标签:models enc soft 无法 概念 而不是 tom 代码 some
2019年10月26日 星期六
将每个数据集看成是可计算的序列,每个序列包含一个模态的数据(以分层结构存储)
Step1 下载
Step2 对齐(下载的数据频率可能不一样)
sometimes the data needs to be aligned
Code 1>>>获取情感态度标签(label) cmumosi_highlevel.add_computational_sequences(mmdatasdk.cmu_mosi.labels,‘cmumosi/‘)
Code 2>>> 使everything对齐
cmumosi_highlevel.align(‘Opinion Segment Labels‘)
举例:
对于视频模态的数据v0,用v0[2]来表示视频的第三段
>>> from mmsdk import mmdatasdk
>>> cmumosi_highlevel=mmdatasdk.mmdataset(mmdatasdk.cmu_mosi.highlevel,‘cmumosi/‘)
>>> cmumosi_highlevel.align(‘glove_vectors‘,collapse_functions=[myavg])
>>> cmumosi_highlevel.add_computational_sequences(mmdatasdk.cmu_mosi.labels,‘cmumosi/‘)
>>> cmumosi_highlevel.align(‘Opinion Segment Labels‘)
From <https://github.com/A2Zadeh/CMU-MultimodalSDK>
Align function:对齐函数,接受两个值:时间和特征(也就是前边的两个矩阵)
cmumosi_highlevel.align(‘glove_vectors‘,collapse_functions=[myavg])可以接受多个函数作为参数,这时将各个函数分别执行并将结果拼接
使用glove

数据集结构(逻辑结构)
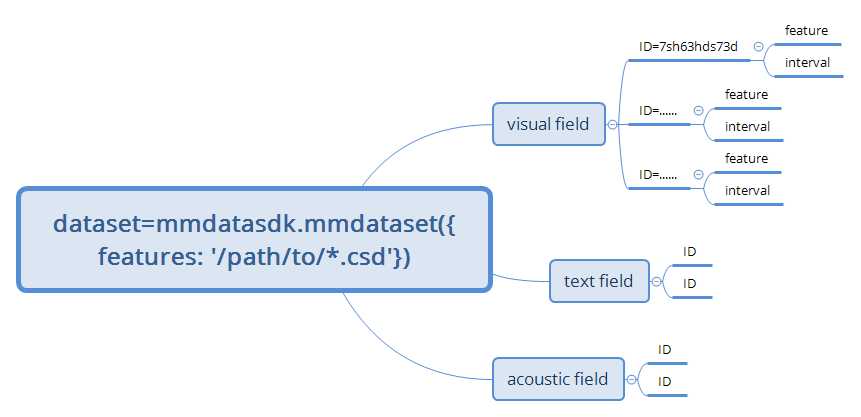
存储结构:
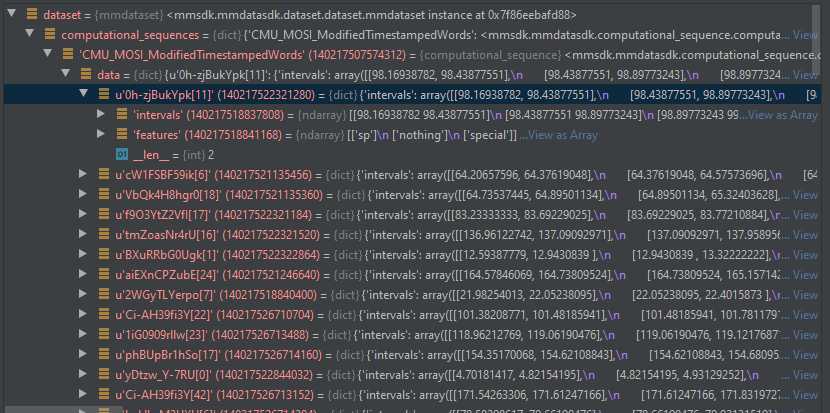
print(dataset[text_field][‘5W7Z1C_fDaE[9]‘][‘features‘])
输出
[[b‘its‘]
[b‘completely‘]
[b‘different‘]
[b‘from‘]
[b‘anything‘]
[b‘sp‘]
[b‘weve‘]
[b‘ever‘]
[b‘seen‘]
[b‘him‘]
[b‘do‘]
[b‘before‘]]
print(dataset[label_field][‘5W7Z1C_fDaE[10]‘][‘intervals‘])
输出
[[32.239227 34.50408 ]]
(时间戳的起止点)
Pivot modality:核心模态
不同模态数据的采样频率不一样,需要对齐到pivot modality上,通常情况下,对齐到words
对齐的办法:使用collapse函数
将不同模态数据按主要模态的时间轴进行分组,然后collapse函数将其进行池化
ATTN:本SDK将collapse函数应用到所有模态,但是Word模态无法求均值,因此需要一个try:except,捕获文本求均值产生的异常
dataset=md.mmdataset(recipe)
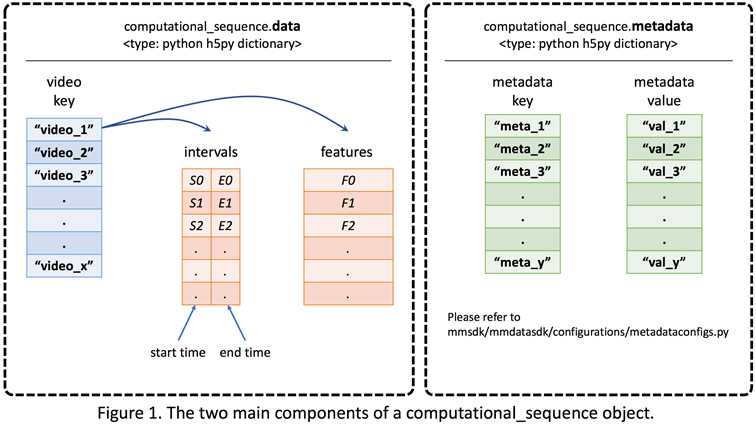
dataset变量结构如下:

其中,‘CMU_MOSI_ModifiedTimestampedWords‘ 模态的数据格式如下:

data里边存储了文本数据及其时间戳:
对于一个batch(也就是变量train、变量test)来说,5个维度的含义如下:
|
print(batch[0].shape) |
#wordvectors,paddedtomaxlen |
|
print(batch[1].shape) |
#visualfeatures |
|
print(batch[2].shape) |
#acousticfeatures |
|
print(batch[3]) |
#labels |
|
print(batch[4]) |
#lengths |
rain_loader = DataLoader(train, shuffle=False, batch_size=batch_sz, collate_fn=multi_collate)
在文件train.py中:
for batch in train_iter:
model.zero_grad()
t, v, a, y, l = batch
batch_size = t.size(0)
t,v,a,y,l=batch
# t,v,a,y,l中存储了一个batchsize中的所有数据
使用MOSI数据集,第一个batchsize之后,tval的维度如下:
t: [33, 56]
v: [33, 56, 47]
a: [33, 56, 74]
l: [56]
第二个batchsize之后,tval的维度如下:
t: [42, 56]
v: [42, 56, 47]
a: [42, 56, 74]
l: [56]
最后一个batchsize之后,上述变量的维度如下:
t: [59, 49]
v: [59, 49, 47]
a: [59, 49, 74]
l: [49]
debug模式下对上述y变量进行inspect,得到结果如下:

且有len(y) == 168
由于batchsize = 56
Dataloader的batchsize = batchsize * 3,因此len(y) == 168
划分batch之后,train_loader内保存了dataset的一部分,也按照上边的顺序保存
例如:
train_loader.dataset[0]的返回结果表示一整条多模态数据

train_loader.dataset[0]以及train_loader.dataset[1]等:
train_loader.dataset[0][0]中存储了三种模态的数据(文本声音图像)
train_loader.dataset[0][1]中存储了label(情感标签)
train_loader.dataset[0][2]中存储了视频对应的字符串(视频文件名)
ATTN:
train_loader.dataset[0][0]是一个list,list中有三个元素,是三个array,表示三种模态的数据
例如train_loader.dataset[67][2]返回:
Out[12]: u‘Oz06ZWiO20M[22]‘
train_loader.dataset[0][0][0]是wordvector(是一个array)
train_loader.dataset[0][0][1]是visual feature(是一个array)
train_loader.dataset[0][0][2]是acoustic feature(是一个array)
上述三个array构成了一个list
wordvector的维度比较低,通常少于10维
visual feature和acoustic feature在对齐之后含有多个array(本例中,每个音视频array有46维长度)
即:
train_loader.dataset[78][0][2]表示音频模态数据,但是这个数据包括14个特征向量(其他样本可能包含不同数值)
相当于以下14个tensor,每个tensor有46维:
train_loader.dataset[78][0][2][0]
... ...
train_loader.dataset[78][0][2][13]

总结:
MOSI数据集是语素级的,以数据集中编号为‘8qrpnFRGt2A‘的视频的第15小段为例,该段视频中人物说了14个字(word),因此对应的另外两种模态中,有14个array,验证方法是:

如图,train_loader.dataset[78][0][2].__len__()==14,因此说明语素级别上数据集是对齐的
在数据集中可以查找到对应的这句话
[[‘it‘]
[‘fell‘]
[‘like‘]
[‘i‘]
[‘was‘]
[‘watching‘]
[‘one‘]
[‘of‘]
[‘those‘]
[‘army‘]
[‘of‘]
[‘one‘]
[‘commercials‘]
[‘sometimes‘]]
对应的情感标签:

在trainloader的基础上,新建一个`train_iter` 变量如下
train_iter=tqdm_notebook(train_loader)
train_iter增加了sample的功能
事实上,train_iter就是train_loader的基础上增加了进度条功能
sample的方法使用的是pyTorch中的dataloader
_________________________
collate函数是pytorch中用Dataloader来处理数据集的概念,而不是多模态处理中的概念
collate取"拼接"之意
defmulti_collate(batch):
这个函数对一个batch的数据进行拼接
把batch[1]取出来作为label(就是y)
把batch[0][0]取出来作为文本模态(就是t)
batch[0][1]以及batch[0][2]取出来作为视觉和音频模态(就是v和a,多维tensor)
返回值是:
returnsentences,visual,acoustic,labels,lengths
————————————————————
数据集中共有1281条数据,即:
X_train_l.__len__()==1281
问题:最后整理出来的每个batch下的t,v,a,y,l进行拼接,得到1281条y和1281条l,但是v,a,t却只有1014条
debug模式下,发现在某一轮batch循环中,batchsize=56,有:
y.__len__() == l.__len__() == 56,
但是a,v,t的长度却是32
进一步分析a,v,t的维度,有:
In[14]: a.shape
Out[14]: torch.Size([48, 56, 74])
In[15]: v.shape
Out[15]: torch.Size([48, 56, 47])
因此,上边a,v,t的length和y,l的length不一样,其原因在于:代码中拼接a,v,t时选错了维度
解决方案:
需要将a,v,t的前两个维度互换位置,
t=list(np.array(t).transpose((1,0)))
第一步:torch.tensor转换成ndarray
第二步:ndarray前两维互换
第三步:转换成list
ATTN:
如果使用list(array1)的形式,则只将最外层转换成list,里边还是array
如果使用array1.tolist()方法,则整个array的每一层都变成了list
在第一个batch中,将t,v,a,y,l转换成ndarray之后的shape如下:
t的shape为(40,56)
v的shape为(40,56,47)
a的shape为(40,56,74)
y的shape为(56,1)
l的shape为(56,)
此时的ndarray的各个轴进行过变换
第二维(56)表示batchsize
第一维表示语素的个数(单词数)
第三维表示模态特征(应作为X_train的一行,进行拼接)
整理数据的代码:
forbatchintrain_iter:
#batch=list(batch)
#X_train_tmp=X_train_tmp+batch
t,v,a,y,l=batch
t=list(np.array(t).transpose((1,0)))
v=list(np.array(v).transpose((1,0,2)))
a=list(np.array(a).transpose((1,0,2)))
y=list(np.array(y))
l=list(np.array(l).reshape((-1,1)))
ifcnt==0:
X_train_t=t
X_train_v=v
X_train_a=a
Y_train=y
X_train_l=l
cnt+=1
else:
X_train_t+=t
X_train_v+=v
X_train_a+=a
Y_train+=y
X_train_l+=l
cnt+=1
上述代码之后:
X_train_a是一个list(len==1281),每个元素是一个array,每个array的shape是(40, 74):
X_train_a[0].shape
Out[3]: (40, 74)
其中,40是语素的个数,74是提取的特征数
CMU-Multimodal SDK Version 1.1 (mmsdk)使用总结
标签:models enc soft 无法 概念 而不是 tom 代码 some
原文地址:https://www.cnblogs.com/sddai/p/11743582.html