标签:lua ack 数据 zipkin rom ase poi http协议 sky
微服务中的监控分根据作用领域分为三大类,Logging,Tracing,Metrics。
Logging - 用于记录离散的事件。例如,应用程序的调试信息或错误信息。它是我们诊断问题的依据。比如我们说的ELK就是基于Logging。
Metrics - 用于记录可聚合的数据。例如,队列的当前深度可被定义为一个度量值,在元素入队或出队时被更新;HTTP 请求个数可被定义为一个计数器,新请求到来时进行累。prometheus专注于Metrics领域。
Tracing - 用于记录请求范围内的信息。例如,一次远程方法调用的执行过程和耗时。它是我们排查系统性能问题的利器。最常用的有Skywalking,ping-point,zipkin。
今天我们主要聊聊Prometheus的监控,接下来我们了解下需要涉及的几个关键组件。
Prometheus(中文名:普罗米修斯)是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB). Prometheus使用Go语言开发, 是Google BorgMon监控系统的开源版本。
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态, 任意组件只要提供对应的HTTP接口就可以接入监控. 不需要任何SDK或者其他的集成过程。输出被监控组件信息的HTTP接口被叫做exporter,目前开发常用的组件大部分都有exporter可以直接使用, 比如Nginx、MySQL、Linux系统信息、Mongo、ES等
prometheus可以理解为一个数据库+数据抓取工具, 工具从各处抓来统一的数据, 放入prometheus这一个时间序列数据库中. 那如何保证各处的数据格式是统一的呢?就是通过这个exporter. Exporter是一类数据采集组件的总称. Exporter负责从目标处搜集数据, 并将其转化为Prometheus支持的格式, 它开放了一个http接口(以便Prometheus来抓取数据). 与传统的数据采集组件不同的是, Exporter并不向中央服务器发送数据, 而是等待中央服务器(如Prometheus等)主动前来抓取。https://github.com/prometheus 有很多写好的exporter,可以直接下载使用。
Grafana是一个图形化工具, 它可以从很多种数据源(例如Prometheus)中读取数据信息, 使用很漂亮的图表来展示数据, 并且有很多开源的dashborad可以使用,可以快速地搭建起一个非常精美的监控平台。它与Prometheus的关系就类似于Kibana与ElasticSearch。
在开始配置之前请下载以下几个软件(直接从github或者grafana官网下载太慢了,简直是龟速而且容易下载失败,建议使用迅雷下载)。
准备两台服务器,一台用作安装prometheus和grafana,一台用作放置exporter组件。建立应用文件夹,将相关软件上传至服务器。
使用如下shell命令进行安装并启动
tar zxvf prometheus-2.13.1.linux-amd64.tar.gz
mv prometheus-2.13.1.linux-amd64 prometheus
cd prometheus
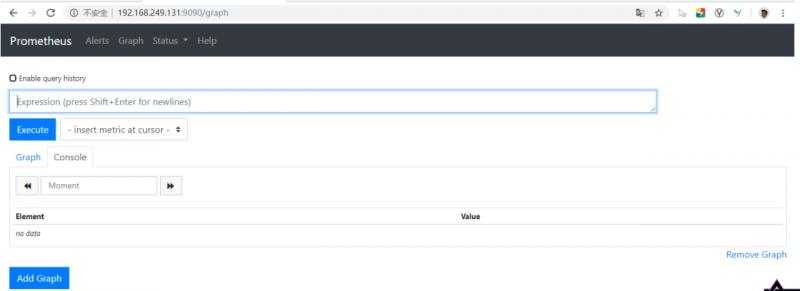
nohup ./prometheus &启动完成后,用浏览器打开http://192.168.249.131:9090进行访问,效果如下:
使用如下shell命令进行安装并启动
tar grafana-6.4.3.linux-amd64.tar.gz
cd grafana-6.4.3
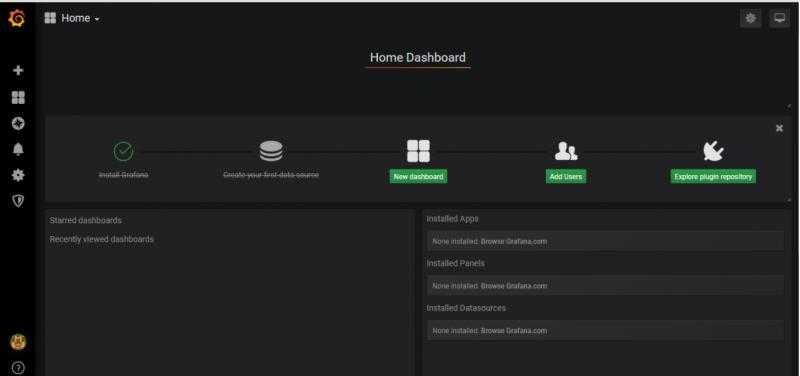
nohup ./grafana-server &启动完成后,用浏览器打开http://192.168.249.131:3000进行访问,默认账号密码为admin/admin,初次登陆需要修改密码,修改密码并登陆效果如下:
使用如下shell命令进行安装并启动
tar zxvf node_exporter-0.18.1.linux-amd64.tar.gz
mv node_exporter-0.18.1.linux-amd64 node_exporter
nohup ./node_exporter &node exporter默认使用9100端口,可以使用--web.listen-address=":9200"指定端口号。
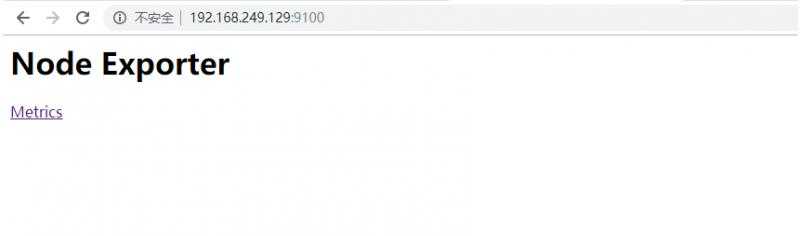
启动完成后,用浏览器打开http://192.168.249.129:9100/进行访问,显示效果如下:
进入prometheus安装目录,修改prometheus.yml文件,增加监听job server-192.168.249.129,完整配置如下:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: '192.168.249.129'
static_configs:
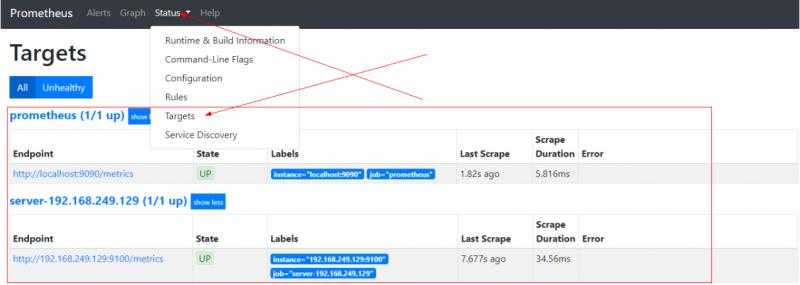
- targets: ['192.168.249.129:9100']配置完成后重启prometheus,查看监听状态。
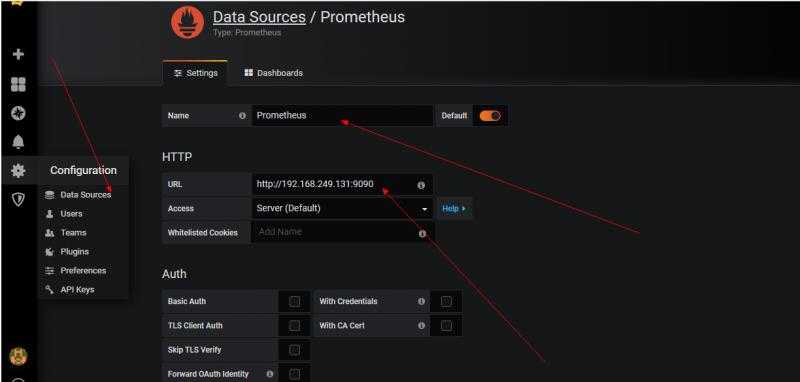
配置prometheus数据源
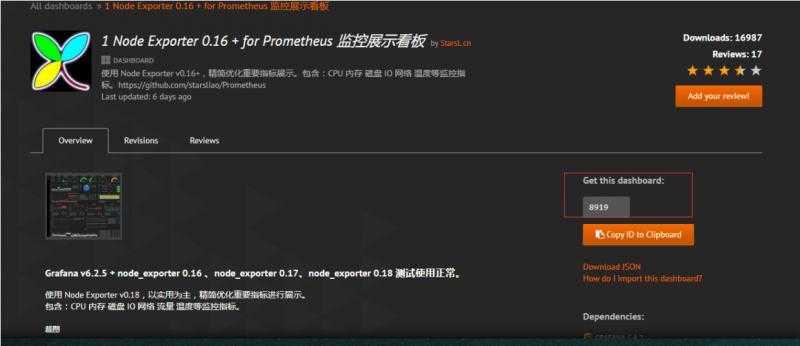
去官网寻找对应的表盘,我们选择node exporter监控看板
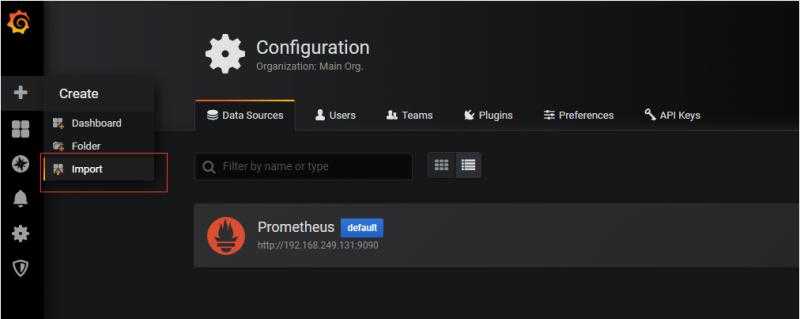
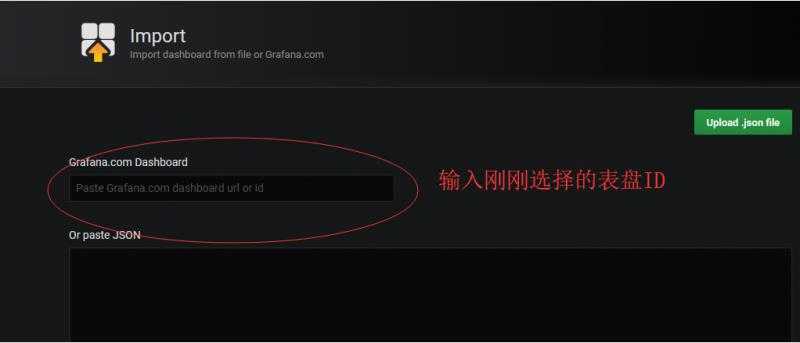
在grafana中在导入表盘
查看监控效果
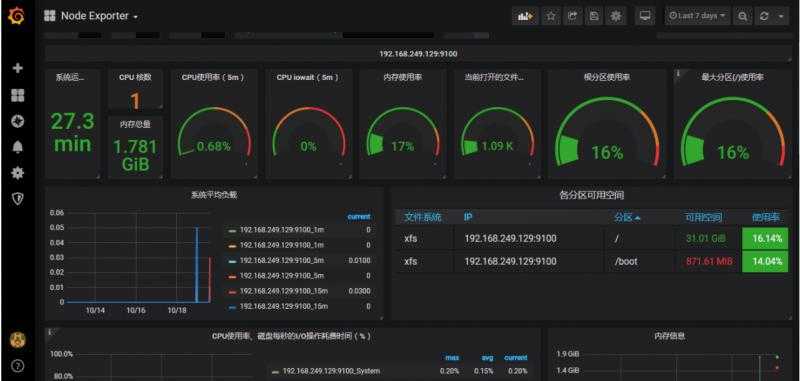
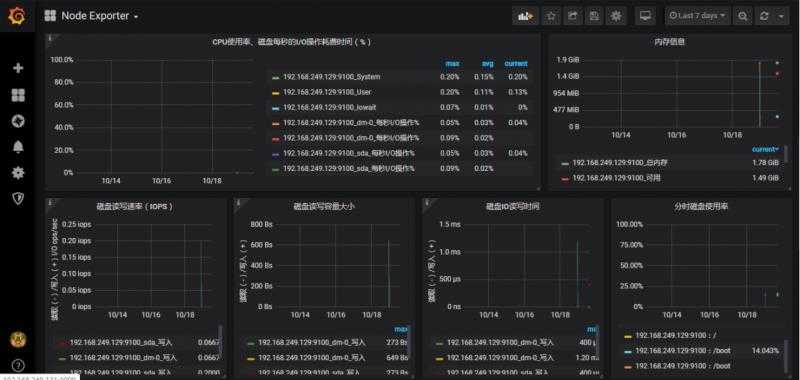
至此基于Prometheus的监控环境搭建完成,你也来动手试一下吧。
近期热文
请关注个人公众号:JAVA日知录

基于Prometheus和Grafana的监控平台 - 环境搭建
标签:lua ack 数据 zipkin rom ase poi http协议 sky
原文地址:https://www.cnblogs.com/jianzh5/p/11706778.html