标签:tpc 卡死 指令 wps dem 设置 jxl aec tap
主要探究了如何对spark源码进行编译,以及普及了一下Maven中的-P,-D的意义以及我在编译过程中遇到的两个坑。为什么需要编译spark源码呢?官网已经提供了预编译的版本了啊,但是如果你对spark源码进行了修改或者spark提供了相对应的hadoop版本不能满足要求,本人编译是因为需要CDH版本的spark,综上所述,最佳实践是对spark源码进行编译。
本次选择的版本是spark2.2.0,需要准备spark2.2.0文档的编译模块(http://spark.apache.org/docs/2.2.0/building-spark.html),Maven3.3.9或者以上版本,JDK8,Spark2.2.0源码(https://archive.apache.org/dist/spark/spark-2.2.0/spark-2.2.0.tgz)。
通过上述准备你已经正确配置好JDK和Maven3.3.9以上版本,且下载好源码,解压后文件目录如下:
可以看到是典型的maven结构:

如何编译?查看官网文档,按照步骤一步步来。
本人最开始在编译的过程中,使用的一款内存为2G的服务器,编译中间就卡死了,建议:内存一定要大,否则编译不成功,通过下面设置Mavne的内存
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
如果弄懂了下列的参数,那么编译就简单了,本节,你会知道Maven中编译的一些知识。
下图是官网提供的一个脚本make-distribution.sh,可以编译成一个可分发的包,便于部署,我们使用这个来部署。

上图中的-Phadoop-2.7,-Phive什么意思?
在Maven中,profile可以让我们定义一系列的配置信息,然后指定其激活条件。这样我们就可以定义多个profile,然后每个profile对应不同的激活条件和配置信息,从而达到不同环境使用不同配置信息的效果。比如说,我们可以通过profile定义在jdk1.5以上使用一套配置信息,在jdk1.5以下使用另外一套配置信息;或者有时候我们可以通过操作系统的不同来使用不同的配置信息,比如windows下是一套信息,linux下又是另外一套信息,等等。下图是一个id为:hadoop-2.7的一个profile,
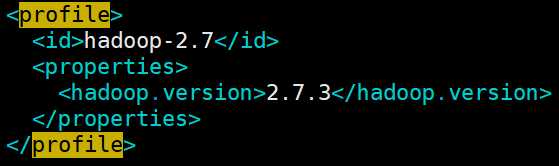
所以,简而言之,可以通过-P+$(profile_id)来显示的指定你需要的profile,本次编译需要hive,hive-thriftserver,yarn等Profile,所在需要指定为:-Phive -Phive-thriftserver -Pyarn
上图中的-D是什么意思?
这是显示的指定的属性值,本次使用的Hadoop版本是:2.6.0-cdh5.7.0,所以通过-Dhadoop.version=2.6.0-cdh5.7.0指定Hadoop版本

最终编译指定为:指定了需要hive,hive-thriftserver,yarn等Profile,指定了Hadoop版本:2.6.0-cdh5.7.0
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phive -Phive-thriftserver -Pyarn -Dhadoop.version=2.6.0-cdh5.7.0
执行上面的指令

2.5 编译成功

3.1 错误了通过-Phadoop-2.6多余指定了Hadoop这个Profile(本人后面指定的Hadoop版本就是2.6,且这个版本在Spark2.2.0是默认的Hadoop版本,不需要显示指定)会出现如下错误:提示hadoop-2.6这个Profile不存在,但是实际编译过程中,并不会让你出现错误。仍然会编译完成,但是编译后的包是不能用的。

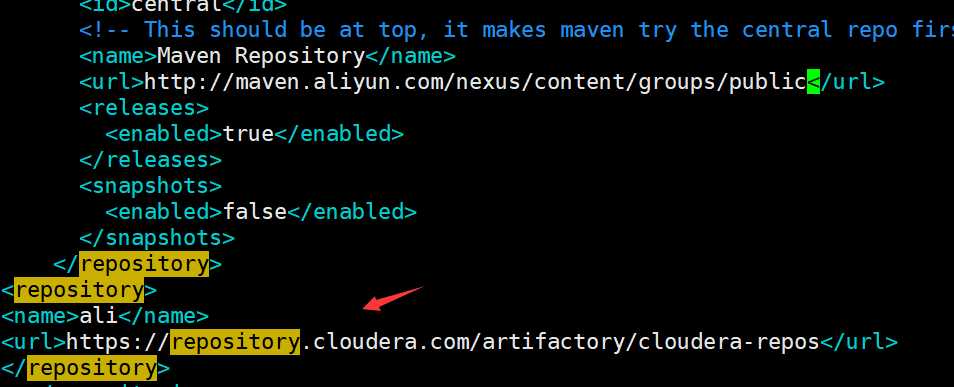
3.2 找不到某个包,很普遍的错误,因为Maven仓库中的确没有这个包。如下:

解决办法:在spark.2.2.0中的pom.xml文件中如下仓库地址:
熟悉Maven和一定要看官网,官网什么都是详细的。
标签:tpc 卡死 指令 wps dem 设置 jxl aec tap
原文地址:https://www.cnblogs.com/truekai/p/11703671.html