标签:lse info 数字 表示 语言 lock 判断 img 需要
一个由1亿个数组成的集合M,数的范围从1~10亿
新来一个数n,如何快速且省内存地判断是否存在M中?
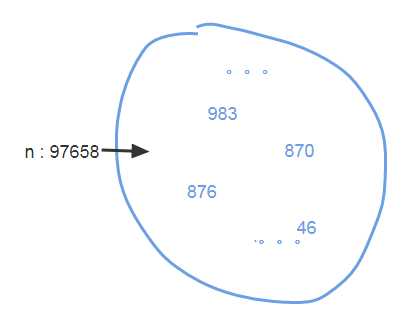
将集合M的数用散列表保存,然后对数n判断是否在散列表中即可
消耗内存:假设一个数用4字节保存,1亿个数至少要381M内存,不过由于实际上由于有装载因子,散列冲突解决等,实际内存远远不止381M

申请一个大小为10亿,数据类型为布尔的“特殊”散列表,将这一亿个数作为散列表下标,将值设成True

不过很多语言的布尔大小是1字节,并不能节省很大空间,实际上只需要使用1个二进制位,来表示true和false两个值就行了。
这就要用到位运算了,借助编程语言提供的数据类型,比如int,char等,通过位运算,用其中的某个位表示某个数字。
这就是位图

消耗大小:约120M
不过位图有个问题,想想看,如果数的范围是1到100亿呢,那位图消耗的大小就是1.2G了!!,相对于散列表,不降反升。
这个时候,总算轮到今天的主角:布隆过滤器登场了,它其实是对位图一种改进。
使用多个哈希函数,得到k个不同的哈希值,记为 x1,x2,x3...xk。将k个数字作为位图中的下标,将对应的值设为1
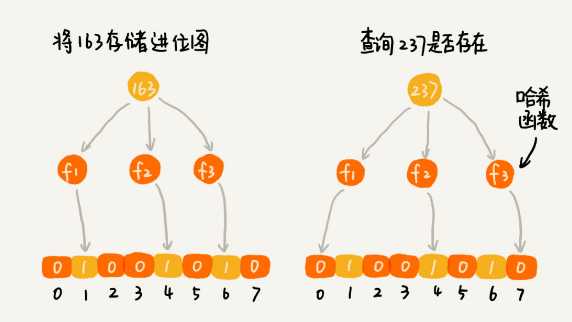
适当选择k个哈希函数,k个哈希值都相同的概率就非常低了,但又会带来新的问题,那就是误判
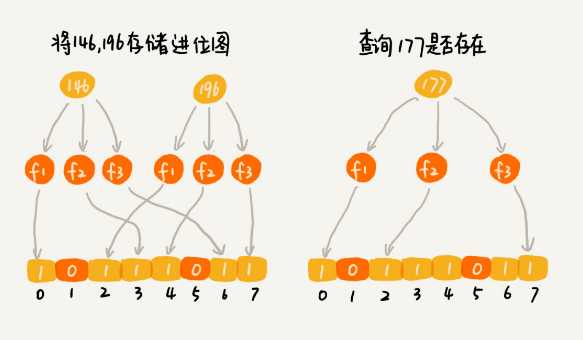
布隆过滤器的误判有个特点:
没有就是没有,有就有极低的可能会没有 :)
标签:lse info 数字 表示 语言 lock 判断 img 需要
原文地址:https://www.cnblogs.com/yeni/p/11699709.html