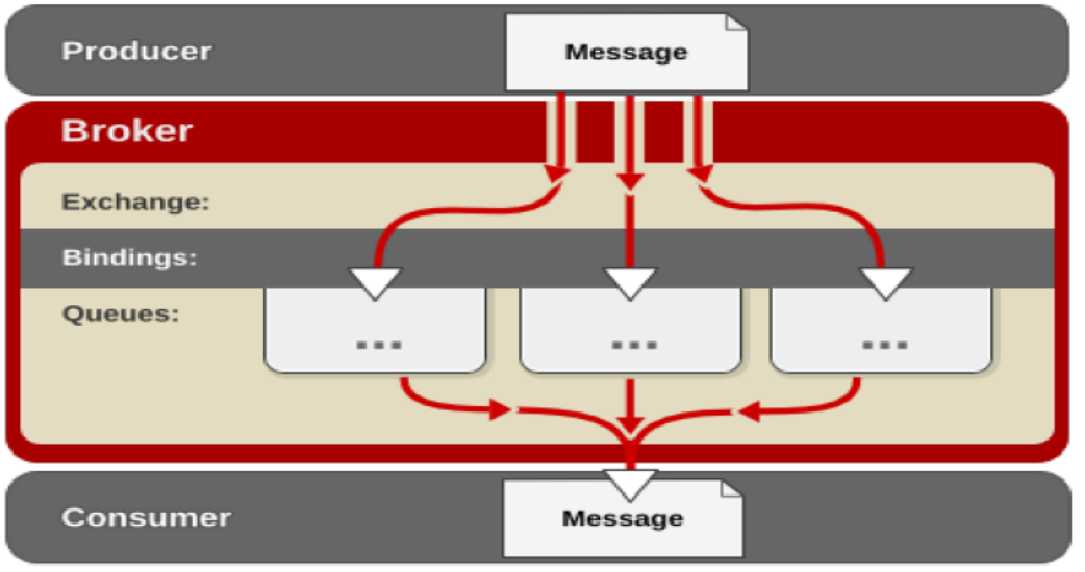
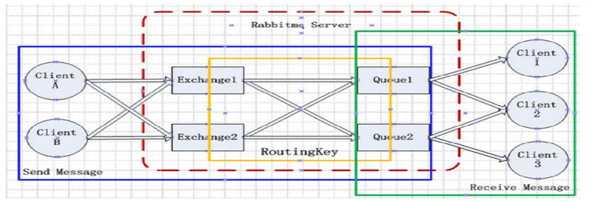
元数据可以持久化在 RAM 或 Disc. 从这个角度可以把 RabbitMQ 集群中的节点分成两种 :RAM Node和 Disk Node.
RAM Node 只会将元数据存放在RAM
Disk node 会将元数据持久化到磁盘。
单节点系统就没有什么选择了 , 只允许 disk node, 否则由于没有数据冗余一旦重启就会丢掉所有的配置信息 . 但在集群环境中可以选择哪些节点是 RAM node.在集群中声明(declare) 创建 exchange queue binding, 这类操作要等到所有的节点都完成创建才会返回 :
如果是内存节点就要修改内存数据 ,
如果是 disk node 就要等待写磁盘 , 节点过多这里的速度就会被大大的拖慢 .
有些场景 exchang queue 相当固定 , 变动很少 ,那即使全都是 disc node, 也没有什么影响 . 如果使用 Rabbitmq 做 RPC( RPC :Remote Procedure Call—远程过程调用), RPC 或者类似 RPC 的场景这个问题就严重了 , 频繁创建销毁临时队列 , 磁盘读写能力就很快成为性能瓶颈了。所以 , 大多数情况下 , 我们尽量把 Node 创建为RAM Node. 这里就有一个问题了 , 要想集群重启后元数据可以恢复就需要把集群元数据持久化到磁盘 , 那需要规划 RabbitMQ 集群中的 RAM Node 和 Disc Node 。
只要有一个节点是 Disc Node 就能提供条件把集群元数据写到磁盘 ,RabbitMQ 的确也是这样要求的 : 集群中只要有一个 disk node 就可以 , 其它的都可以是 RAM node. 节点加入或退出集群一定至少要通知集群中的一个 disk node 。
如果集群中 disk node 都宕掉 , 就不要变动集群的元数据 . 声明 exchange queue 修改用户权限 , 添加用户等等这些变动在节点重启之后无法恢复 。
有一种情况要求所有的 disk node 都要在线情况在才能操作 , 那就是增加或者移除节点 .RAM node 启动的时候会连接到预设的 disk node 下载最新的集群元数据 . 如果你有两个 disk node(d1 d2), 一个 RAM node 加入的时候你只告诉 d1, 而恰好这个 RAM node 重启的时候 d1 并没有启动 , 重启就会失败 . 所以加入 RAM 节点的时候 , 把所有的disk node 信息都告诉它 ,RAM node 会把 disk node 的信息持久化到磁盘以便后续启动可以按图索骥 .
八、Rabbitmq 集群部署
一、前期准备
(1)条件:准备3台linux系统,确保配置好源,及epel源
(2)三台机器能够静态解析彼此
(3)设置可以无密钥登陆
二、安装过程:
(1)所有node安装rabbtimq和erlang软件包:
yum install -y erlang rabbitmq-server.noarch
systemctl enable rabbitmq-server.service
systemctl start rabbitmq-server.service
systemctl status rabbitmq-server.service
查看监听端口:
netstat -lantp | grep 5672
配置文件:
vim /etc/rabbitmq/rabbitmq.config
(2)node1:修改guest密码为admin(默认用户为:guest 密码为:guest)
rabbitmqctl change_password guest admin
(3)node1:添加一个openstack的用户,并设密码为admin。并设置权限和成为管理员
node1:
rabbitmqctl add_user openstack admin
rabbitmqctl set_permissions openstack ".*" ".*" ".*"
rabbitmqctl set_user_tags openstack administrator
(4)node1:编辑rabbittmq变量文件
vim /etc/rabbitmq/rabbitmq-env.conf
RABBITMQ_NODE_PORT=5672
ulimit -S -n 4096
RABBITMQ_SERVER_ERL_ARGS="+K true +A30 +P 1048576 -kernel inet_default_connect_options [{nodelay,true},{raw,6,18,<<5000:64/native>>}] -kernel inet_default_listen_options [{raw,6,18,<<5000:64/native>>}]"
RABBITMQ_NODE_IP_ADDRESS=172.16.254.60
(5)node1:将rabbittmq变量文件拷贝到其他两节点,之后并修改相应节点的ip
scp /etc/rabbitmq/rabbitmq-env.conf con2:/etc/rabbitmq/
scp /etc/rabbitmq/rabbitmq-env.conf con3:/etc/rabbitmq/
查看rabbitmq插件
/usr/lib/rabbitmq/bin/rabbitmq-plugins list
(6)所有node 开启rabbitmq的web管理页面
/usr/lib/rabbitmq/bin/rabbitmq-plugins enable rabbitmq_management mochiweb webmachine rabbitmq_web_dispatch amqp_client rabbitmq_management_agent
或者:rabbitmq-plugins enable rabbitmq_management
systemctl restart rabbitmq-server.service
systemctl status rabbitmq-server.service
(7)node1发送erlang.cookie到其他节点配置集群
rabbitmqctl status
scp /var/lib/rabbitmq/.erlang.cookie con2:/var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie con3:/var/lib/rabbitmq/.erlang.cookie
(8)node2和node3停止应用,并以ram的方式加入node1节点,之后重启应用
systemctl restart rabbitmq-server.service
rabbitmqctl stop_app
rabbitmqctl join_cluster --ram rabbit@con1
rabbitmqctl start_app
(9)node1检查集群状态
[root@con1 conf]# rabbitmqctl cluster_status
Cluster status of node rabbit@con1 ...
[{nodes,[{disc,[rabbit@con1]},{ram,[rabbit@con3,rabbit@con2]}]},
{running_nodes,[rabbit@con3,rabbit@con2,rabbit@con1]},
{cluster_name,<<"rabbit@con1">>},
{partitions,[]},
{alarms,[{rabbit@con3,[]},{rabbit@con2,[]},{rabbit@con1,[]}]}]
其他命令:
(1)添加管理员:
rabbitmqctl add_user mqadmin mqadmin
rabbitmqctl set_user_tags mqadmin administrator
rabbitmqctl set_permissions -p / mqadmin ".*" ".*" ".*"
(2)更改节点类型(内存型或磁盘型)
rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type disc 或 rabbitmqctl change_cluster_node_type ram
rabbitmqctl start_app
(3)从集群移除节点(或者重置节点)
rabbitmqctl stop_app
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl cluster_status
(4)从某个节点移除集群中其他节点
rabbitmqctl forget_cluster_node rabbit@node3
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl cluster_status
1. 保证集群中至少有一个磁盘类型的节点以防数据丢失,在更改节点类型时尤其要注意。
2. 若整个集群被停掉了,应保证最后一个 down 掉的节点被最先启动,若不能则要使用 forget_cluster_node 命令将其移出集群
3. 若集群中节点几乎同时以不可控的方式 down 了此时在其中一个节点使用 force_boot 命令重启节点