标签:一点 ida kde call 用户 triple 停止 str 目标
Project Butter(黄油计划)的特性,包括:
B. 三缓冲支持,改善GPU和CPU之间绘制节奏不一致的问题;
C. 将用户输入,例如touch event,同步到下一个Vsync信号到来时再处理;
D. 预测用户的touch行为,以获得更好的交互响应;
E. 每次用户touch屏幕时,进行CPU Input Boost,以便减少处理延时。
随着时间的推移,Android OS系统一直在不断进化、壮大,日趋完善。但直到Android 4.0问世,有关UI显示不流畅的问题也一直未得到根本解决。在整个进化过程中,Android在Display(显示)系统这块也下了不少功夫,例如,使用硬件加速等技术,但本质原因似乎和硬件关系并不大,因为iPhone的硬件配置并不比那些价格相近的Android机器的硬件配置强,而iPhone UI的流畅性强却是有目共睹的。
从Android 4.1(版本代号为Jelly Bean)开始,Android OS开发团队便力图在每个版本中解决一个重要问题(这是不是也意味着Android OS在经过几轮大规模改善后,开始进入手术刀式的精加工阶段呢?)。作为严重影响Android口碑问题之一的UI流畅性差的问题,首先在Android 4.1版本中得到了有效处理。其解决方法就是本文要介绍的Project Butter。
Project Butter对Android Display系统进行了重构,引入了三个核心元素,即VSYNC、Triple Buffer和Choreographer([?k?r?‘?ɡr?f?(r)] 编舞者)。其中,VSYNC是理解Project Buffer的核心。VSYNC是Vertical Synchronization(垂直同步)的缩写,是一种在PC上已经很早就广泛使用的技术。读者可简单的把它认为是一种定时中断。
接下来,本文将围绕VSYNC来介绍Android Display系统的工作方式。请注意,后续讨论将以Display为基准,将其划分成16ms长度的时间段,在每一时间段中,Display显示一帧数据(相当于每秒60帧)。时间段从1开始编号。
首先是没有VSYNC的情况,如图1所示:
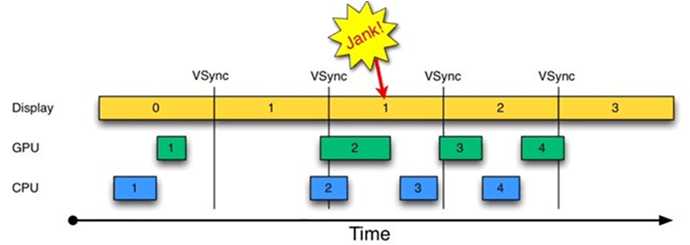
图1 没有VSYNC的绘图过程
由图1可知:
通过上述分析可知,此处发生Jank的关键问题在于,为何第1个16ms段内,CPU/GPU没有及时处理第2帧数据?原因很简单,CPU可能是在忙别的事情(比如某个应用通过sleep固定时间来实现动画的逐帧显示),不知道该到处理UI绘制的时间了。可CPU一旦想起来要去处理第2帧数据,时间又错过了!
为解决这个问题,Project Butter引入了VSYNC,这类似于时钟中断。结果如图2所示:
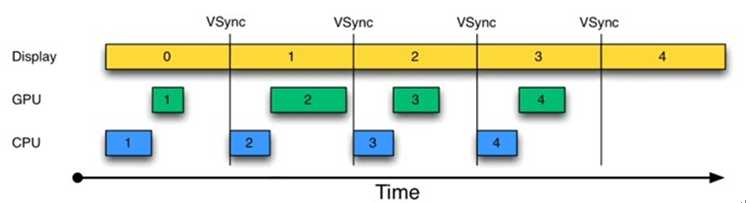
图2 引入VSYNC的绘制过程
由图2可知,每收到VSYNC中断,CPU就开始处理各帧数据。整个过程非常完美。
不过,仔细琢磨图2却会发现一个新问题:图2中,CPU和GPU处理数据的速度似乎都能在16ms内完成,而且还有时间空余,也就是说,CPU/GPU的FPS(帧率,Frames Per Second)要高于Display的FPS。确实如此。由于CPU/GPU只在收到VSYNC时才开始数据处理,故它们的FPS被拉低到与Display的FPS相同。但这种处理并没有什么问题,因为Android设备的Display FPS一般是60,其对应的显示效果非常平滑。
如果CPU/GPU的FPS小于Display的FPS,会是什么情况呢?请看图3:
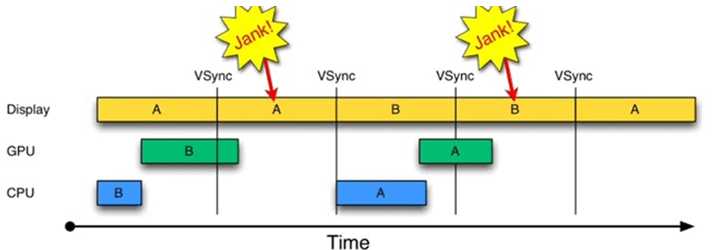
图3 CPU/GPU FPS较小的情况
由图3可知:
为什么CPU不能在第二个16ms处开始绘制工作呢?原因就是只有两个Buffer。如果有第三个Buffer的存在,CPU就能直接使用它,而不至于空闲。出于这一思路就引出了Triple Buffer。结果如图4所示:
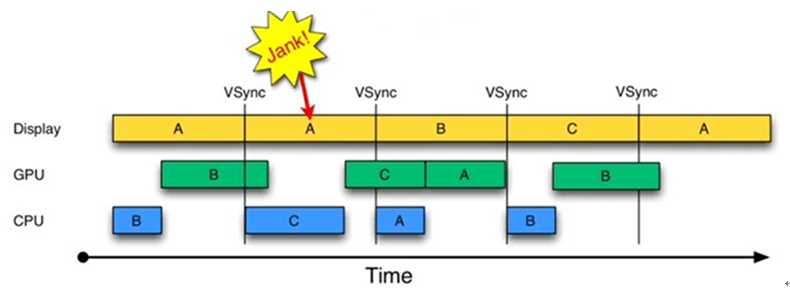
图4 Triple Buffer的情况
由图4可知:
是不是Buffer越多越好呢?回答是否定的。由图4可知,在第二个时间段内,CPU绘制的第C帧数据要到第四个16ms才能显示,这比双Buffer情况多了16ms延迟。所以,Buffer最好还是两个,三个足矣。
介绍了上述背景知识后,下文将分析Android Project Buffer的一些细节。
上一节对VSYNC进行了理论分析,其实也引出了Project Buffer的三个关键点:
下面来看Project Buffer实现的细节。
首先被动刀的是SurfaceFlinger家族成员。目标是提供VSYNC中断。相关类图如图5所示:
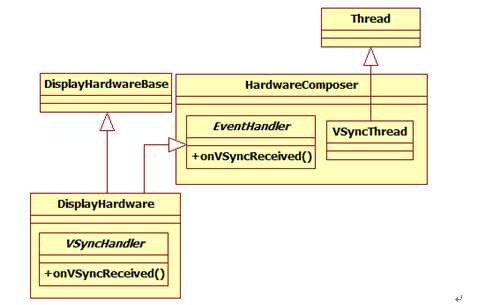
图5 SurfaceFlinger中和VSYNC有关的类
由图5可知:
在SurfaceFlinger家族中,VSyncHandler的实例是EventThread。下边是EventThread类的声明:
class EventThread : public Thread, public DisplayHardware::VSyncHandler
由EventThread定义可知,它本身运行在一个单独的线程中,并继承了VSyncHandler。EventThread的核心处理在其线程函数threadLoop中完成,其处理逻辑主要是:
通过EventThread,VSYNC中断事件可派发给多个该中断的监听者去处理。相关类如图6所示:
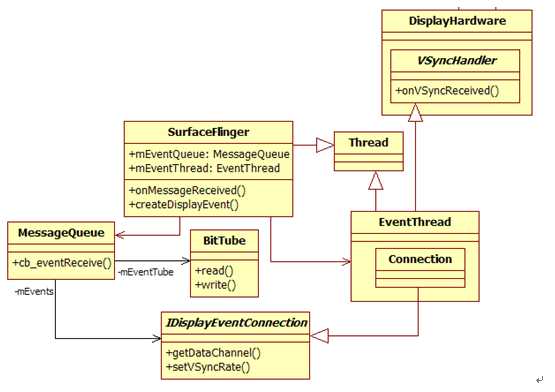
图6 EventThread和VSYNC中断监听者
由图6可知:
EventThread最重要的一个VSYNC监听者就是MessageQueue的mEvents对象。当然,这一切都是为最大的后台老板SurfaceFlinger服务的。来自EventThread的VSYNC中断信号,将通过MessageQueue转化为一个REFRESH消息并传递给SurfaceFlinger的onMessageReceived函数处理。
有必要指出,4.1中SurfaceFlinger onMessageReceived函数的实现仅仅是将4.0版本的SurfaceFlinger的核心函数挪过来罢了[②],并未做什么改动。
以上是Project Buffer对SurfaceFlinger所做的一些改动。那么Triple Buffer是怎么处理的呢?幸好从Android 2.2开始,Display的Page Flip算法就不依赖Buffer的个数,Buffer个数不过是算法的一个参数罢了。所以,Triple Buffer的引入,只是把Buffer的数目改成了3,而算法本身相对于4.0来说并没有变化。图7为Triple Buffer的设置示意图:

图7 Layer.cpp中对Triple Buffer的设置
图7所示,为Layer.cpp中对Buffer个数的设置。TARGET_DISABLE_TRIPLE_BUFFERING宏可设置Buffer的个数。对某些内存/显存并不是很大的设备,也可以选择不使用Triple Buffer。
协调动画,输入和绘图的时间。
Choreographer是一个Java类。第一次看到这个词时,我很激动。一个小小的命名真的反应出了设计者除coding之外的广博的视界。试想,如果不是对舞蹈有相当了解或喜爱,一般人很难想到用这个词来描述它。
Choreographer的定义和基本结构如图8所示:
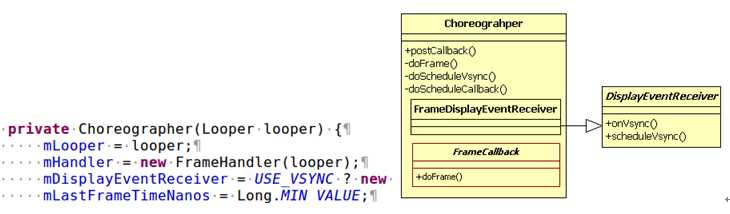
图8 Choreographer的定义和结构
图8中:
Choreographer的主要功能是,当收到VSYNC信号时,去调用使用者通过postCallback设置的回调函数。目前一共定义了三种类型的回调,它们分别是:
优先级高低和处理顺序有关。当收到VSYNC中断时,Choreographer将首先处理INPUT类型的回调,然后是ANIMATION类型,最后才是TRAVERSAL类型。
此外,读者在自行阅读Choreographer相关代码时,还会发现Android对Message/Looper类也进行了一番小改造,使之支持Asynchronous Message和Synchronization Barrier(参照Looper.java的postSyncBarrier函数)。其实现非常巧妙,这部分内容就留给读者自己理解并欣赏了。
相比SurfaceFlinger,Choreographer是Android 4.1中的新事物,下面将通过一个实例来简单介绍Choreographer的工作原理。
假如UI中有一个控件invalidate了,那么它将触发ViewRootImpl的invalidate函数,该函数将最终调用ViewRootImpl的scheduleTraversals。其代码如图9所示:
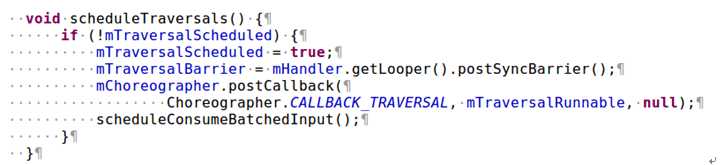
图9 ViewRootImpl scheduleTraversals函数的实现
由图9可知,scheduleTraversals首先禁止了后续的消息处理功能,这是由设置Looper的postSyncBarrier来完成的。一旦设置了SyncBarrier,所有非Asynchronous的消息便将停止派发。
然后,为Choreographer设置了CALLBACK类型为TRAVERSAL的处理对象,即mTraversalRunnable。
最后调用scheduleConsumeBatchedInput,这个函数将为Choreographer设置了CALLBACK类型为INPUT的处理对象。
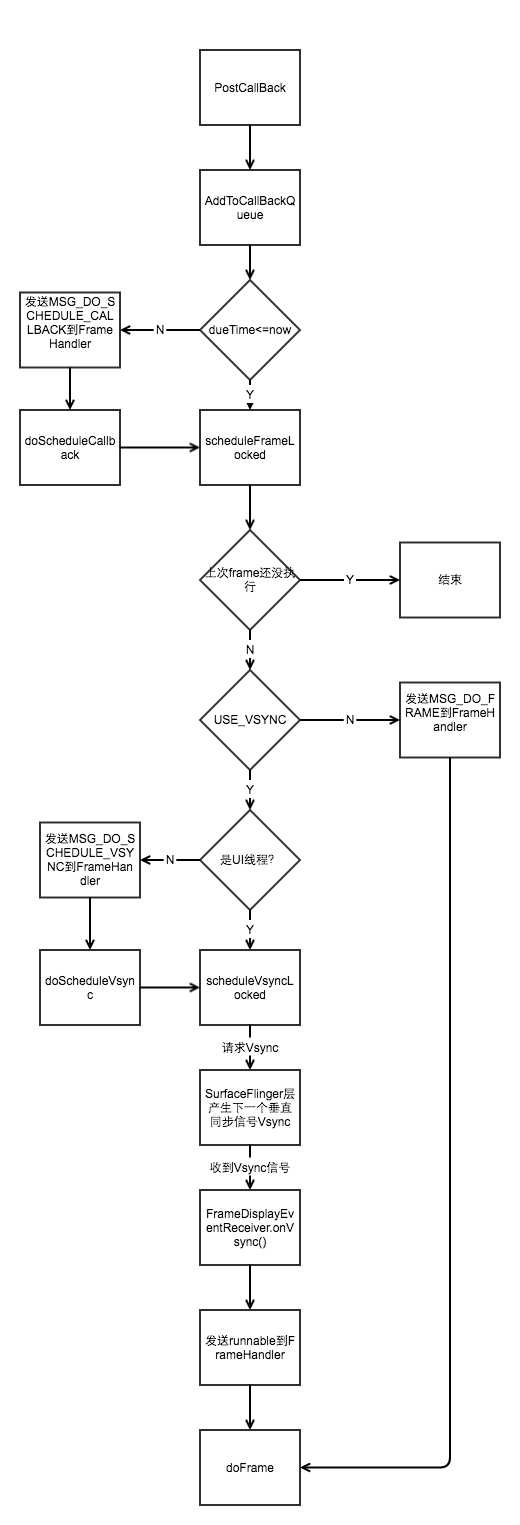
Choreographer的postCallback函数将会申请一次VSYNC中断(通过调用DisplayEventReceiver的scheduleVsync实现)。当VSYNC信号到达时,Choreographer doFrame函数被调用,内部代码会触发回调处理。代码片段如图10所示:

图10 Choreographer doFrame函数片段
对ViewRootImpl来说,其TRAVERSAL回调对应的处理对象,就是前面介绍的mTraversalRunnable,它的代码很简单,如图11所示:

图11 mTraversalRunnable的实现
doTraversal内部实现和Android 4.0版本一致。故相比于4.0来说,4.1只是把doTraversal调用位置放到VSYNC中断处理中了。
通过上边的介绍,可知Choreographer确实做到了对绘制工作的统一安排,不愧是个长于统筹安排的"舞蹈编导"。
本文通过对Android Project Butter的分析,向读者介绍了VSYNC原理以及Android Display系统的实现。除了VSYNC外,Project Butter还包括其他一些细节的改进,例如避免重叠区域的绘制等。
简言之,Project Butter从本质上解决了Android UI不流畅的问题,而且从Google I/O给出的视频来看,其效果相当不错。但实际上它对硬件配置还是有一定要求的。因为VSYNC中断处理的线程优先级一定要高,否则EventThread接收到VSYNC中断,却不能及时去处理,那就丧失同步的意义了。所以,笔者估计目前将有一大批单核甚至双核机器无法尝到Jelly Bean了。
view.invalidate-->viewgroup.invalidateChildInParent-->...-->ViewRootImpl.invalidateChild-->ViewRootImpl.scheduleTraversals
void scheduleTraversals() { if (!mTraversalScheduled) { mTraversalScheduled = true; mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier(); mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null); if (!mUnbufferedInputDispatch) { scheduleConsumeBatchedInput(); } notifyRendererOfFramePending(); pokeDrawLockIfNeeded(); } } final class TraversalRunnable implements Runnable { @Override public void run() { doTraversal(); } } void unscheduleTraversals() { if (mTraversalScheduled) { mTraversalScheduled = false; mHandler.getLooper().removeSyncBarrier(mTraversalBarrier); mChoreographer.removeCallbacks(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null); } } void doTraversal() { if (mTraversalScheduled) { mTraversalScheduled = false; mHandler.getLooper().removeSyncBarrier(mTraversalBarrier); if (mProfile) { Debug.startMethodTracing("ViewAncestor"); } Trace.traceBegin(Trace.TRACE_TAG_VIEW, "performTraversals"); try { performTraversals(); } finally { Trace.traceEnd(Trace.TRACE_TAG_VIEW); } if (mProfile) { Debug.stopMethodTracing(); mProfile = false; } } }
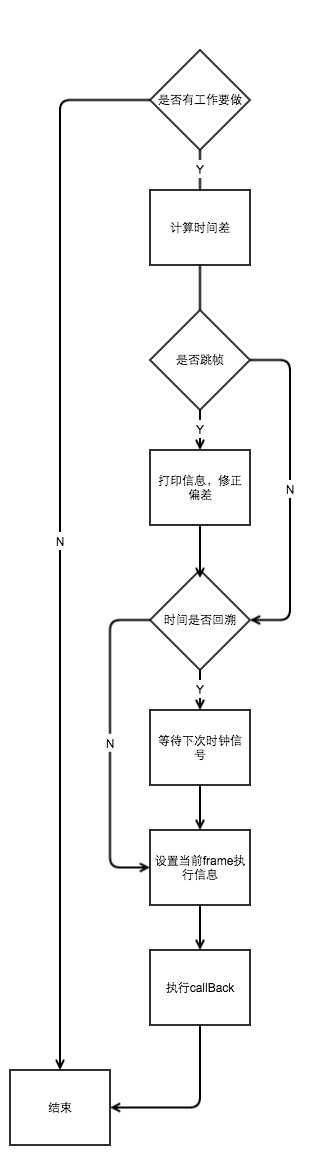
private final class FrameHandler extends Handler { public FrameHandler(Looper looper) { super(looper); } @Override public void handleMessage(Message msg) { switch (msg.what) { case MSG_DO_FRAME: doFrame(System.nanoTime(), 0); break; case MSG_DO_SCHEDULE_VSYNC: doScheduleVsync(); break; case MSG_DO_SCHEDULE_CALLBACK: doScheduleCallback(msg.arg1); break; } } } private void postCallbackDelayedInternal(int callbackType, Runnable action, Object token, long delayMillis) { synchronized (mLock) { final long now = SystemClock.uptimeMillis(); final long dueTime = now + delayMillis; mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token); if (dueTime <= now) {//如果处理时间到了,就直接发出下一帧处理请求 scheduleFrameLocked(now); } else {// 如果处理时间未到,则或一段时间在发送请求 Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action); msg.arg1 = callbackType; msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, dueTime); } } } void doScheduleCallback(int callbackType) { synchronized (mLock) { if (!mFrameScheduled) { final long now = SystemClock.uptimeMillis(); if (mCallbackQueues[callbackType].hasDueCallbacksLocked(now)) { scheduleFrameLocked(now); } } } } private void scheduleFrameLocked(long now) { if (!mFrameScheduled) {//如果没有请求过,则请求 mFrameScheduled = true; if (USE_VSYNC) { if (DEBUG_FRAMES) { Log.d(TAG, "Scheduling next frame on vsync."); } // If running on the Looper thread, then schedule the vsync immediately, // otherwise post a message to schedule the vsync from the UI thread as soon as possible. if (isRunningOnLooperThreadLocked()) { scheduleVsyncLocked(); } else { Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC); msg.setAsynchronous(true); mHandler.sendMessageAtFrontOfQueue(msg); } } else { final long nextFrameTime = Math.max(mLastFrameTimeNanos / TimeUtils.NANOS_PER_MS + sFrameDelay, now); if (DEBUG_FRAMES) { Log.d(TAG, "Scheduling next frame in " + (nextFrameTime - now) + " ms."); } Message msg = mHandler.obtainMessage(MSG_DO_FRAME); msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, nextFrameTime); } } } void doScheduleVsync() { synchronized (mLock) { if (mFrameScheduled) { scheduleVsyncLocked(); } } } // 申请一次VSYNC中断,当下一帧刷新的时候会回调mDisplayEventReceiver的onVsync(); // 而回调onVsync的线程肯定非ui线程,否则的话如果MessageQueue处于阻塞状态,即ui线程处于阻塞状态肯定没法运行 private void scheduleVsyncLocked() { mDisplayEventReceiver.scheduleVsync(); } private final class FrameDisplayEventReceiver extends DisplayEventReceiver implements Runnable { @Override public void onVsync(long timestampNanos, int builtInDisplayId, int frame) { mTimestampNanos = timestampNanos; mFrame = frame; Message msg = Message.obtain(mHandler, this); msg.setAsynchronous(true); mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS); } @Override public void run() { mHavePendingVsync = false; doFrame(mTimestampNanos, mFrame); } } void doFrame(long frameTimeNanos, int frame) { mFrameScheduled = false; ... doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos); doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos); } void doCallbacks(int callbackType, long frameTimeNanos) { CallbackRecord callbacks; synchronized (mLock) { // We use "now" to determine when callbacks become due because it‘s possible // for earlier processing phases in a frame to post callbacks that should run // in a following phase, such as an input event that causes an animation to start. final long now = System.nanoTime(); callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(now / TimeUtils.NANOS_PER_MS); if (callbacks == null) { return; } mCallbacksRunning = true; ... } try { // 从头遍历到尾,执行run for (CallbackRecord c = callbacks; c != null; c = c.next) { c.run(frameTimeNanos); } } finally { synchronized (mLock) { mCallbacksRunning = false; do { final CallbackRecord next = callbacks.next; recycleCallbackLocked(callbacks); callbacks = next; } while (callbacks != null); } } }
!结合 framework下的 深入理解控件树的绘制 的文档一起看!
animator 是CALLBACK_ANIMATION
Animator.start()-->AnimationHandler.scheduleAnimation private void scheduleAnimation() { if (!mAnimationScheduled) { mChoreographer.postCallback(Choreographer.CALLBACK_ANIMATION, mAnimate, null); mAnimationScheduled = true; } } // Called by the Choreographer. final Runnable mAnimate = new Runnable() { @Override public void run() { mAnimationScheduled = false; // 里面处理每一帧动画,在最后再次scheduleAnimation doAnimationFrame(mChoreographer.getFrameTime()); } };
当vsync信号到来时,Choreographer就会执行doFrame里的几个操作(input,animation,traversals),
当执行到animation类型的callback时,就会回调doAnimationFrame,在doAnimationFrame里会根据设置来改变动画值,
然后会回调监听animationUpdate,我们一般会改变对应的属性值,并invalidate,此时就会出发一次scheduleTraversals,把此次的callback加入Choreographer对应队列数组中,
当执行完animation类型的callback后,就会执行traversals类型的callback,把traversals类型的callback一个一个的从队列中取出执行。
在doAnimationFrame最后如果动画没完,则会继续scheduleAnimation。
这就是为什么animation要在traversals的前边。
// 把invalidate放在 CALLBACK_ANIMATION 中操作,
// 所以在view的绘制时如果调用了invalidate的话就会在之后的 CALLBACK_TRAVERSAL 中直接执行,而不会等到下一帧时才执行,这样的话就能充分利用此次的帧绘制时间,从而加快绘制。
public void postInvalidateOnAnimation() { // We try only with the AttachInfo because there‘s no point in invalidating // if we are not attached to our window final AttachInfo attachInfo = mAttachInfo; if (attachInfo != null) { attachInfo.mViewRootImpl.dispatchInvalidateOnAnimation(this); } }
// 把自定义的操作放到 CALLBACK_ANIMATION 中处理。
public void postOnAnimation(Runnable action) { final AttachInfo attachInfo = mAttachInfo; if (attachInfo != null) { attachInfo.mViewRootImpl.mChoreographer.postCallback( Choreographer.CALLBACK_ANIMATION, action, null); } else { // Assume that post will succeed later ViewRootImpl.getRunQueue().post(action); } }
无论是用纯java代码构建Animation对象,还是通过xml文件定义Animation,其实最终的结果都是
Animation a = new AlphaAnimation(); Animation b = new ScaleAnimation(); Animation c = new RotateAnimation(); Animation d = new TranslateAnimation();
分别是透明度,缩放,旋转,位移四种动画效果。
而我们使用的时候,一般是用这样的形式:
View.startAnimation(a);
那么就来看看View中的startAnimation()方法。
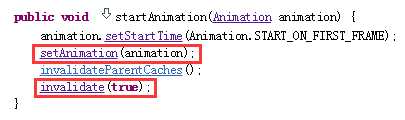
先是调用View.setAnimation(Animation)方法给自己设置一个Animation对象,这个对象是View类中的一个名为mCurrentAnimation的成员变量。
然后它调用invalidate()来重绘自己。
我想,既然setAnimation()了,那么它要用的时候,肯定要getAnimation(),找到这个方法在哪里调用就好了。于是通过搜索,在View.draw(Canvas, ViewGroup, long)方法中发现了它的调用,代码片段如下:
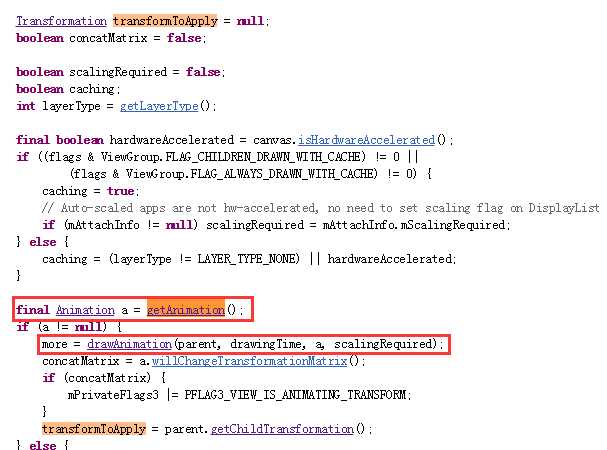
其中调用了View.drawAnimation()方法。
代码片段如下:
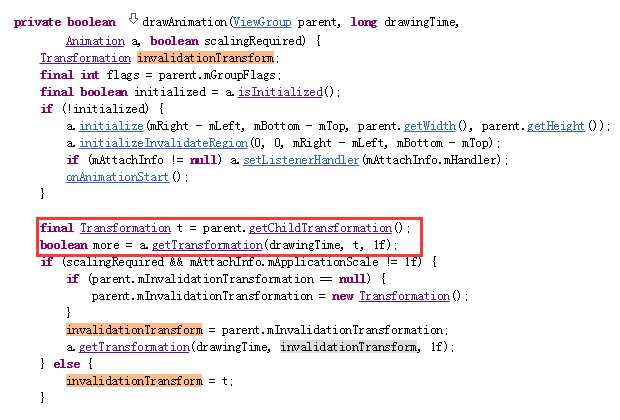
其中调用了Animation.getTransformation()方法。
该方法直接调用了两个参数Animation.getTransformation()方法。

该方法先将参数currentTime处理成一个float表示当前动画进度,比如说,一个2000ms的动画,已经执行了1000ms了,那么进度就是0.5或者说50%。

然后将进度值传入插值器(Interpolator)得到新的进度值,前者是均匀的,随着时间是一个直线的线性关系,而通过插值器计算后得到的是一个曲线的关系。
然后将新的进度值和Transformation对象传入applyTranformation()方法中。
Animation的applyTransformation()方法是空实现,具体实现它的是Animation的四个子类,而该方法正是真正的处理动画变化的过程。分别看下四个子类的applyTransformation()的实现。
ScaleAnimation

AlphaAnimation

RotateAnimation

TranslateAnimation

可见applyTransformation()方法就是动画具体的实现,系统会以一个比较高的频率来调用这个方法,一般情况下60FPS,是一个非常流畅的画面了,也就是16ms,为了验证这一点,我在applyTransformation方法中加入计算时间间隔并打印的代码进行验证,代码如下:

最终得到的log如下图所示:
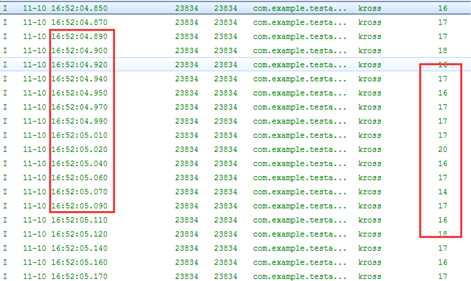
右侧是"手动"计算出来的时间差,有一定的波动,但大致上是16-17ms的样子,左侧是日志打印的时间,时间非常规则的相差20ms。
于是,根据以上的结果,可以得出以下内容:
1.首先证明了一点,Animation.applyTransformation()方法,是动画具体的调用方法,我们可以覆写这个方法,快速的制作自己的动画。
2.另一点,为什么是16ms左右调用这个方法呢?是谁来控制这个频率的?
对于以上的疑问,我有两个猜测:
1.系统自己以postDelayed(this, 16)的形式调用的这个方法。
2.系统一个死循环疯狂的调用,运行一系列方法走到这个位置的间隔刚好是16ms左右,如果主线程卡了,这个间隔就变长了。
在4.1之前是使用handler,4.1之后使用的是VSYNC
https://www.jianshu.com/p/9b14bf15ddaf
1.1.Project Butter,ui绘制原理,动画原理
标签:一点 ida kde call 用户 triple 停止 str 目标
原文地址:https://www.cnblogs.com/muouren/p/11704754.html