标签:建立 app 存在 互连 计算机 pen 交换 bbb eve
整篇文章是对作者Russ Cox的文章Regular Expression Matching Can Be Simple And Fast的翻译,在我看来,该文章是入门正则引擎的较好的文章之一,读者在阅读之前,最好有一定的正则表达式的基础。翻译内容仅代表作者观点。侵删
该作者所有的文章的网址在此:https://swtch.com/~rsc/regexp/
现在我们已经有了确定一个正则表达式是否匹配一个字符串的方法,将正则表达式转换为NFA之后以字符串为输入运行该NFA。记住NFA在面对多个选择的下一状态时能够很好地选择下一状态。而使用普通的计算机运行NFA时我们必须找到一个能够模拟这一能力的方法。
一种模拟猜测多种选择的方法是首先选择一个方向进行匹配,如果匹配失败,就选择余下方向中的一个。举个例子,考虑用abab|abbb的NFA去匹配字符串abbb: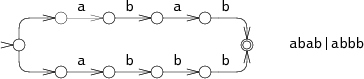
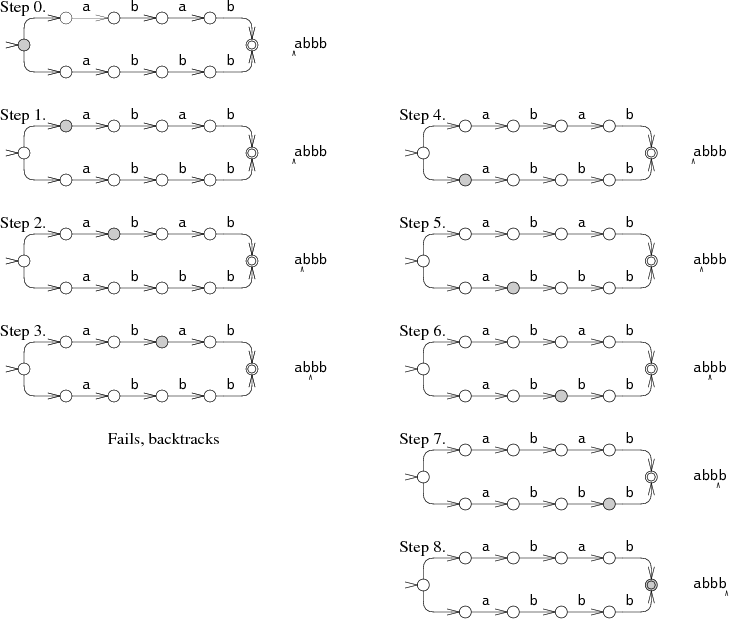
在step0时,NFA就必须做出选择,是去匹配abab或者abbb?在上图中,它首先尝试了abab,但是在step3时失败了。之后NFA选择了另一个方向,进入了step4,最终到达了匹配状态。这种回溯的匹配方式有一种简单的递归的实现方式但是需要在成功匹配之前多次读入字符串。如果这个字符串并不匹配,那状态机在失败之前就会将所有的可能的路径都尝试一遍。 上图中的例子只有两种不同的路径,但是在最坏的情况下可能会有指数级的可能的路径,这会导致非常缓慢的执行时间。
一个更加高效但是更加复杂的的方法去处理多路径的问题是在同一时间处理所有的路径。在这种方法中,整个匹配过程允许状态机在一个时间处于多个状态,为了处理每一个字符,匹配过程会让每一个满足当前字符的状态通过箭头进入下一状态。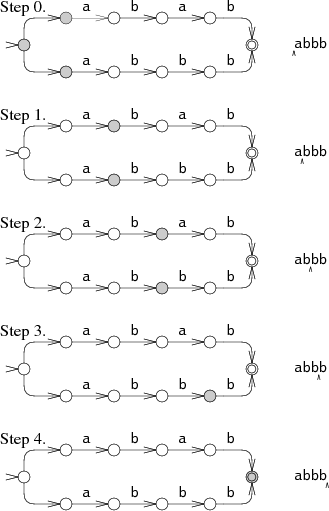
状态机开始时处于初始状态以及所有可以从初始状态通过空箭头到达的状态,在第1、2步,NFA同时处于两个状态。直到第3步NFA才将可能的状态确定到了一个。这种多状态的处理方式会在同时尝试所有的路径,并且只需读取一遍字符串。在最坏的情况下,NFA可能会在每一步中均处于所有的状态,但这也只会导致常数级别的工作量,且与输入的字符串的长度无关,因此任意长度的输入均只有线性的处理时间。相对于那些采用回溯方法从而需要指数级处理时间的实现来说,上述方法是一种巨大的提升。效率的提升来自于我们只会沿着没有走过的路径去到达可以到达的状态。在一个具有n个节点的NFA中,在匹配的每一步状态机最多只有n个可以到达的状态,但是整个NFA中可能会有2n条路径。
Thompson 1968年在他的论文中提出了多个状态同时模拟的匹配方法。在他的构想中,NFA的状态是使用一种机器码片段表示的,而所有的可能的状态的列表只不过是一系列的函数调用的指令。本质上,Thompson将正则表达式编译成了机器码。40年后,计算机的速度大大提高,而采用机器码的这种方法也显得不必要了。接下来的章节我们会介绍一种使用ANSI C编写的实现方式。完整的代码(400行以内)以及所有的测试脚本均被放在了网站上。
实现的第一步是将正则表达式编译成等价的NFA。在我们的C程序中,我们会将NFA表示为一系列相互连接的State结构体:
1 | struct State |
每一个State表示下图中三个中的一个NFA片段,具体取决于c的值。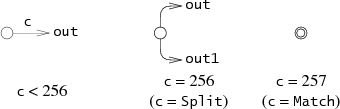
(Lastlist在程序执行时被使用,我们会在下一节中介绍它)
根据Thompson的论文,编译器首先使用(.)作为连接操作符将正则表达式转换为后缀表示形式。一个名叫re2post的函数会将像”a(bb)+a”这样中序表示的正则表达式重写为”abb.+.a.”这样的等价的后缀形式。(而一个真正的正则引擎则会将圆点用作表示任意字符的元字符而不是一个连接操作符。同时一个成熟的正则引擎会在解析表达式时就将NFA构造出来而不是先转换为后缀形式。但是,首先转换的实现方式会更加的方便同时也更贴合Thompson的论文。)
在编译器扫描后缀表达式的过程中,它会维护一个用于保存已经处理过的NFA片段的栈。遇到文字则会把新的NFA片段压入栈中,而遇到操作符时,则会将栈顶的两个片段取出,并压入新的片段。例如,在处理完abb.+.a.中的abb之后,栈保存了a,b,b的NFA片段,而接下来对 . 的处理会将栈中两个b的NFA片段取出,之后压入相互连接的bb的NFA片段。每一个NFA的片段均由开始状态和一个向外指的箭头构成:
1 | struct Frag |
Start指针指向片段(fragment)的开始状态,而out是一系列的State*指针,最初没有指向任何的状态。这些是NFA片段中的空箭头。
一下是一些操作指针列表的函数:
1 | Ptrlist *(State **outp); |
List1函数初始化一个新的只包含指针outp的指针列表。函数Append将两个指针列表连接起来,并返回结果。Patch将列表l中的所有指针与状态s相连。
通过这些简单的定义以及一个片段栈,编译器的代码就是一个围绕着后缀表达式进行的简单的循环。在程序结束之前,还有最后一步:将结束状态与NFA连接起来从而完成整个NFA的构建。
1 | State* post2nfa(char *postfix) |
以下是模拟整个构建过程的详细的代码:
文字字符: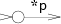
1 | default: |
连接符:
1 | case '.': |
并联(或):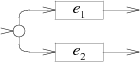
1 | case '|': |
零个或一个: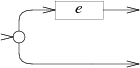
1 | case '?': |
零个或多个: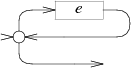
1 | case '*': |
一个或多个: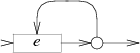
1 | case '+': |
现在NFA已经被建立了起来,我们现在需要运行它。整个运行过程需要我们记录状态的集合,我们将它们存放于一个简单的数组中:
1 | struct List |
运行过程需要两个List:clist是NFA现在正处于的状态的集合,而nlist是NFA在处理完当前的字符之后即将进入的状态的集合。在循环之前clist被初始化为只包含初始状态,之后状态机会一个循环向前推进一步。
1 | int match(State *start, char *s) |
为了避免在每一次循环时都进行初始化,match函数使用两个提前初始化好的list做为clist和nlist,在每一步之后交换两个变量。
如果最后的状态数组里包含了结束状态,那匹配就成功了。
1 | int ismatch(List *l) |
Addstate函数为list添加一个状态,如果已经存在则不添加。如果每一次添加状态都需要扫描整个列表那就太低效了,我们让listid作为记录list每一代的变量。当调用addstate将状态s加入列表时,它会将listid记录到s->lastlist中。如果它们两者已经相等了,那s已经存在于列表中了。Addstate函数同样会沿着空箭头向前走,如果s是一个Split状态并带有两个空箭头到达新的状态,那Addstate会将这些新状态而不是s加入到列表中。
1 | void addstate(List *l, State *s) |
Startlist函数初始化一个只包含初始状态的列表:
1 | List* startlist(State *s, List *l) |
最后,step函数将NFA向前推进一步,它使用当前的列表clist来计算之后一步的列表nlist。
1 | void step(List *clist, int c, List *nlist) |
标签:建立 app 存在 互连 计算机 pen 交换 bbb eve
原文地址:https://www.cnblogs.com/dajunjun/p/11698438.html