标签:form scala pack lock 构建 约束 case log list
启动集群后, Worker 节点会向 Master 节点汇报资源情况, Master掌握了集群资源状况。
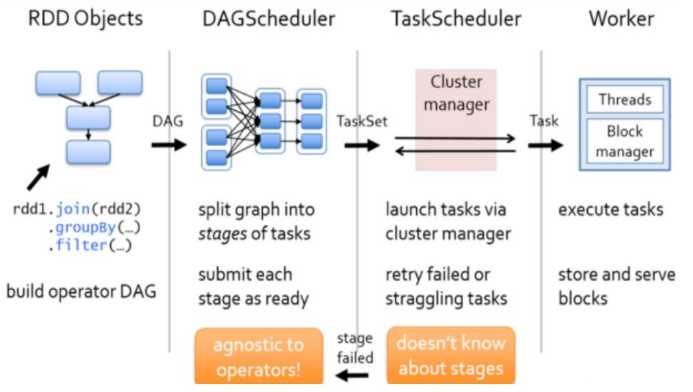
当 Spark 提交一个 Application 后, 根据 RDD 之间的依赖关系将 Application 形成一个 DAG 有向无环图。
任务提交后, Spark 会在任务端创建两个对象: DAGSchedular 和 TaskScheduler
DAGSchedular 是任务调度的高层调度器, 是一个对象
TaskScheduler 是任务调度的底层调度器
TaskSet 其实就是一个集合, 里面封装的就是一个个task任务, 也就是stage中的并行度 task 任务
package org.apache.spark.scheduler
import java.util.Properties
/**
* A set of tasks submitted together to the low-level TaskScheduler,
* usually representing missing partitions of a particular stage.
* 一同被提交到低等级的任务调度器的 一组任务集, 通常代表了一个特定的 stage(阶
* 段) 的 缺失的分区
*/
private[spark] class TaskSet(
// 任务数组
val tasks: Array[Task[_]],
// 阶段Id
val stageId: Int,
// 尝试的阶段Id(也就是下级Stage?)
val stageAttemptId: Int,
// 优先级
val priority: Int,
// 是个封装过的Hashtable
val properties: Properties) {
// 拼接 阶段Id 和 尝试的阶段Id
val id: String = stageId + "." + stageAttemptId
// 重写 toString
override def toString: String = "TaskSet " + id
}TaskScheduler 会遍历 TaskSet 集合, 拿到每个 task 后将 task发送到 Executor 中执行
其实就是发送到Executor中的线程池ThreadPool去执行
当 task 执行失败时, 则由TaskSchedular负责重试, 将 task重新发送给 Executor 去执行, 默认重试 3 次
//提交task,最后一行 backend.reviveOffers() 调用的是CoarseGrainedSchedulerBackend对象中的方法
override def submitTasks(taskSet: TaskSet) {
// 获取任务数组
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
// 加同步锁
this.synchronized {
// 创建任务集管理器 参数: 任务集, 最大容忍任务失败次数
val manager = createTaskSetManager(taskSet, maxTaskFailures)
// 阶段Id
val stage = taskSet.stageId
// taskSetsByStageIdAndAttempt 是一个 HashMap[Int, TaskSetManager]
/* getOrElseUpdate(key: A, op: => B): B=
* 如果 key 已经在这个 map 中, 就返回其对应的value
* 否则就根据已知的表达式 'op' 计算其对应的value 并将其存储到 map中, 并返回该 value
*/
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
// 将阶段任务集合设置为任务管理器
stageTaskSets(taskSet.stageAttemptId) = manager
// 获取冲突的任务集 如果 stageTaskSets 的任务集 不是传入的任务集 并且stageTaskSets的任务集不是僵尸进程 那么它就是冲突的任务集
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
// 如果有冲突的任务集
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
// 通过可调度的构造器创建一个任务集管理器
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
// 如故不是本地提交 或者 没有接收到任务
if (!isLocal && !hasReceivedTask) {
// 通过饥饿的计时器 来 根据 固定的比例进行调度
// scheduleAtFIxedRate 方法的三个参数: 时间任务, 延迟时间, 周期 如果延迟时间或周期值为父会抛出异常
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
// 如果没有发送任务
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
// 如果发送了任务, 就取消
this.cancel()
}
}
// 默认的饥饿超时临界值: 15s
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
// 调用 CoarseGrainedSchedulerBackend对象中的方法
backend.reviveOffers()
}如果重试 3 次 依然失败, 那么这个 task 所在的 stage 就失败了
如果 stage 失败了则由 DAGScheduler 来负责重试, 重新发送 TaskSet 到 TaskScheduler, Stage 默认重试 4 次。
如果重试 4 次 以后依然失败, 那么 该 job 就失败了。
一个 job 失败了, Application 就失败了。
TaskScheduler 不仅能重试失败的 task, 还会重试 straggling(直译是挣扎的, 这边可以意译为缓慢的) task(执行速度比其他task慢太多的task)
/**
* TaskScheduler 启动
*/
override def start() {
//StandaloneSchedulerBackend 启动
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
// 启动定期执行推测任务线程
speculationScheduler.scheduleWithFixedDelay(new Runnable {
override def run(): Unit = Utils.tryOrStopSparkContext(sc) {
// 检查所有活跃的jon中是否有可推测的任务
checkSpeculatableTasks()
}
}, SPECULATION_INTERVAL_MS, SPECULATION_INTERVAL_MS, TimeUnit.MILLISECONDS)
}
}// Check for speculatable tasks in all our active jobs.
// 检查是否有可推测的任务
def checkSpeculatableTasks() {
// 是否应该重新激活
var shouldRevive = false
// 加同步锁
synchronized {
// 检查是否有可推测的任务(传入执行推测所需的最小时间)
shouldRevive = rootPool.checkSpeculatableTasks(MIN_TIME_TO_SPECULATION)
}
// 如果需要重新激活
if (shouldRevive) {
// 就尝试运行推测任务
backend.reviveOffers()
}
}Spark 推测执行机制:
如果有运行缓慢的 task, 那么 TaskScheduler 会启动一个新的 task 来与该运行缓慢的 task 执行相同的处理逻辑。
两个 task 哪个先执行完, 就以哪个 task 的执行结果为准。
在 Spark 中推测执行默认是关闭的。
推测执行可以通过 spark.speculation 属性来配置
/**
* Return a speculative task for a given executor if any are available
* 如果有卡壳的进程,就向已知的executor进程返回一个推测任务
* The task should not have an attempt running on this host, in case
* the host is slow.
* 该任务不应有任何尝试任务在该主机上运行, 以防止该主机是有延迟的
* In addition, the task should meet the given locality constraint.
* 此外, 该任务需要满足已知的本地约束
*/
// Labeled as protected to allow tests to override providing speculative tasks if necessary
// 标注为 protected 以允许测试 来重写 提供的推测任务(如果需要的话)
protected def dequeueSpeculativeTask(execId: String, host: String, locality: TaskLocality.Value)
: Option[(Int, TaskLocality.Value)] =
{
// 从推测式执行任务列表中移除已经成功完成的task
speculatableTasks.retain(index => !successful(index)) // Remove finished tasks from set
// 1.判断 task 是否可以在该executor对应的Host上执行, 判断条件为:
// 2.没有taskAttempt在该Host上运行
// 3. 该 executor 没有在 task 的黑名单中(task 在该executor上失败过, 并且仍在‘黑暗’时间中)
def canRunOnHost(index: Int): Boolean = {
!hasAttemptOnHost(index, host) &&
!isTaskBlacklistedOnExecOrNode(index, execId, host)
}
// 判断推测执行任务集合是否为空
if (!speculatableTasks.isEmpty) {
// Check for process-local tasks;
// 检查 本地进程任务
// note that tasks can be process-local on multiple nodes when we replicate cached blocks, as in Spark Streaming
// 需要注意的是: 当我们备份缓存块时, 任务可以以本地进程 或者 多节点的形式运行 (就像spark流那样)
for (index <- speculatableTasks if canRunOnHost(index)) {
val prefs = tasks(index).preferredLocations
val executors = prefs.flatMap(_ match {
case e: ExecutorCacheTaskLocation => Some(e.executorId)
case _ => None
});
// 如果 executor 进程包含该任务Id
if (executors.contains(execId)) {
// 就不推测该任务
speculatableTasks -= index
// 返回某个本地进程
return Some((index, TaskLocality.PROCESS_LOCAL))
}
}
// Check for node-local tasks 检查本地节点的任务
if (TaskLocality.isAllowed(locality, TaskLocality.NODE_LOCAL)) {
for (index <- speculatableTasks if canRunOnHost(index)) {
val locations = tasks(index).preferredLocations.map(_.host)
if (locations.contains(host)) {
speculatableTasks -= index
return Some((index, TaskLocality.NODE_LOCAL))
}
}
}
// Check for no-preference tasks 检查非优先级的任务
if (TaskLocality.isAllowed(locality, TaskLocality.NO_PREF)) {
// 遍历 speculatableTasks, 如果有任务能够在主机上运行
for (index <- speculatableTasks if canRunOnHost(index)) {
// 获取该task的优先级位置
val locations = tasks(index).preferredLocations
if (locations.size == 0) {
speculatableTasks -= index
return Some((index, TaskLocality.PROCESS_LOCAL))
}
}
}
// Check for rack-local tasks 监察本地构建的任务
if (TaskLocality.isAllowed(locality, TaskLocality.RACK_LOCAL)) {
for (rack <- sched.getRackForHost(host)) {
for (index <- speculatableTasks if canRunOnHost(index)) {
val racks = tasks(index).preferredLocations.map(_.host).flatMap(sched.getRackForHost)
if (racks.contains(rack)) {
speculatableTasks -= index
return Some((index, TaskLocality.RACK_LOCAL))
}
}
}
}
// Check for non-local tasks 检查非本地性的任务
if (TaskLocality.isAllowed(locality, TaskLocality.ANY)) {
for (index <- speculatableTasks if canRunOnHost(index)) {
speculatableTasks -= index
return Some((index, TaskLocality.ANY))
}
}
}
None
}粗粒度资源申请 和 细粒度资源申请
粗粒度资源申请(Spark)
在 Application 执行之前, 将所有的资源申请完毕, 当资源申请成功后, 才会进行任务的调度, 当所有的 task 执行完成后才会释放这部分资源
优点
缺点
细粒度资源申请(MR)
Application 执行之前不需要先去申请资源, 而是直接执行, 让 job 中的每一个 task 在执行前自己去申请资源, task执行完成就释放资源。
优点
缺点
标签:form scala pack lock 构建 约束 case log list
原文地址:https://www.cnblogs.com/ronnieyuan/p/11734721.html