标签:key odi 直接 很多 自己 max col 缓存 set
项目中需要用到redis,业务起来之后用到的地方更多,问题来了,因为操作redis太频繁,导致操作redis成为整个项目的瓶颈,经过调研和比较这时候基于内存的cache登场,简单来说就是纯内存层面的cache,可以实现放上业务流程的对比图,就是在redis之前加了一层,比较redis虽然基于内存但是连接包括操作还是得产生网络io操作
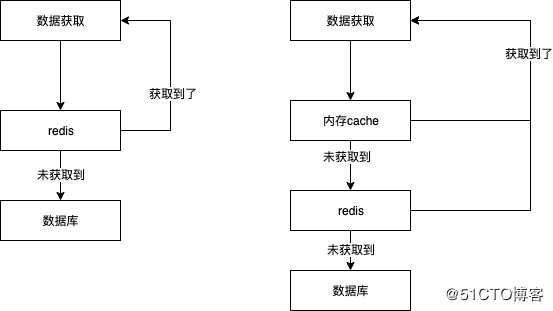
下面是我做的对比测试:
普通数据:
1、假设全部不命中(内存和redis都没有):
[root@master test]# python 6.py
这是100次的结果
内存:[0.006078958511352539, 0.00607609748840332, 0.006433963775634766]
redis:[0.00573420524597168, 0.007025003433227539, 0.005178928375244141]
这是1000次的结果
内存:[0.07438397407531738, 0.07421493530273438, 0.0615389347076416]
redis:[0.04864096641540527, 0.04749107360839844, 0.05013895034790039]
这是10000次的结果
内存:[0.5369880199432373, 0.48474812507629395, 0.4684739112854004]
redis:[0.4230480194091797, 0.5131900310516357, 0.43289995193481445]
这是100000次的结果
内存:[5.565299987792969, 5.5354228019714355, 5.658163070678711]
redis:[4.795120000839233, 5.0205230712890625, 4.469913005828857]
2、假设全部命中:
[root@master test]# python 6.py
这是100次的结果
内存:[0.00040602684020996094, 0.00021195411682128906, 0.00021600723266601562]
redis:[0.005956888198852539, 0.005934000015258789, 0.005537986755371094]
这是1000次的结果
内存:[0.0021610260009765625, 0.0020508766174316406, 0.002026081085205078]
redis:[0.0546720027923584, 0.04969382286071777, 0.04725193977355957]
这是10000次的结果
内存:[0.014709949493408203, 0.01748490333557129, 0.016735076904296875]
redis:[0.500324010848999, 0.6110620498657227, 0.5946261882781982]
这是100000次的结果
内存:[0.20346498489379883, 0.20162200927734375, 0.15467381477355957]
redis:[5.065227031707764, 5.543213844299316, 5.167007207870483]json格式的数据:
1、假设全部不命中:
[root@master test]# python json_test.py
这是100次的结果
内存 [0.00627589225769043, 0.006350040435791016, 0.006167888641357422]
redis [0.00538182258605957, 0.005352973937988281, 0.005239009857177734]
这是1000次的结果
内存 [0.06096196174621582, 0.05894589424133301, 0.0531618595123291]
redis [0.04534316062927246, 0.04644417762756348, 0.042047977447509766]
这是10000次的结果
内存 [0.526871919631958, 0.49242496490478516, 0.54292893409729]
redis [0.46350693702697754, 0.5339851379394531, 0.514045000076294]
这是100000次的结果
内存 [5.3060479164123535, 5.807142972946167, 4.886216163635254]
redis [4.287613153457642, 4.528016090393066, 5.158953905105591]
2、假设全部命中:
[root@master test]# python json_test.py
这是100次的结果
内存 [0.0005319118499755859, 0.0003058910369873047, 0.0002970695495605469]
redis [0.006021022796630859, 0.005857944488525391, 0.006082773208618164]
这是1000次的结果
内存 [0.0028162002563476562, 0.002669811248779297, 0.0026869773864746094]
redis [0.07850098609924316, 0.06138491630554199, 0.05786609649658203]
这是10000次的结果
内存 [0.02676105499267578, 0.026623010635375977, 0.026623010635375977]
redis [0.6534669399261475, 0.6395609378814697, 0.47389698028564453]
这是100000次的结果
内存 [0.20687103271484375, 0.20745611190795898, 0.19935917854309082]
redis [5.537367105484009, 5.8351359367370605, 4.935602903366089]可以看到,当全部不命中(实际情况只有在第一次才会出现,不然也不用加redis了)的情况下,基于内存和基于redis的性能基本相同,但如果命中过之后这个性能就有很大提升了
直接上代码:
#!/usr/bin/env python
# -*- coding:utf8 -*-
‘‘‘
Author : mafei
Date : 2019-09-26
‘‘‘
import time
import weakref
import collections
import ujson as json
class Base(object):
notFound = {}
class Dict(dict):
def __del__(self):
pass
def __init__(self, maxlen=10):
self.weak = weakref.WeakValueDictionary()
self.strong = collections.deque(maxlen=maxlen)
@staticmethod
def now_time():
return int(time.time())
def get(self, key):
v = self.weak.get(key, self.notFound)
if (v is not self.notFound):
expire = v[r‘expire‘]
if (self.now_time() > expire):
self.weak.pop(key)
return self.notFound
else:
return v
else:
return self.notFound
def set(self, key, value):
self.weak[key] = strongRef = Base.Dict(value)
self.strong.append(strongRef)
class MemoryCache(object):
def __init__(self, maxlen=1000 * 10000, life_cycle=5*60):
self.memory_cache = Base(maxlen=maxlen)
self.maxlen = maxlen
self.life_cycle = life_cycle
@staticmethod
def _compute_key(key):
return key
def get(self, k):
memory_key = self._compute_key(k)
result = self.memory_cache.get(memory_key).get(‘result‘, None)
if result is None:
return result
return result
def set(self, k, v, life_cycle=None):
self._set_memory(k, v, life_cycle)
def get_json(self, key):
res = self.get(key)
try:
return json.loads(res)
except:
return res
def set_json(self, k, v, life_cycle=None):
try:
v = json.dumps(v)
except:
pass
self.set(k, v, life_cycle)
def set_with_lock(self, k, v, life_cycle=None):
self._set_memory(k, v, life_cycle)
def _set_memory(self, k, v, life_cycle=None):
life_cycle = life_cycle or self.life_cycle
memory_key = self._compute_key(k)
self.memory_cache.set(memory_key, {‘ip‘: k, r‘result‘: v, r‘expire‘: life_cycle + self.memory_cache.now_time()})
调用时只需要传入2个参数:
maxlen : 内存中最多缓存多少条数据
life_cycle: 数据失效时间
优点:
1、高效,比直接调用redis要快很多
2、不会产生网络io和磁盘io
缺点:
1、支持的结构比较单一,当然这个可以自己扩充方式实现
2、如果要更新内存中的值不太方便,可以有其他方式实现
标签:key odi 直接 很多 自己 max col 缓存 set
原文地址:https://blog.51cto.com/mapengfei/2443553