标签:wrap 链接 sha 受限玻尔兹曼机 oba 权重 col feed 神经元
解决分类问题
http://playground.tensorflow.org
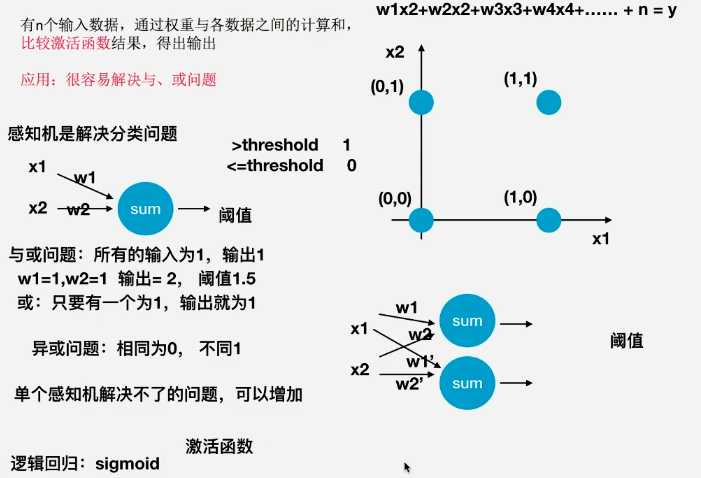
? 在机器学习领域和认知科学领域,人工神经网络(artificial neural network) 简称ann或类神经网络,一种放生物 神经网络的结构和功能的计算模型,用于对函数进行估计或近似.
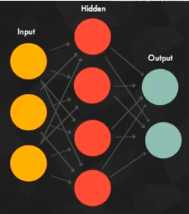
? 结构(Architecture):神经网络中的权重,神经元等等
? 激活函数(Activity Rule)
? 学习规则(Learning Rule)学习规则指定了网络中的权重如何随着时间的推移而调整(反向传播算法)
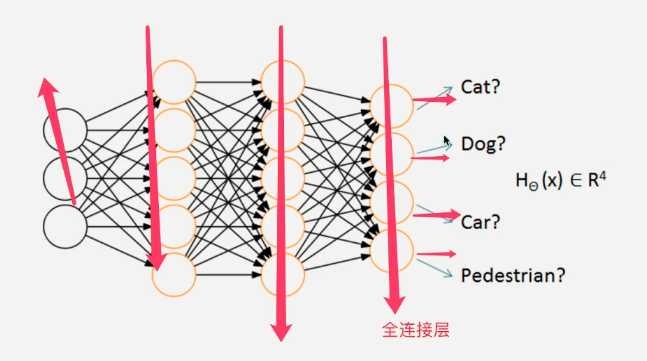
全连接层有多少个圆,最后就有多少输出
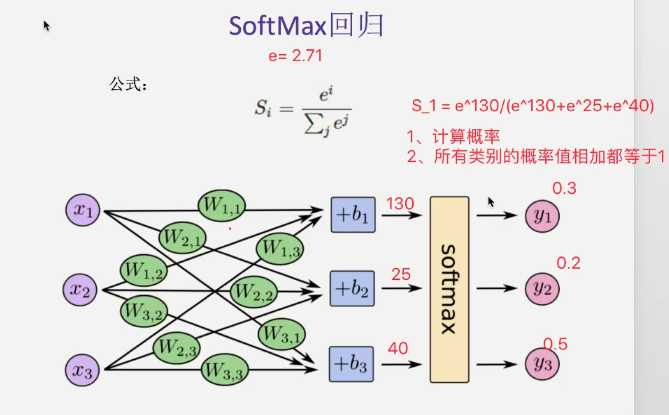
? softmax回归 (主要解决分类)
Si = e^i/(求和j^(e^j))
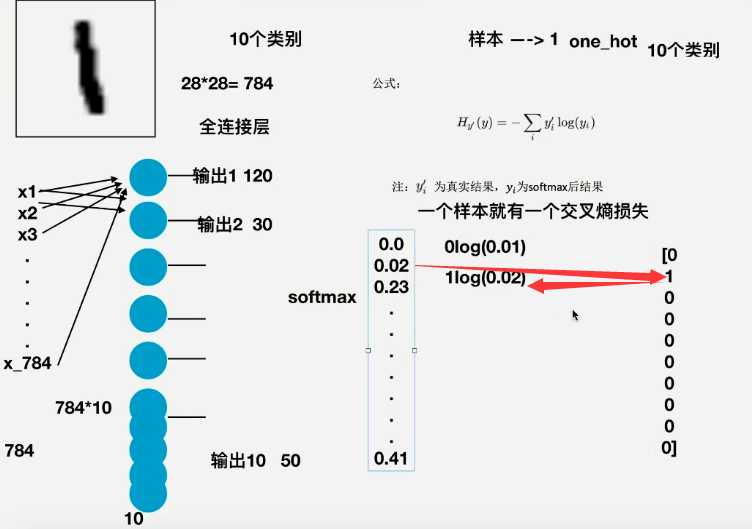

? 损失计算api
? 其他api介绍
tf.matmul(a,b,name=None)+bias 特征加权
? return:全连接结果,供交叉损失运算
不需要激活函数(因为是最后的输出)
tf.nn.softmax_corss_entropy_with_logits(labels=None,logits=None,name=None) 计算logits和labels之间的交叉损失熵
? labels:标签值(真实值)
? logits:样本值:样本加权之后的值
? return:返回损失函数列表
tf.reduce_mean(input_tensor)
tf.train.GradientDescentOptimizer(learning_rate) 梯度下降优化
? learning_rate:学习率
? minimize:最小优化损失
? return:梯度下降op
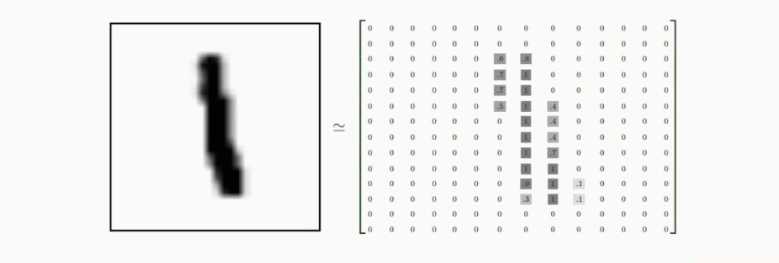
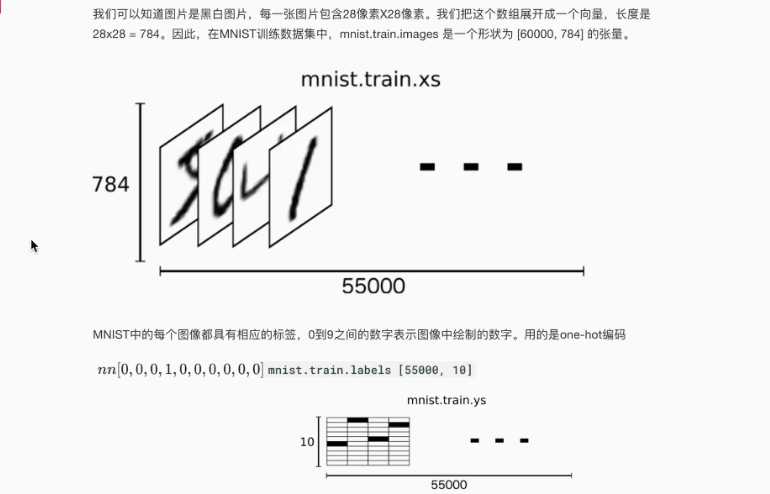
数据集 http://yann.lecun.com/exdb/mnist 55000训练集 10000测试集 每行包含两个部分,图片 标签
数据读取
from tensorflow.example.tutorials.minst import imput_data
mnist = input_data.read_data_sets(FLAGS.data_dir,one_hot=True) 使用API读取
准确率计算
equal_list = tf.equal(tf.argmax(y,1),tf.argmax(y_label,1)) 1表示按照列比较,返回一个None的 数值的列表,为1表示该样本预测正确,0错误
输入真实的结果(在本例中:每行是对应样本的一行ont_hot),和预测矩阵 每个样本的预测值
accuracy=tf.tf.reduce_mean(tf.cast(equal_list,tf.float32)) 准确率
简单实例深度神经网络
def simplePictureRecoginze():
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(r"I:\人工智能数据\mnist_65000_28_28_simple_number", one_hot=True)
# mnist.train.image 60000 行 784 列
# mnist.train.image[0]获取具体的一张图片
# mnist.train.labels 60000 行 10 列
# mnist.train.next_batch(50) 返回两个二维数组,50张图片,50张图片标签对应的ont_hot编码
import tensorflow as tf
FLAGS=tf.flags.FLAGS
tf.flags.DEFINE_integer("is_train",1,"指定程序是预测还是训练")
tf.flags._FlagValuesWrapper
# 1,建立数据占位符x[None,748] y_true=[None,10]
with tf.variable_scope("data"):
x = tf.placeholder(tf.float32, [None, 784])
y_true = tf.placeholder(tf.int32, [None, 10])
# 2,建立全连接层的神经网络 w[784,10] b[10]
with tf.variable_scope("fc_model"):
# 随机初始化权重和偏执
weight = tf.Variable(tf.random_normal([784, 10], mean=0.0, stddev=1.0), name="w")
bias = tf.Variable(tf.constant(0.0, shape=[10]))
# 预测None个样本的输出结果 [None,784]*[784,10]+[10] = [None,10]
y_predict = tf.matmul(x, weight) + bias
# 3,求出所有样本的损失,求平均值
with tf.variable_scope("soft_cross"):
# 求平均值交叉熵损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_true, logits=y_predict))
# 4,梯度下降求出损失
with tf.variable_scope("optimizer"):
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 5,计算准确率
with tf.variable_scope("acc"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
accuracy = tf.reduce_mean(tf.cast(equal_list, tf.float32))
# 收集变量
tf.summary.scalar("losses",loss)
tf.summary.scalar("acc",accuracy)
# 高纬度变量收集
tf.summary.histogram("weights",weight)
tf.summary.histogram("biases",bias)
# 定义一个初始化变量的op
init_op = tf.global_variables_initializer()
# 定义合并变量的op
merge = tf.summary.merge_all()
# 创建saver保存模型
save = tf.train.Saver()
# 开启会话训练
with tf.Session() as sess:
sess.run(init_op)
# 迭代步数取训练,更新参数预测
# 建立events文件,写入
events = r"./summary"
model = r"./Model/ckpt"
filewriter = tf.summary.FileWriter(events,graph=sess.graph)
if FLAGS.is_train == 1:
for i in range(2000):
# 取出特征值,目标值
mnist_x, mnist_y = mnist.train.next_batch(50)
feed_dict = {x: mnist_x, y_true: mnist_y}
# 运行训练
sess.run(train_op, feed_dict=feed_dict)
print("训练第%d的次,准确率为:%f"%(i,sess.run(accuracy,feed_dict=feed_dict)))
# 写入每部训练的值
summary = sess.run(merge,feed_dict=feed_dict)
filewriter.add_summary(summary,i)
# 保存模型
save.save(sess, model)
else:
# 加载模型
save.restore(sess,model)
# 如果是0,做出预测
for i in range(100):
# 每次测试一张图片
x_test,y_test = mnist.test.next_batch(1)
print("第%d张图片,手写数字目标是:%d,预测结果是:%d" % (i,
tf.argmax(y_test,1).eval(),
tf.argmax(sess.run(y_predict,feed_dict={x:x_test,y_true: y_test}),1).eval())
)
return None标签:wrap 链接 sha 受限玻尔兹曼机 oba 权重 col feed 神经元
原文地址:https://www.cnblogs.com/Dean0731/p/11747704.html