标签:com 数组 显示 标签 dataframe scalar type 区别 you
一、区别
Numpy:是数值计算的扩展包,它能高效处理N维数组,复杂函数,线性代数.
Panadas:是做数据处理。市python的一个数据分析包(panel datas)
二、使用方式
导入pandas和numpy模块:
import pandas as pd
import numpy as np
三、pandas常用数据类型(Series,DataFrame)
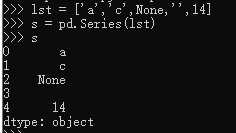
1.通过list创建Series,pandas会默认创建数字索引
list = [‘a‘,‘b‘,None,‘‘,1]
s = pd.Series(list)
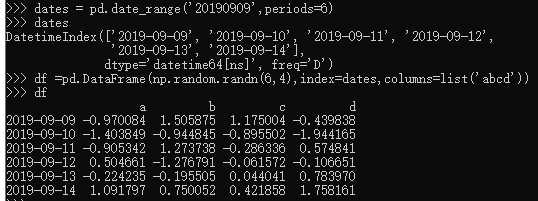
2.通过传递一个numpyarray,时间索引以及列标签来创建一个DataFrame:
3.通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:
通过字典创建dateframe时报错: If using all scalar(纯量,标量) values, you must pass an index,则需要为dataframe创建索引

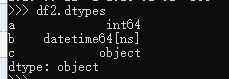
4、查看不同列的数据类型:
df.dtypes
二、查看数据
1. 查看frame中头部和尾部的行:
df.head(arg) //查看从头部开始的几行
df.tail(arg) //查看从尾部开始的几行
2.显示索引、列和底层的numpy数据:
显示索引:df.index
显示列:df.coulmns
显示dataframe中的数据:df.values
3、 describe()函数对于数据的快速统计汇总:
4、 对数据的转置:df.T
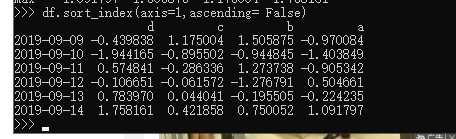
5、 按轴进行排序:
6、 按值进行排序
df.sort(columns=‘arg‘)
三、选择
1、 选择一个单独的列,这将会返回一个Series,等同于df.A:
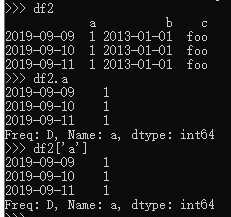
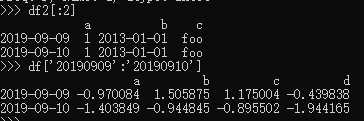
2、 通过[]进行选择,这将会对行进行切片:
标签:com 数组 显示 标签 dataframe scalar type 区别 you
原文地址:https://www.cnblogs.com/wangqingjiang/p/11712202.html