标签:ini obj nbsp 依赖 如何 eve ges drop 更新
Reference
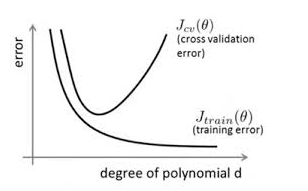
Overfitting definition


The reason of the overfiting
How to avoid the overfitting


正则化(regularization)
损失函数分为经验风险损失函数和结构风险损失函数,结构风险损失函数就是经验损失函数+表示模型复杂度的正则化,正则项通常选择L1或者L2正则化。结构风险损失函数能够有效地防止过拟合。
L1正则化是指权值向量中各个元素的绝对值之和,通常表示为,L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择,一定程度上,L1也可以反之过拟合 L2化是指权值向量中各个元素的平方和的平方,通常表示为,L2正则化可以防止模型过拟合 那L1和L2正则化是如何防止过拟合呢?首先我们先明白稀疏参数和更小参数的好处。
稀疏参数(L1):参数的稀疏,在一定程度实现了特征的选择。稀疏矩阵指有很多元素为0,少数参数为非零值。一般而言,只有少部分特征对模型有贡献,大部分特征对模型没有贡献或者贡献很小,稀疏参数的引入,使得一些特征对应的参数是0,所以就可以剔除可以将那些没有用的特征,从而实现特征选择。
更小参数(L2):越复杂的模型,越是尝试对所有样本进行拟合,那么就会造成在较小的区间中产生较大的波动,这个较大的波动反映出在这个区间内的导数就越大。只有越大的参数才可能产生较大的导数。试想一下,参数大的模型,数据只要偏移一点点,就会对结果造成很大的影响,但是如果参数比较小,数据的偏移对结果的影响力就不会有什么影响,那么模型也就能够适应不同的数据集,也就是泛化能力强,所以一定程度上避免过拟合。2.2 正则化(regularization)
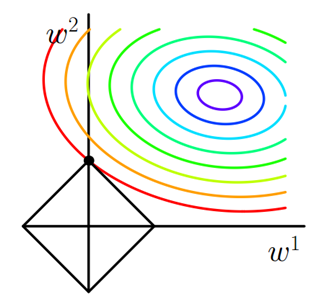
假设带有L1正则化的损失函数为:,当我们在后添加L1正则化项时,相当于对做了一个约束。此时我们的任务就变成在L1正则化约束下求出取最小值的解。考虑二维的情况,在有两个权值和的情况下,此时L1为,对于梯度下降方法,求解的过程用等值线表示,如下图所示。黑色方形是L1正则化的图形,五彩斑斓的等值线是的等值线。在图中,等值线与黑色方形首次相交的地方就是最优解。因为黑色方形棱角分明(二维情况下四个,多维情况下更多),与这些棱角接触的几率要远大于其他部位接触的概率,而在这些棱角上,会有很多权值为0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
L1正则化
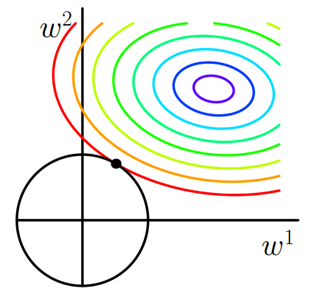
假设带有L2正则化的损失函数为:,类似地,可以得到下图在二维平面上的图形。因为二维L2正则化函数是个圆,与L1的方形相比,圆滑了好多,因此和L2相交于棱角的几率比较小,而是更多权值取值更小。
标签:ini obj nbsp 依赖 如何 eve ges drop 更新
原文地址:https://www.cnblogs.com/yousoluck/p/11719432.html