标签:image 简化 就会 http 大量 没有 利用 base64 python实现
阅读课本第二三章,我了解了数字的分类和位置计数法,学会了如何在不同进制直接对数字进行转换和计算补码。知道了为什么计算机要采用二进制。了解了文本压缩的三种方法,颜色表示法和视频表示法。
问题一:我阅读了关于数据压缩技术的有关文字,没有明白既然有损压缩会丢失数据,为什么有时还会采用这种方法。
解决方案:我上网查了有关资料,知道了有损与无损的区别以及各自的优缺点。
有损压缩
有损压缩的特点是保持颜色的逐渐变化,删除图像中颜色的突然变化。生物学中的大量实验证明,人类大脑会利用与附近最接近的颜色来填补所丢失的颜色。例如,对于蓝色天空背景上的一朵白云,有损压缩的方法就是删除图像中景物边缘的某些颜色部分。当在·屏幕上看这幅图时,大脑会利用在景物上看到的颜色填补所丢失的颜色部分。利用有损压缩技术,某些数据被有意地删除了,而被取消的数据也不再恢复。
无可否认,利用有损压缩技术可以大大地压缩文件的数据,但是会影响图像质量。如果使用了有损压缩的图像仅在屏幕上显示,可能对图像质量影响不太大,至少对于人类眼睛的识别程度来说区别不大。可是,如果要把一幅经过有损压缩技术处理的图像用高分辨率打印机打印出来,那么图像质量就会有明显的受损痕迹。
无损压缩
无损压缩方法的优点是能够比较好地保存图像的质量,但是相对来说这种方法的压缩率比较低。但是,如果需要把图像用高分辨率的打印机打印出来,最好还是使用无损压缩几乎所有的图像文件都采用各自简化的格式名作为文件扩展名。从扩展名就可知道这幅图像是按什么格式存储的,应该用什么样的软件去读/写等等。
问题二:我阅读了有关计算补码的文字,但经过课上做题还是没有很明白。
解决方案:在博客园上找到了一篇文章,里面介绍的方法比较简单易懂。

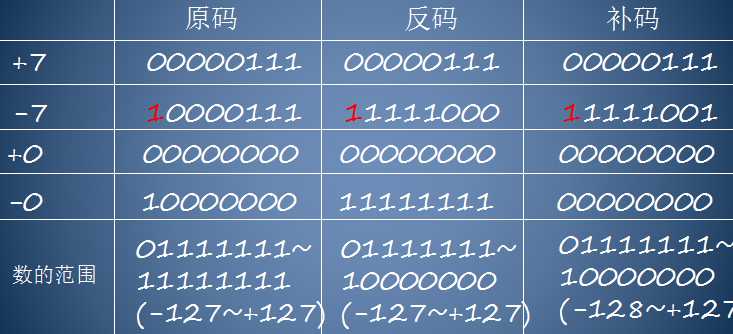
另外搜了关于补码的资料:
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理;同时,加法和减法也可以统一处理。此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
问题三:像更多地了解Unicode字符集
解决方案:查找了一些资料:
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),0 - 255被用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
如果要表示中文,显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
类似的,日文和韩文等其他语言也有这个问题。为了统一所有文字的编码,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode通常用两个字节表示一个字符,原有的英文编码从单字节变成双字节,只需要把高字节全部填为0就可以
随着进度向前进,我学到了更深奥也更有意思的知识。另外我也明白了学好英语的重要性。
阅读了自学是门手艺第五章,下载vsc并尝试写代码,但没能成功用python实现BASE64......我尽力了
2019-2020 191316《信息安全专业导论》第三周学习总结
标签:image 简化 就会 http 大量 没有 利用 base64 python实现
原文地址:https://www.cnblogs.com/ffffatal/p/11707437.html