标签:des style blog http io color ar java for
Hadoop源码学习笔记(1)
——找到Main函数及读一读Configure类
前面在第一季中,我们简单地研究了下Hadoop是什么,怎么用。在这开源的大牛作品的诱惑下,接下来我们要研究一下它是如何实现的。
提前申明,本人是一直搞.net的,对java略为生疏,所以在学习该作品时,会时不时插入对java的学习,到时也会摆一些上来,包括一下设计模式之类的。欢迎高手指正。
整个学习过程,我们主要通过eclipse来学习,之前已经讲过如何在eclipse中搭建调试环境,这里就不多述了。
在之前源码初窥中,我们已经找到了主要几个的main函数入口。所以这里我们列一列计划:
我们会按这个顺序来研究,至于其他的像SecondeNameNode之类的,在最后再来研究。
同样,针对这些内容,我们还会分一下,第一步先来看DFS,第二步再来看MapReduce部份。
在研究DFS之前,我们看一下,这三者关系:

其中NameNode是客户端的主接口,也是唯一的对接点,同时主要负责文件名目录管理,以及数据DataNode的映射。
好了,要研究一块,我们先来把程序跑起来吧。
在eclipse中我们很方便地就能找到每个模块的对应的main函数,但还是有些不便,为了调试方便,我们再新建三个入口类:
自建入口类主要是为方便找到,然后这三个类中的代码分别为:
FsShellEnter.java
NamNodeEnter.java
DataNodeEnter.java
运行之:
启动命令行,运行:$ bin/hadoop namenode
然后在eclipse中,打开FsShellEnter.java,然后点击运行,可以看到:
反过来,在eclipse中,打开NamNodeEnter.java,点击运行,
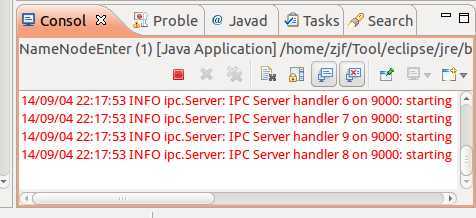
在控制台中,可以输入一堆的信息,说明正常了。
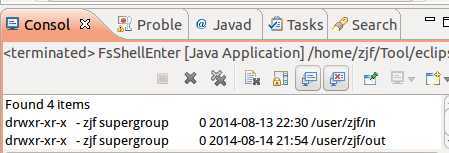
然后打开命令行,输入:$ bin/hadoop fs -ls,可以看到:

这样,说明正反运行都可以了。
当然这里我们没有涉及文件内容操作,所以没有DataNode也没问题,不过可以自行试一下。
打开这几个main函数,都可以看到上来都在初使化这个Configuration类。所以我们先来看一看这个类到底有点啥:
先看一下之前我们如何用这个类的:
从字面意思及这段函数,可以看出Configuration类用于读取配置文件的,且该程序就是读出配置文件中fs.default.name的值。
观察其构造函数:
发现其本没有做什么操作,主要设置了一个loadDefaults值为true。
然后再观察get函数:
Get函数先是调用了substituteVars函数,这个是正则表达式处理函数,对返回值进行去非法字符处理,然后getProps函数中,对hashtable类型的properties进行判断,如果为空则创建并进行初使化,否则直接返回。然后getProperty再根据其key值进行取值。
很明显,这里是采用了懒加载的方式,就是说并没有一开始加载配置文件中的数据,而是等要访问时,才进行加载。
进一步看如何初使化的,loadResources函数:
这里第5行可看到先加载了defaultResources中的资源,然后再加载hadoop-site.xml(第10行)。
defaultResources有哪些呢,一步步找,可以看到:
从这里看到,默认加载了core-default.xml和core-site.xml这两个文件。
到这里,我们可以再打开这3个XML来看看了:
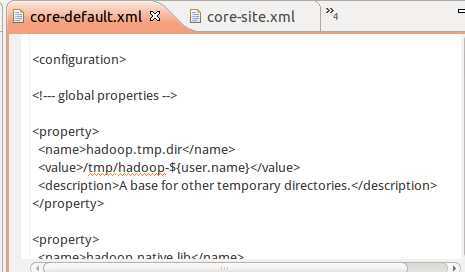
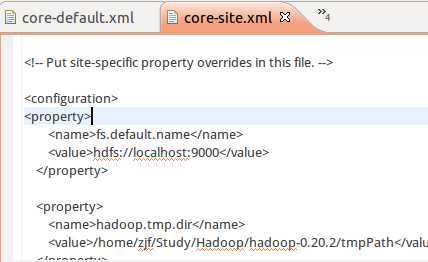
从这两个文件,我们可以看出,配置文件中存储就是用的key-value的健值对方式,然后加一个description对该配置项的描述。所以程序中读取也是传入key即可获取value。
同时,core-site.xml是我们自己配置文件,仔细看,可发现,在core-defalut.xml中也有一些相同的配置项。加载时先加载defalut再site,后者有相同key时覆盖前者。
所以换句话说,我们可以不配置hadoop.tmp.dir 则默认就在上面default中的/tmp….目录。
同时也可相到,hadoop的其他配置,就可以参考core-default.xml中的了。 可以直接改,也可以在core-site中再复制一份再改。
继续观察Configuration还有哪些方法:
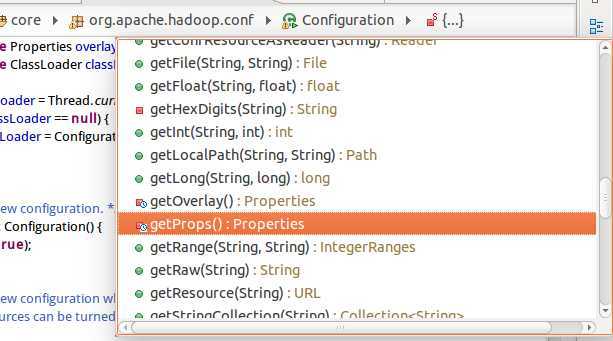
发现其中有很多个get函数,然后是返回各种不同类型的。这样就方便我们取值后直接处理了。
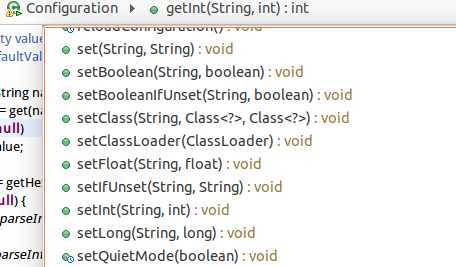
同时,可以看到还有一堆的set函数。这些set函数追进去看,是在修改hashtable的,并没有保存。所以说这些用途也是可见的,不用配置文件也可以让Configuration工作起来。
Hadoop源码学习笔记(1) ——第二季开始——找到Main函数及读一读Configure类
标签:des style blog http io color ar java for
原文地址:http://www.cnblogs.com/zjfstudio/p/4058250.html