标签:shu dna __name__ sample 标记 预处理 append 一个 划分数
首先,根据Detectron官方介绍,数据集一般为jpg格式,分辨率一般为800*600左右。
在这里我们可以photoshop批量对图片进行处理
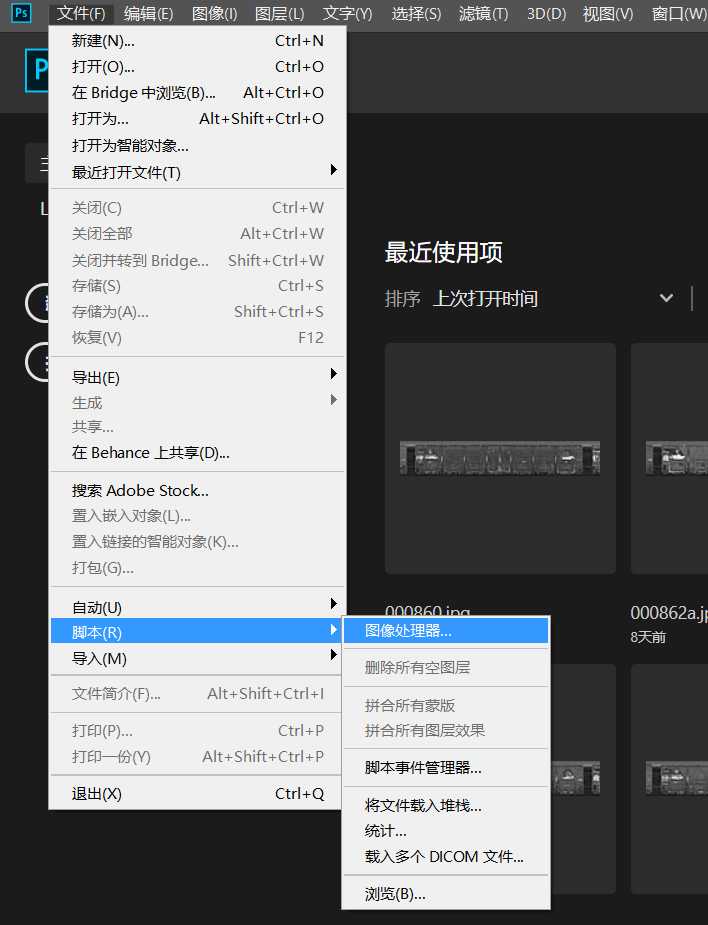
安装labelImg之后,打开文件目录,找到data文件夹下的predefined_classes.txt并打开,修改里面的内容,将自己定义的标签名添加到下面,这样在标注图片的时候,就会显示标签供选择。

打开labelImg
Change Save Dir 为你选择保存XML文件的目录,Open Dir 为你需要标注图片的目录。
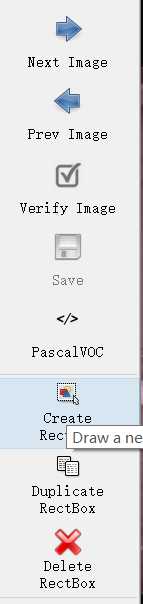
点击Creat RectBox 在图片上画框,选择标签的名字。
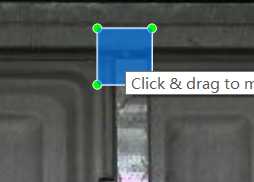
点击Save对其进行保存,点击Next Image选择下一个图片进行处理。
因为我后来又通过高斯模糊、加噪声等方式对图片进行了扩充,需要重新使用labelImg对数据集进行标注,而加入噪声的图片和原始图片分辨率以及框的位置都是不变的,只有文件名需要修改,于是可以通过简单的python脚本对xml文件进行批量修改。我的python脚本如下,仅对我的数据有效(仅供参考)。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#修改文件夹、文件名等内容
import os
import os.path
import sys
from xml.etree.ElementTree import parse, Element
def test():
path="D:/Train_Object_Detection/Python_Rename/labelXml/"
files=os.listdir(path) #得到文件夹下所有文件名称
#s=[]
for xmlFile in files: #遍历文件夹
if not os.path.isdir(xmlFile): #判断是否是文件夹,不是文件夹才打开
print(xmlFile)
pass
path="D:/Train_Object_Detection/Python_Rename/labelXml/"
newStr=os.path.join(path,xmlFile)
dom=parse(newStr) ###最核心的部分,路径拼接,输入的是具体路径
root=dom.getroot()
#print root
part=xmlFile[0:6]
part1=part+sys.argv[2]+'.jpg'
newStr1='D:/Train_Object_Detection/'+part1
#root.remove(root.find('path'))
#e=Element('path')
#print root.find('path').text
root.find('folder').text=sys.argv[1]
root.find('path').text=newStr1
oldName=root.find('filename').text
root.find('filename').text=oldName[0:6]+sys.argv[2]+'.jpg'
# #打印输出
print ('path after change')
#print n0.firstChild.data
# print '修改后的 pose'
# print p0.firstChild.data
# print '~~~~~'
dom.write(newStr, xml_declaration=True)
pass
if __name__=='__main__':
print (sys.argv[1:])
test()(安利!!!)使用《拖把更名器》批量对文件名进行修改。
突然发现有一些别人制作的数据集不正确,在这里我也写了一个脚本对其进行修改。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#新建filename节点 将标记的错误float的数据更改为正确的int数据
import os
import os.path
import sys
from xml.etree.ElementTree import parse, Element
import xml.etree.ElementTree as ET
def test():
path="./data/"
files=os.listdir(path) #得到文件夹下所有文件名称
for xmlFile in files: #遍历文件夹
if not os.path.isdir(xmlFile): #判断是否是文件夹,不是文件夹才打开
print(xmlFile)
pass
path="./data/"
newStr=os.path.join(path,xmlFile)
dom=parse(newStr)
root=dom.getroot()
part=xmlFile[0:5]
part1=part+'.jpg'
print(part1)
element= Element('filename')
element.text=part1
root.append(element)
width = root.find('size').find('width')
new_width = str(int(float(width.text))+1)
width.text= new_width
for obj in root.findall('object'):
xmin = obj.find('bndbox').find('xmin')
ymin = obj.find('bndbox').find('ymin')
xmax = obj.find('bndbox').find('xmax')
ymax = obj.find('bndbox').find('ymax')
new_xmin = str(int(float(xmin.text))+1)
new_ymin = str(int(float(ymin.text))+1)
new_xmax = str(int(float(xmax.text))+1)
new_ymax = str(int(float(ymax.text))+1)
xmin.text = new_xmin
ymin.text = new_ymin
xmax.text = new_xmax
ymax.text = new_ymax
print ('path after change')
dom.write(newStr, xml_declaration=True)
pass
if __name__=='__main__':
print (sys.argv[1:])
test()根据个人设置,将数据集划分为train、val、test等
下面是一个简单的随机划分和批量移动文件脚本
##深度学习过程中,需要制作训练集和验证集、测试集。
##先把JPEG文件扩展名改为 xml,这样就和 annotation一样了,随机种子可以一块给移动了
##之后再重新改回来
import os, random, shutil
def moveFile(XMLfileDir,JPEGfileDir):
XMLpathDir = os.listdir(XMLfileDir) #取xml&图片的原始路径
XMLfilenumber=len(XMLpathDir)
rate=0.2 #自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber=int(XMLfilenumber*rate) #按照rate比例从文件夹中取一定数量图片
random.seed(0)
sample1 = random.sample(XMLpathDir, picknumber) #随机选取picknumber数量的样本图片
random.seed(0)
print (sample1)
print ("```````````````")
for name in sample1:
shutil.move(XMLfileDir+name, XMLtarDir+name)
print (XMLfileDir+name)
shutil.move(JPEGfileDir+name, JPEGtarDir+name)
print (JPEGfileDir+name)
return
if __name__ == '__main__':
XMLfileDir = "./XML_train/" #源xml文件夹路径
XMLtarDir = './XML_val/' #移动到新的文件夹路径
JPEGfileDir = "./JPEG_train/" #源图片文件夹路径
JPEGtarDir = './JPEG_val/' #移动到新的文件夹路径
moveFile(XMLfileDir,JPEGfileDir)制作coco数据集以在Detectron框架上进行数据的训练
标签:shu dna __name__ sample 标记 预处理 append 一个 划分数
原文地址:https://www.cnblogs.com/superfly123/p/11695587.html