标签:sof 技术 深度学习 hot mamicode abs 优化 去除 链接
论文链接:https://arxiv.org/abs/1811.12673
一.对抗样本
对抗样本是指攻击者通过向真实样本中添加人眼不可见的噪声,导致深度学习模型发生预测错误的样本。比如对于一张猫的图片,分类器原本可以正确的识别。如果在图片中加入一些微小的干扰,这些干扰对于人眼来说是分辨出来的,人们依旧可以认出这是一个猫,但是分类器就有很大的可能将其识别成一只狗。

二.用图像压缩抵御对抗样本
人们已经提出了许多抵御对抗样本的方法,如PixelDefend等。这些方法主要分为两类,第一类主要通过增强网络自身的抗干扰能力,比如在训练样本中加入对抗样本,或者把one-hot标签换成soft-targets,但是这样需要重新训练网络。第二类是在对抗图像输入分类器之前,将其转换为清晰的图像。但是这两类方法都存在一个问题,那就是需要用对抗样本进行训练,但是获取对抗样本本身就很麻烦,所以这篇论文提出了用图像压缩的方式来抵御对抗样本,这种模型只需要用clean image进行训练,并不需要对抗样本。
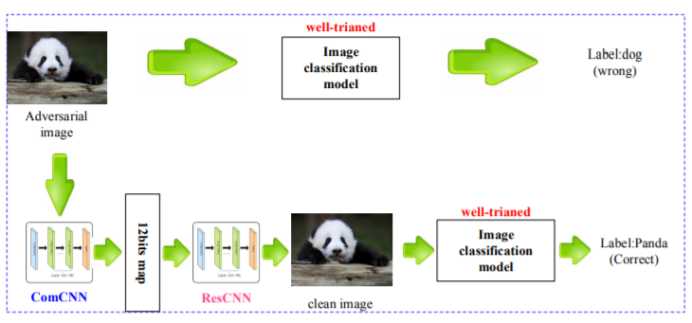
这个模型的思路实质是也是上文提及的第二种方法,在对抗样本进入分类器之前对对抗样本进行净化,得到不含干扰的图像后再宋儒后续的分类器中。具体实现是利用了图像压缩中去除冗余的思想,因为图像压缩重在保存图像的主要信息,去除冗余信息,这样那些对抗干扰就会被作为冗余信息去除掉。而且模型的训练可以和分类器分开进行,并不会影响已经训练好的分类模型。
三.网络结构
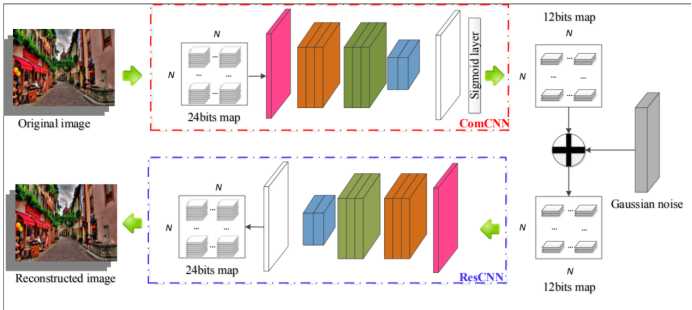
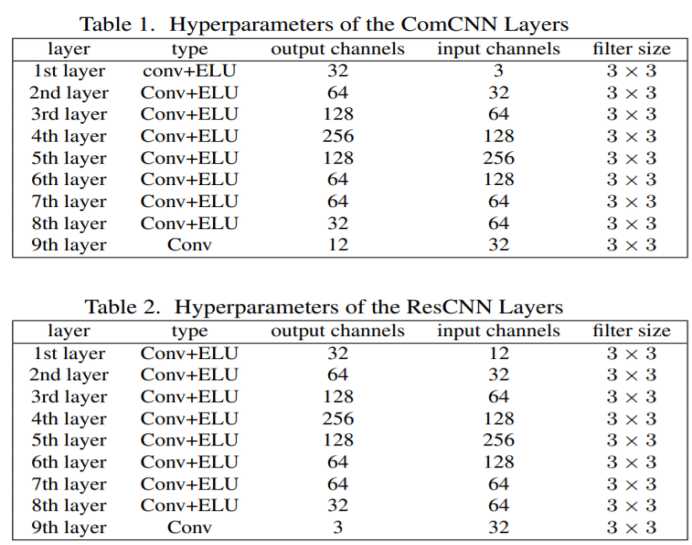
网络分为两个部分,第一个部分是压缩模型ComCNN,第二部分是重建模型ResCNN。每一个网络都又九个卷积层构成,采用conv+ELU的形式,网络的具体参宿如下图所示。
输入图片的每一个像素都是由24bit表示,经过压缩网络后图像的每一个像素只用12bit表示,这样图片就只会保留图片的重要信息,而干扰就会被剔除。然后压缩后的图像再经过重建网络恢复,得到过滤后的干净图像,供后续分类模型使用。
四.损失函数
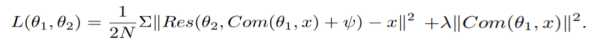
模型在训练过程中同时优化两个网络,所以目标函数中同时包含了两个网络的损失函数,第一部分是重建网络的损失函数,是为了保证图像重建之后的质量,保证在经过压缩后依旧可以得到高质量的图像,com代表压缩网络,ψ代表高斯噪声。

第二部分是压缩网络的损失函数,这里的损失函数和传统的压缩中的损失函数不太一样,传统的损失函数用的一般是信息熵作,这里用的是一个类似L2范数的销量大小来衡量,原文中的解释是让压缩网络得到的编码中尽可能多的位数为0。
五.实验结果
1.超参数的选择
模型中有两个重要的超参数,分别是ψ和λ,这样个超参数是通过实验确定的,具体的实验结果如下:

从实验结果可以看出,当ψ确定时,可以看到在一定范围内准确率随着λ的增加而增加,但是当λ达到一定数值后,再增大反而会使准确率下降。同理在λ固定的时候,变化规律也是先增大后减小,最后通过实验结果看出,最合适的超参数设置为λ=0.0001,ψ=20.0。
2.不同的使用方式
当把模型加入到分类器中时,可以选择直接把抵御模型加在训练好的分类模型上,也可以选择加上抵御模型后在对判别模型进行训练。实验结果如下:
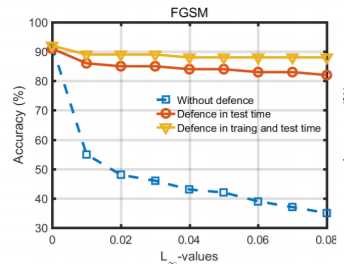
从实验结果中可以看出,不论用哪种方式,加上抵御模型后模型的正确率大幅度的提升,而且进一步比较,可以看出加上抵御模型后再进行训练可以得到更好的结果,作者并没有给出解释,我觉得可能是因为经过压缩后的图像质量会相对变差,所以如果不经处理直接加在判别模型上,必然造成准确率下降。
3.与其他方式的比较
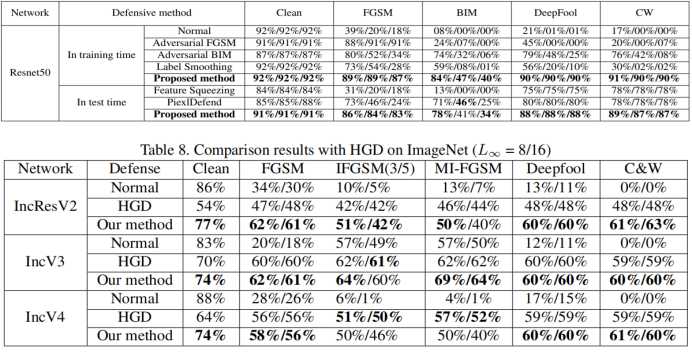
可以看出该模型相比其他方法在抵御对抗样本方面有着很大的提升,但是在ImageNet这种相对复杂的数据集上,可以看出这种方法在面对无干扰的图片时,依旧会造成不小的性能下降。
标签:sof 技术 深度学习 hot mamicode abs 优化 去除 链接
原文地址:https://www.cnblogs.com/bupt213/p/11697453.html