标签:oca cli 复杂 消费 降级 分布式 控制 节点 叠加
https://blog.csdn.net/qq_21125183/article/details/80708142
反压机制(BackPressure)被广泛应用到实时流处理系统中,流处理系统需要能优雅地处理反压(backpressure)问题。反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。许多日常问题都会导致反压,例如,垃圾回收停顿可能会导致流入的数据快速堆积,或者遇到大促或秒杀活动导致流量陡增。反压如果不能得到正确的处理,可能会导致资源耗尽甚至系统崩溃。反压机制就是指系统能够自己检测到被阻塞的Operator,然后系统自适应地降低源头或者上游的发送速率。目前主流的流处理系统 Apache Storm、JStorm、Spark Streaming、S4、Apache Flink、Twitter Heron都采用反压机制解决这个问题,不过他们的实现各自不同。
不同的组件可以不同的速度执行(并且每个组件中的处理速度随时间改变)。 例如,考虑一个工作流程,或由于数据倾斜或任务调度而导致数据被处理十分缓慢。 在这种情况下,如果上游阶段不减速,将导致缓冲区建立长队列,或导致系统丢弃元组。 如果元组在中途丢弃,那么效率可能会有损失,因为已经为这些元组产生的计算被浪费了。并且在一些流处理系统中比如Strom,会将这些丢失的元组重新发送,这样会导致数据的一致性问题,并且还会导致某些Operator状态叠加。进而整个程序输出结果不准确。第二由于系统接收数据的速率是随着时间改变的,短时负载高峰导致系统接收数据的速率远高于它处理数据的速率的情况,也会导致Tuple在中途丢失。所以实时流处理系统必须能够解决发送速率远大于系统能处理速率这个问题,大多数实时流处理系统采用反压(BackPressure)机制解决这个问题。下面我们就来介绍一下不同的实时流处理系统采用的反压机制:
对于开启了acker机制的storm程序,可以通过设置conf.setMaxSpoutPending参数来实现反压效果,如果下游组件(bolt)处理速度跟不上导致spout发送的tuple没有及时确认的数超过了参数设定的值,spout会停止发送数据,这种方式的缺点是很难调优conf.setMaxSpoutPending参数的设置以达到最好的反压效果,设小了会导致吞吐上不去,设大了会导致worker OOM;有震荡,数据流会处于一个颠簸状态,效果不如逐级反压;另外对于关闭acker机制的程序无效;
新的storm自动反压机制(Automatic Back Pressure)通过监控bolt中的接收队列的情况,当超过高水位值时专门的线程会将反压信息写到 Zookeeper ,Zookeeper上的watch会通知该拓扑的所有Worker都进入反压状态,最后Spout降低tuple发送的速度。
每个Executor都有一个接受队列和发送队列用来接收Tuple和发送Spout或者Bolt生成的Tuple元组。每个Worker进程都有一个单的的接收线程监听接收端口。它从每个网络上进来的消息发送到Executor的接收队列中。Executor接收队列存放Worker或者Worker内部其他Executor发过来的消息。Executor工作线程从接收队列中拿出数据,然后调用execute方法,发送Tuple到Executor的发送队列。Executor的发送线程从发送队列中获取消息,按照消息目的地址选择发送到Worker的传输队列中或者其他Executor的接收队列中。最后Worker的发送线程从传输队列中读取消息,然后将Tuple元组发送到网络中。
1. 当Worker进程中的Executor线程发现自己的接收队列满了时,也就是接收队列达到high watermark的阈值后,因此它会发送通知消息到背压线程。
2. 背压线程将当前worker进程的信息注册到Zookeeper的Znode节点中。具体路径就是 /Backpressure/topo1/wk1下
3. Zookeepre的Znode Watcher监视/Backpreesure/topo1下的节点目录变化情况,如果发现目录增加了znode节点说明或者其他变化。这就说明该Topo1需要反压控制,然后它会通知Topo1所有的Worker进入反压状态。
4.最终Spout降低tuple发送的速度。
Jstorm做了两级的反压,第一级和Jstorm类似,通过执行队列来监测,但是不会通过ZK来协调,而是通过Topology Master来协调。在队列中会标记high water mark和low water mark,当执行队列超过high water mark时,就认为bolt来不及处理,则向TM发一条控制消息,上游开始减慢发送速率,直到下游低于low water mark时解除反压。
此外,在Netty层也做了一级反压,由于每个Worker Task都有自己的发送和接收的缓冲区,可以对缓冲区设定限额、控制大小,如果spout数据量特别大,缓冲区填满会导致下游bolt的接收缓冲区填满,造成了反压。
限流机制:jstorm的限流机制, 当下游bolt发生阻塞时, 并且阻塞task的比例超过某个比例时(现在默认设置为0.1),触发反压
限流方式:计算阻塞Task的地方执行线程执行时间,Spout每发送一个tuple等待相应时间,然后讲这个时间发送给Spout, 于是, spout每发送一个tuple,就会等待这个执行时间。
Task阻塞判断方式:在jstorm 连续4次采样周期中采样,队列情况,当队列超过80%(可以设置)时,即可认为该task处在阻塞状态。
默认情况下,Spark Streaming通过Receiver以生产者生产数据的速率接收数据,计算过程中会出现batch processing time > batch interval的情况,其中batch processing time 为实际计算一个批次花费时间, batch interval为Streaming应用设置的批处理间隔。这意味着Spark Streaming的数据接收速率高于Spark从队列中移除数据的速率,也就是数据处理能力低,在设置间隔内不能完全处理当前接收速率接收的数据。如果这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题(如果设置StorageLevel包含disk, 则内存存放不下的数据会溢写至disk, 加大延迟)。Spark 1.5以前版本,用户如果要限制Receiver的数据接收速率,可以通过设置静态配制参数“spark.streaming.receiver.maxRate”的值来实现,此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。比如:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。为了更好的协调数据接收速率与资源处理能力,Spark Streaming 从v1.5开始引入反压机制(back-pressure),通过动态控制数据接收速率来适配集群数据处理能力。
Spark Streaming Backpressure: 根据JobScheduler反馈作业的执行信息来动态调整Receiver数据接收率。通过属性“spark.streaming.backpressure.enabled”来控制是否启用backpressure机制,默认值false,即不启用。
SparkStreaming 架构图如下所示:
SparkStreaming 反压过程执行如下图所示:
在原架构的基础上加上一个新的组件RateController,这个组件负责监听“OnBatchCompleted”事件,然后从中抽取processingDelay 及schedulingDelay信息. Estimator依据这些信息估算出最大处理速度(rate),最后由基于Receiver的Input Stream将rate通过ReceiverTracker与ReceiverSupervisorImpl转发给BlockGenerator(继承自RateLimiter).
当下游处理速度跟不上上游发送速度时,一旦StreamManager 发现一个或多个Heron Instance 速度变慢,立刻对本地spout进行降级,降低本地Spout发送速度, 停止从这些spout读取数据。并且受影响的StreamManager 会发送一个特殊的start backpressure message 给其他的StreamManager ,要求他们对spout进行本地降级。 当其他StreamManager 接收到这个特殊消息时,他们通过不读取当地Spout中的Tuple来进行降级。一旦出问题的Heron Instance 恢复速度后,本地的SM 会发送stop backpressure message 解除降级。
很多Socket Channel与应用程序级别的Buffer相关联,该缓冲区由high watermark 和low watermark组成。 当缓冲区大小达到high watermark时触发反压,并保持有效,直到缓冲区大小低于low watermark。 此设计的基本原理是防止拓扑在进入和退出背压缓解模式之间快速振荡。
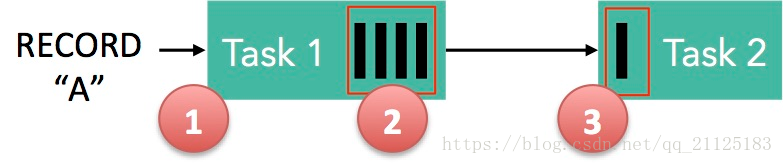
在 Flink 中,这些分布式阻塞队列就是这些逻辑流,而队列容量是通过缓冲池来(LocalBufferPool)实现的。每个被生产和被消费的流都会被分配一个缓冲池。缓冲池管理着一组缓冲(Buffer),缓冲在被消费后可以被回收循环利用。这很好理解:你从池子中拿走一个缓冲,填上数据,在数据消费完之后,又把缓冲还给池子,之后你可以再次使用它。
如下图所示展示了 Flink 在网络传输场景下的内存管理。网络上传输的数据会写到 Task 的 InputGate(IG) 中,经过 Task 的处理后,再由 Task 写到 ResultPartition(RS) 中。每个 Task 都包括了输入和输入,输入和输出的数据存在 Buffer 中(都是字节数据)。Buffer 是 MemorySegment 的包装类。
下面这张图简单展示了两个 Task 之间的数据传输以及 Flink 如何感知到反压的:
另外,官方博客中为了展示反压的效果,给出了一个简单的实验。下面这张图显示了:随着时间的改变,生产者(黄色线)和消费者(绿色线)每5秒的平均吞吐与最大吞吐(在单一JVM中每秒达到8百万条记录)的百分比。我们通过衡量task每5秒钟处理的记录数来衡量平均吞吐。该实验运行在单 JVM 中,不过使用了完整的 Flink 功能栈。
首先,我们运行生产task到它最大生产速度的60%(我们通过Thread.sleep()来模拟降速)。消费者以同样的速度处理数据。然后,我们将消费task的速度降至其最高速度的30%。你就会看到背压问题产生了,正如我们所见,生产者的速度也自然降至其最高速度的30%。接着,停止消费task的人为降速,之后生产者和消费者task都达到了其最大的吞吐。接下来,我们再次将消费者的速度降至30%,pipeline给出了立即响应:生产者的速度也被自动降至30%。最后,我们再次停止限速,两个task也再次恢复100%的速度。总而言之,我们可以看到:生产者和消费者在 pipeline 中的处理都在跟随彼此的吞吐而进行适当的调整,这就是我们希望看到的反压的效果。
在 Storm/JStorm 中,只要监控到队列满了,就可以记录下拓扑进入反压了。但是 Flink 的反压太过于天然了,导致我们无法简单地通过监控队列来监控反压状态。Flink 在这里使用了一个 trick 来实现对反压的监控。如果一个 Task 因为反压而降速了,那么它会卡在向 LocalBufferPool 申请内存块上。那么这时候,该 Task 的 stack trace 就会长下面这样:
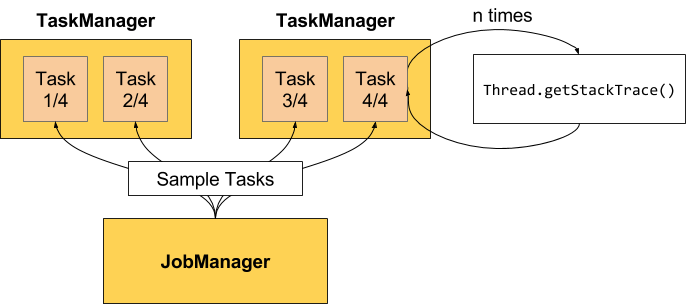
那么事情就简单了。通过不断地采样每个 task 的 stack trace 就可以实现反压监控。
Flink 的实现中,只有当 Web 页面切换到某个 Job 的 Backpressure 页面,才会对这个 Job 触发反压检测,因为反压检测还是挺昂贵的。JobManager 会通过 Akka 给每个 TaskManager 发送TriggerStackTraceSample消息。默认情况下,TaskManager 会触发100次 stack trace 采样,每次间隔 50ms(也就是说一次反压检测至少要等待5秒钟)。并将这 100 次采样的结果返回给 JobManager,由 JobManager 来计算反压比率(反压出现的次数/采样的次数),最终展现在 UI 上。UI 刷新的默认周期是一分钟,目的是不对 TaskManager 造成太大的负担。
Flink 不需要一种特殊的机制来处理反压,因为 Flink 中的数据传输相当于已经提供了应对反压的机制。因此,Flink 所能获得的最大吞吐量由其 pipeline 中最慢的组件决定。相对于 Storm/JStorm 的实现,Flink 的实现更为简洁优雅,源码中也看不见与反压相关的代码,无需 Zookeeper/TopologyMaster 的参与也降低了系统的负载,也利于对反压更迅速的响应。
[转帖]实时流处理系统反压机制(BackPressure)综述
标签:oca cli 复杂 消费 降级 分布式 控制 节点 叠加
原文地址:https://www.cnblogs.com/jinanxiaolaohu/p/11691789.html