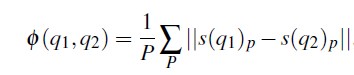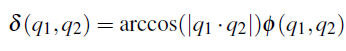标签:下采样 卷积 sed 函数 很多 需要 创新 raw 图片
简介
本文作者提出新的框架(MTTM),使用模板匹配来完成多个任务,从深度图的模板上找到目标物体,通过比较模板特征图与场景特征图来预测分割mask和模板与检测物体之间的位姿变换。作者提出的特征网络通过模板与剪裁特征的对比来计算分割mask,预测位姿。通过实验表明尽管只使用深度图,但是效果很好。
论文针对生活中见到的物体,但是数据集或者CAD模型并不能覆盖所有物体,这样就需要额外的训练时间和新物体的样本图像来重新训练。而基于CNN的局部或全局描述符使用合成渲染图像和少量的真实图像训练之后,对于新物体则不需要重新训练,也不需要GPU。
创新点
最新的研究表明物体的几何信息比纹理信息更重要,因为生活中很多物体都可以使用相同形状的模板来表示。因此可以仅使用深度信息来检索具有相同几何形状和方向的最近邻模板。有点像NOCS里面提到的使用一个标准化的模型,通过对模型的缩放来表示相同的物体。而且深度图像对不同的光照条件和环境具有更强的鲁棒性。所以可以使用综合渲染图像进行训练。
1.提出一个新的基于深度的框架——MTTM,通过与模板进行近邻匹配,使用共享的特征图来预测分割mask和物体的位姿。
3.这种方法优于使用RGB的baseline方法。
上图为遮挡数据集上的效果,上面为给定ROI中心的分割结果,下面为使用近邻模板和五次ICP细化得到的物体位姿。
方法
1.渲染噪声深度图:与之前的工作相比,作者只使用合成图像进行训练,所以可以应用于任何没有足够训练数据的领域。通过模拟摄像机来呈现有噪声的深度图像,从而不需要真实的图像或任何额外的噪声增强。
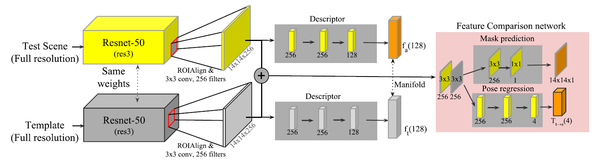
2.网络结构:在预测目标物体分割mask、最近邻模板到场景中物体位姿变换的同时,网络提取测试场景中感兴趣区域的特征描述符来检索最近邻模板。
如上图所示,使用Resnet-50作为骨干网络,用Imagenet数据集上训练的权重进行初始化。原始网络需要三通道的彩色图像作为输入,而深度图为单通道,需要将深度图像转换成三通道的图像。所以作者使用曲面法线的x、y、z分量作为像素的每个通道。将Resnet-50的第三个残差块的输出作为给定输入图像的特征图,通过增加带有256个滤波器的3×3卷积层来减少特征图的维数。与MaskRCNN一样使用双线性插值来剪裁特征图。
每个特征图用于多个任务:提取用于流行学习的描述符,预测mask以及使用成对的特征图进行位姿回归。描述符用全连接层进行计算,滤波器大小为256、256、128,最后一层为线性激活,其余层均为elu激活。
由一个场景和一个模板组成的一对ROI特征图,分别使用256个滤波器进行3×3卷积,然后按通道级联特征图。因此连接后的特征图的输出维度为14×14×512。在特征比较网络中,将合并后的特征图分别用于mask预测和位姿回归。在mask预测中,使用一个具有256个滤波器的3×3卷积层和一个具有sigmoid激活函数的单通道输出的1×1卷积层来表示逐像素的mask预测。对于位姿回归,全连接层的最后一层使用双曲线正切作为激活函数,得到四元数对的位姿差。
3.多任务学习网络:相似位姿间特征向量的距离应小于不同物体或不同位姿之间的距离。与之前使用剪裁图像块的论文相比,作者计算整个场景的特征图来剪裁每个ROI的特征图。对于包含多个物体的训练场景,为每个物体分配正负模板,正模板从同一类中最接近的五个模板中选择,负模板从不同类别或者同一物体的不同位姿中随机选择,一半来自相同类别,一半来自不同类别。
q是物体位姿的旋转四元数。当位姿距离大于正模板时,作为负模板。
4.目标检测和位姿假设生成:在输入场景中,对中心像素进行均匀采样,生成具有固定空间大小的ROI区域。采样点p的ROI区域宽度和高度用w来表示。 
d为每个采样点的深度值,f为焦距,Ssize为覆盖三维空间中目标物体的最大尺寸。将物体的长宽比和空间比例保存在特征图中。计算每个ROI区域的特征向量,并使用Kd-Tree搜索在欧式空间中找到近邻模板,并计算特征距离。
从匹配步骤开始,选择距离近邻模板较近的ROI来预测分割mask,然后使用预先计算的模板特征图对所选的ROI预测mask。每个来自特征比较网络的分割mask都被调整为原来大小。为了消除冗余的预测mask,采用非极大抑制算法合并重叠mask。然后使用预测的分割mask过滤特征图中的背景,与改进的模板再次匹配。然后估计最终的mask和位姿。
5.后处理过程:如果给定目标物体的CAD模型,可以得到每个假设的精确渲染,后处理过程很容易。在没有CAD模型的情况下,使用深度图像和一组模板来获得最佳的位姿结果很有挑战性。所以作者使用CAD模型来评估生成的位姿,细化预测的位姿。
如果在使用下采样点进行三次ICP迭代后,预测的分割mask与第一个位姿假设的渲染区域之间的重叠小于30%,则移除该区域。将剩余区域内的假设迭代细化,并对其进行评估。
渲染深度图与场景之间的不同由内点数量  ,遮挡点数量
,遮挡点数量  ,离群点 数量
,离群点 数量 ,渲染模型点数量
,渲染模型点数量  计算得到。异常值的惩罚项为:
计算得到。异常值的惩罚项为:  ,因此深度适合度为:
,因此深度适合度为:  ,重叠边界点的比率为
,重叠边界点的比率为  ,匹配表面法线的比率为
,匹配表面法线的比率为  ,最后的分数为:
,最后的分数为:  ,用来过滤错误的检测,选择最佳的预测。
,用来过滤错误的检测,选择最佳的预测。
实验和结果
1.分割的评价:
MTTM的优点是可以预测分割mask,而不需要将目标与场景对齐,因此可以评估分割性能。为了注释数据集上的分割mask,使用ground truth位姿来放置物体并计算测试图与渲染图之间的差异,以确定哪个像素属于属于哪个物体。如果一个像素的深度差小于2厘米,则该像素被标记为物体的一部分。
1)利用物体的注意点从场景中分割物体:使用测试场景中的物体中心作为注意点。
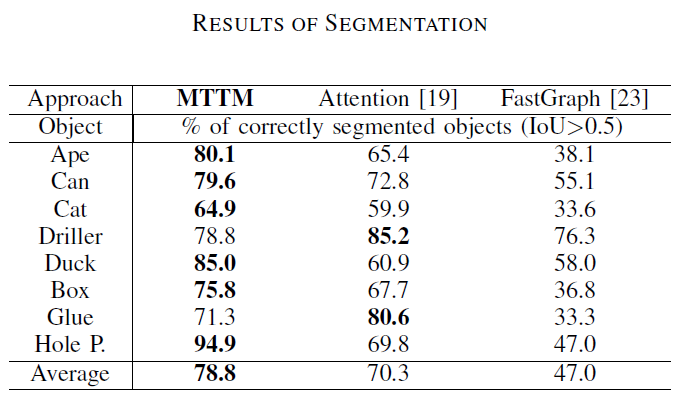
如上表所示,MTTM的分割结果优于其他使用RGB和深度值的方法,这说明MTTM利用近邻模板的特征来预测目标物体的分割mask,而不是利用物体的一般边界。
上图为同一图像中两个相似ROI的匹配结果,从不同类别中检索近邻模板,mask预测会发生显著变化。
假设目标物体在场景中是可见的,在后处理过程中,移除重叠小于30%的区域后,选择内点比较大的50个区域的最大值来计算最终得分S,得分最高的15个假设通过最多30次ICP迭代来细化,然后重新计算最终得分,来确定最佳预测。
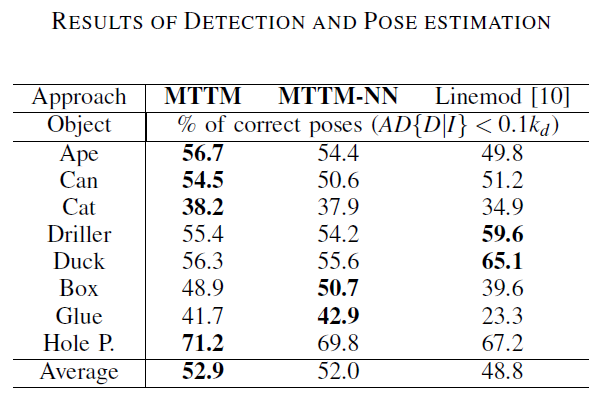
由于之前没有仅使用深度图像与模板进行匹配来检测物体和位姿估计,所以作者与基于模板的方法来进行比较。如下表所示,尽管baseline方法使用了颜色和深度信息,但MTTM在八个物体上六个性能更好。第二列为不进行位姿预测的结果,效果不如使用位姿预测的结果。
下图是使用linemod数据集中物体的真实模板得到的结果。
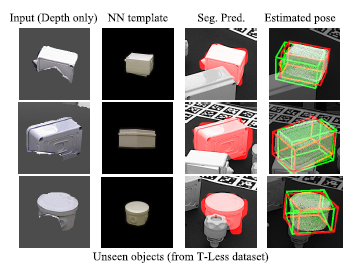
下图为使用T-less数据集得到的结果,数据库只是简单的替换为真实的图像,不需要进一步训练。绿色框为真实位姿,红色框为预测位姿。由于这些物体是训练集中没有的,所以在去除背景点之后检索性能变差。
[ICRA 2019]Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images
标签:下采样 卷积 sed 函数 很多 需要 创新 raw 图片
原文地址:https://www.cnblogs.com/lh641446825/p/11707552.html