标签:person 添加 mic 定义 ati src search 连续 ssi
Airbnb 平台包含数百万种不同的房源,用户可以通过浏览搜索结果页面来寻找想要的房源,我们通过复杂的机器学习模型使用上百种信号对搜索结果中的房源进行排序。 当用户查看一个房源时,他们有两种方式继续搜索:
我们 99% 的房源预订来自于搜索排序和相似房源推荐。
这种嵌入是从搜索会话(Session)中学到的 Airbnb 房源的一种矢量表示,并可用此来衡量房源之间的相似性。 房源嵌入能有效地编码很多房源特征,比如位置、价格、类型、建筑风格和房屋风格等等,并且只需要用 32 个浮点数。我们相信通过嵌入的方法来做个性化和推荐对所有的双边市场平台都非常有效。
嵌入的背景
将词语表示为高维稀疏向量 (high-dimensional, sparse vectors) 是用于语言建模的经典方法。不过,在许多自然语言处理 (NLP) 应用中,这一方法已经被基于神经网络的词嵌入并将词语用低维度 (low-dimentional) 来表示的新模型取代。新模型假设经常一起出现的词也具有更多的统计依赖性,会直接考虑词序及其共现 (co-occurrence) 来训练网络。 随着更容易扩展的单词表达连续词袋模型 (bag-of-words) 和 Skip-gram 模型的发展,在经过大文本数据训练之后,嵌入模型已被证明可以在多种语言处理任务中展现最佳性能。
最近,嵌入的概念已经从词的表示扩展到 NLP 领域之外的其他应用程序。来自网络搜索、电子商务和双边市场领域的研究人员已经意识到,就像可以通过将句子中的一系列单词视为上下文来训练单词嵌入一样,我们也可以通过处理用户的行为序列来训练嵌入用户操作,比如学习用户点击和购买的商品或浏览和点击的广告。 这样的嵌入已经被用于 web 上的各种推荐系统中。
房源嵌入
我们的数据集由 N 个用户的点击会话 (Session) 组成,其中每个会话定义为一个由用户点击的 n 个房源 id 组成的的不间断序列;同时,只要用户连续两次点击之间的时间间隔超过30分钟,我们就会认为是一个新的会话。 基于该数据集,我们的目标是学习一个 32 维的实值表示方式来包含平台上所有的房源,并使相似房源在嵌入空间中处于临近的位置。
列表嵌入的维度被设置为,这样的设置可以平衡离线性能(在下一节中讨论)和在线搜索服务器内存中存储向量所需的空间,能够更好地进行实时相似度的计算。
目前有几种不同的嵌入训练方法,在这里,我们将专注于一种称为负抽样 (Negative Sampling) 的技术。 首先,它将嵌入初始化为随机向量,然后通过滑动窗口的方式读取所有的搜索会话,并通过随机梯度下降(stochastic gradient descent)来更新它们。 在每一步中,我们都会将中央房源的向量更新并将其推向正向相关房源的向量(用户在点击中心房源前后点击的其他房源,滑动窗口长度为),并通过随机抽样房源的方式将它从负向相关房源推开(因为这些房源很大几率与中央房源没有关系)。
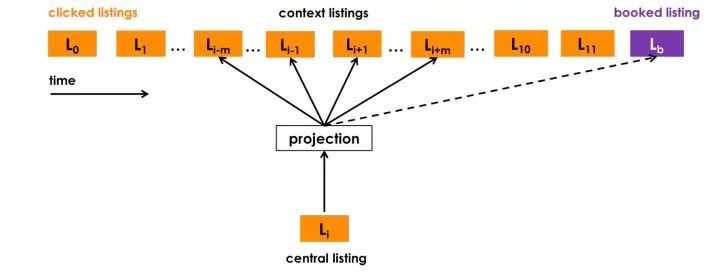
使用最终预订的房源作为全局上下文 (Global Context) :我们使用以用户预订了房源(上图中紫色标记)为告终的用户会话来做这个优化,在这个优化的每个步骤中我们不仅预测相邻的点击房源,还会预测最终预订的房源。 当窗口滑动时,一些房源会进入和离开窗口,而预订的房源始终作为全局上下文(图中虚线)保留在其中,并用于更新中央房源向量。
适配聚集搜索的情况:在线旅行预订网站的用户通常仅在他们的旅行目的地内进行搜索。 因此,对于给定的中心房源,正相关的房源主要包括来自相同目的地的房源,而负相关房源主要包括来自不同目的地的房源,因为它们是从整个房源列表中随机抽样的。 我们发现,这种不平衡会导致在一个目的地内相似性不是最优的。 为了解决这个问题,我们添加了一组从中央房源的目的地中抽样选择的随机负例样本集。
http://wemedia.ifeng.com/89455165/wemedia.shtml
Real-time Personalization using Embeddings for Search Ranking at Airbnb
标签:person 添加 mic 定义 ati src search 连续 ssi
原文地址:https://www.cnblogs.com/Lee-yl/p/11693151.html