标签:重复 文件中 导致 读取 磁盘 归并 字节数组 承担 shuff
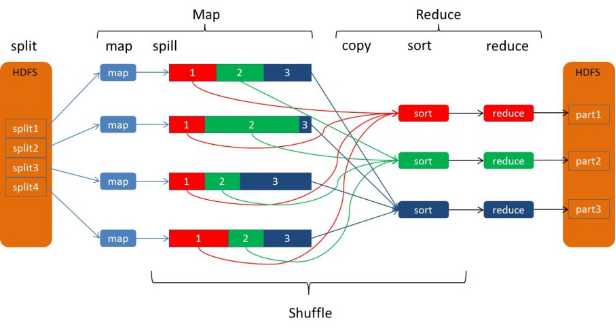
Spill过程包括输出、排序、溢写、合并等步骤,如图所示:
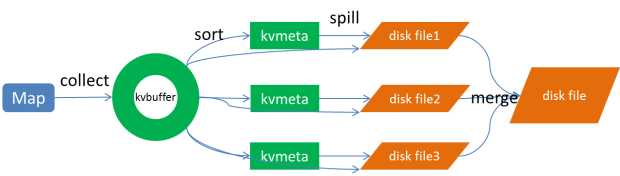
Collect
每个Map任务不断地以对的形式把数据输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
环形数据结构
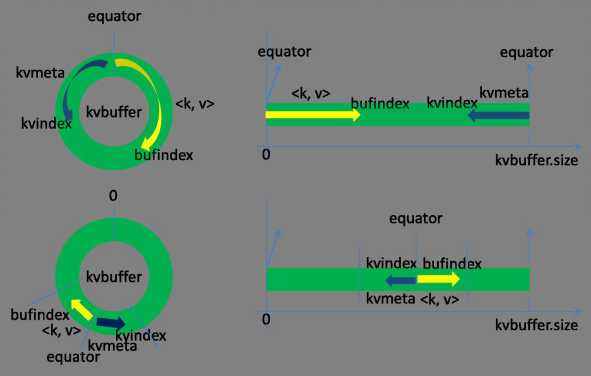
该环形数据结构是字节数组,叫Kvbuffer。Kvbuffer中不光放置了处理的数据还放置了一些索引数据,放置索引数据的区域叫Kvmeta。
数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点会在每次Spill只会进行一次更新。
初始的分界点是0,数据的存储方向和索引数据的存储方向是相反的,如图所示:
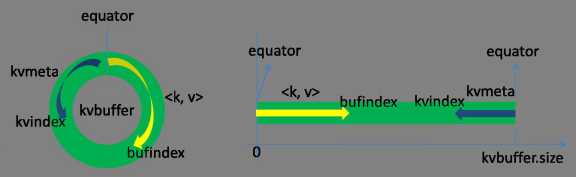
kvbuffer的存放指针bufindex是一直向上增长的。比如bufindex初始值为0,一个int型的key写完之后,bufindex增长为4,一个int型的value写完之后,bufindex增长为8。
索引是指在kvbuffer中的索引,是四个元组。包括:value的起始位置、key的起始位置、partition值、value的长度,一共占用四个int长度。
kvmeta的存放指针kvindex每次都会向下移动四个偏移量,然后再向上面四个偏移量的位置上填充四元组的数据。比如kvindex初始位置是-4,当第一个写完之后(kvindex+0)的位置存放value的起始位置、(kvindex+1)的位置存放key的起始位置、(kvindex+2)的位置存放partition的值、(kvindex+3)的位置存放value的长度,然后kvindex跳到-8位置,等第二个和索引写完之后,kvindex跳到-32的位置。
问题1: kvbuffer的空间如果用完了,怎么办?
把数据从内存写到磁盘上再接着往内存写数据,把kvbuffer中的数据写到磁盘上的过程叫spill,内存中的数据满了就会自动spill到具有更大空间的磁盘。
sort
先把kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是kvmeta中数据按照partition为单位聚集在一期,同一个partition内的按照key排序。
spill线程
spill线程为这次spill过程创建一个磁盘文件(从所有本地目录中轮询查找拥有足够大空间的目录,找到之后在该目录下创建一个类似“spillxx.out”的文件)。spill线程根据排过序的kvmeta逐个将partition的数据写入该文件,直到所有的partition都写完。一个partition在文件中对应的数据叫“段(segment)”。
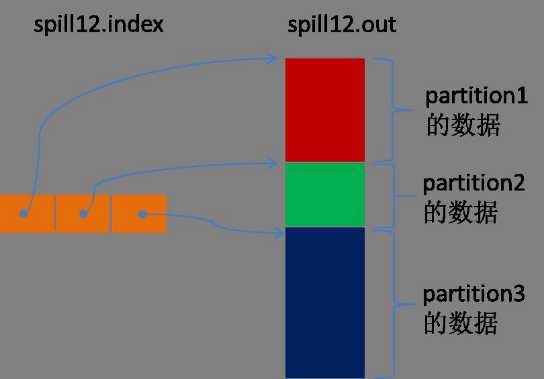
partition在文件中的索引信息是由一个三元组记录的,该三元组包括:起始位置、原始数据长度、压缩之后的数据长度,一个partition对应一个三元组。所有的索引信息是存放在内存中的,若果内存空间不足了就会把后续的索引信息写到磁盘中。
从所有的本地目录总轮询查找拥有足够大空间的目录,在该目录下创建一个类似“spillxx.out.index”的文件,文件中不光存储了索引数据还存储了crc32的校验数据(spillxx.out.index文件和spillxx.out文件不一定是在同一个目录下)。
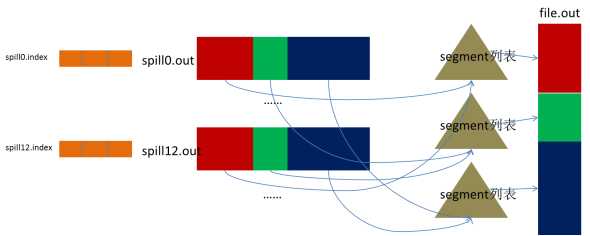
每一次spill过程会生成至少一个out文件,有时还会生成index文件,spill的次数也会在文件名中显现出来。索引文件和数据文件的对应关系如下图所示:
Map任务最终是要把数据写到磁盘上的,即使输出数据量很小,内存空间也充足。
Merge
Map任务如果输出数据很大,可能会进行好几次spill,out文件和index文件会产生很多且分布在不同的磁盘上,最后这些文件都需要合并该过程为Merge。
Merge过程是通过扫描本地目录得到spill文件和index文件的,然后把spill文件的路径存储在一个数组里,index文件的索引信息存储在一个列表里(spill过程中将这些信息从内存中写到文件里,是因为内存空间有限才做的操作,现在需要这些信息了又要从文件中将信息读取到内存。如果内存足够大,完全可以将信息放在内存中,merge时直接从内存中获取)。
Merge过程创建一个file.out的文件和一个叫file.out.index的文件用来存储最终的输出和索引。
Segment合并
一个partition可能对应着多个segment,需要将所有的segment进行合并,最终合并成为一个segment。
当一个partition对应很多个segment时,进行分批合并。先从segment列表中把第一批取出来,以key为关键字放置成最小堆,然后从最小堆中每次取出最小的输出到一个临时文件中,这样就把这一批segment合成一个临时的segment,再把它放回列表中(重复执行该操作直到剩下的segment是一批),最终输出到index文件中。
Map端的Shuffle过程到此结束。
Reduce任务拖取过来的Map数据中,小的数据可以放在内存中,较大的数据需要放到磁盘上。这样导致Reduce任务拖取过来的数据有的在内存中有的在磁盘上的文件中,最后会对这些数据进行一个全局的合并。
Merge Sort
Reduce端使用的Merge和Map端使用的Merge过程是一样的。Map的输出数据已经是有序的,Merge进行一次合并排序,即Reduce端的sort过程就是合并排序的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠的。
Reduce端的Shuffle过程到此结束
标签:重复 文件中 导致 读取 磁盘 归并 字节数组 承担 shuff
原文地址:https://www.cnblogs.com/yin1361866686/p/11732071.html