标签:管理 分布 mem drive lse 技术 持久化 shuf 数据量
Spark 内存管理
Spark 执行应用程序时, 会启动 Driver 和 Executor 两种 JVM 进程
静态内存管理分布图
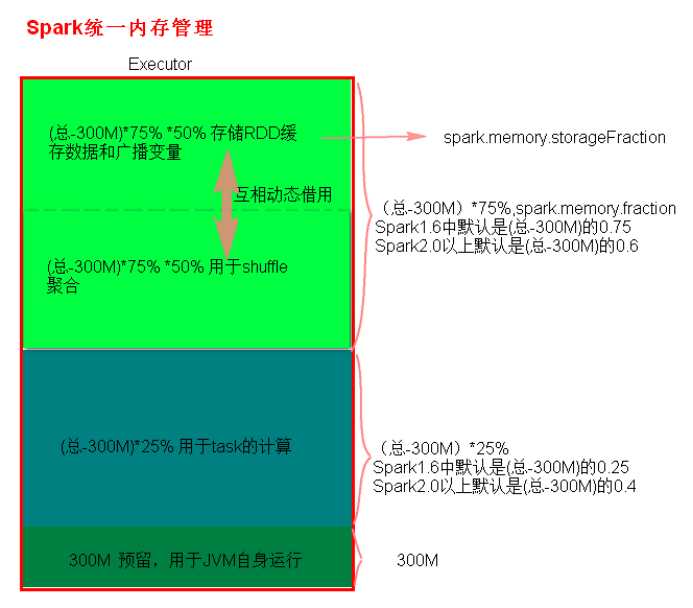
统一内存管理分布图
reduce 中 OOM(Out Of Memory) 如何处理?
原文地址:https://www.cnblogs.com/ronnieyuan/p/11742974.html