标签:畅销书 网站 from row with 当当 测试 pass browser
selenium自动化测试工具可谓是爬虫的利器,基本动态加载的网页都能抓取,当然随着大型网站的更新,也出现针对selenium的反爬,有些网站可以识别你是否用的是selenium访问,然后对你加以限制.
当当网目前还没有对这方面加以限制,所以今天就用这个练习熟悉一下selenium操作,我们可以试一下爬取一下当当网top500的畅销书单的相关信息,页面如下:
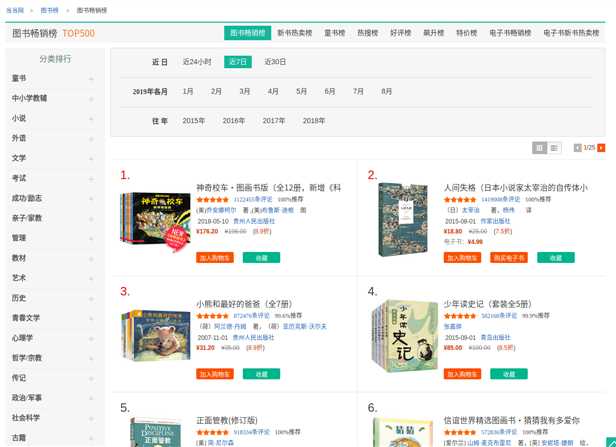
虽然这个页面不用登录就可以进来,但是我们可以随便试一下模拟登陆,直接在这个页面上面点击登录进入登录界面,然后会弹出一下窗口,
这是百分百会出现的,所以要先模拟点击把它点掉,然后才能传账号和密码进行登录
然后就是验证码的解决,说实话,现在当当这验证码基本很难实现用代码来破解,但是可以人工跳过,我在这里暂停了十秒,直接自己点击,然后等待程序运行,这样子就很容易就绕过了,反正只要过了验证这一关,下面的数据就不怕拿不到了.

贴下代码:
from selenium import webdriver
import time
from lxml import etree
import csv
browser = webdriver.Chrome()
browser.get("http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-recent7-0-0-1-1")
# browser.get_cookies()
time.sleep(1)
button_login1 = browser.find_element_by_xpath("//span[@id=‘nickname‘]/a[@class=‘login_link‘]")
button_login1.click()
close_button = browser.find_element_by_id("J_loginMaskClose")
close_button.click()
input_phone_number = browser.find_element_by_id("txtUsername")
input_phone_number.send_keys(‘自己账号‘)
time.sleep(0.2)
input_password = browser.find_element_by_id("txtPassword")
input_password.send_keys(‘自己密码‘)
time.sleep(10)
button_login2 = browser.find_element_by_id("submitLoginBtn")
button_login2.click()
# button_book = browser.find_element_by_name("nav1")
# button_book.click()
# button_list = browser.find_element_by_xpath("//div[@class=‘book_top ‘]/a[@class=‘more_top‘]")
# button_list.click()
for i in range(25):
time.sleep(5)
text = browser.page_source
# print(text)
html = etree.HTML(text)
book_name = html.xpath("//div[@class=‘name‘]/a/text()")
price = html.xpath("//span[@class=‘price_n‘]/text()")
original_price = html.xpath("//span[@class=‘price_r‘]/text()")
publisher = html.xpath("//div[@class=‘publisher_info‘][2]/a/text()")
# auther = html.xpath("//div[@class=‘publisher_info‘][1]/text()")
time1 = html.xpath("//div[@class=‘publisher_info‘][2]/span/text()")
result = zip(book_name, publisher, price, original_price, time1)
with open(‘book.csv‘, ‘a‘, newline=‘‘) as csvfile:
writer = csv.writer(csvfile, dialect=‘excel‘)
writer.writerows(result)
for i in result:
print(i)
next_button = browser.find_element_by_xpath(
"//div[@class=‘bang_list_box‘]/div[@class=‘paginating‘]/ul[@class=‘paging‘]/li[@class=‘next‘]/a")
next_button.click()
selenium自动化测试工具模拟登陆爬取当当网top500畅销书单
标签:畅销书 网站 from row with 当当 测试 pass browser
原文地址:https://www.cnblogs.com/lattesea/p/11746485.html