标签:link 观点 and png 一个 tap java tst apach
一:Spark的性能优化,主要手段包括:
1、使用高性能序列化类库
2、优化数据结构
3、对多次使用的RDD进行持久化 / Checkpoint
4、使用序列化的持久化级别
5、Java虚拟机垃圾回收调优
6、提高并行度
7、广播共享数据
8、数据本地化
9、reduceByKey和groupByKey的合理使用
10、Shuffle调优(核心中的核心,重中之重)
二:spark诊断内存消耗
java主要的内存消耗
1、每个Java对象,都有一个对象头,会占用16个字节,主要是包括了一些对象的元信息,比如指向它的类的指针。如果一个对象本身很小,比如就包括了一个int类型的field,那么它的对象头实际上比对象自己还要大。 2、Java的String对象,会比它内部的原始数据,要多出40个字节。因为它内部使用char数组来保存内部的字符序列的,并且还得保存诸如数组长度之类的信息。而且因为String使用的是UTF-16编码,所以每个字符会占用2个字节。比如,包含10个字符的String,会占用60个字节。 3、Java中的集合类型,比如HashMap和LinkedList,内部使用的是链表数据结构,所以对链表中的每一个数据,都使用了Entry对象来包装。Entry对象不光有对象头,还有指向下一个Entry的指针,通常占用8个字节。 4、元素类型为原始数据类型(比如int)的集合,内部通常会使用原始数据类型的包装类型,比如Integer,来存储元素。
怎么判断程序消耗的内存:
1、首先,自己设置RDD的并行度,有两种方式:要不然,在parallelize()、textFile()等方法中,传入第二个参数,设置RDD的task / partition的数量;要不然,用SparkConf.set()方法,设置一个参数,spark.default.parallelism,可以统一设置这个application所有RDD的partition数量。 2、其次,在程序中将RDD cache到内存中,调用RDD.cache()方法即可。 3、最后,观察Driver的log,你会发现类似于:“INFO BlockManagerMasterActor: Added rdd_0_1 in memory on mbk.local:50311 (size: 717.5 KB, free: 332.3 MB)”的日志信息。这就显示了每个partition占用了多少内存。 4、将这个内存信息乘以partition数量,即可得出RDD的内存占用量。
三:spark高性能序列化库
两种序列化机制
spark默认使用了第一种序列化机制: 1、Java序列化机制:默认情况下,Spark使用Java自身的ObjectInputStream和ObjectOutputStream机制进行对象的序列化。只要你的类实现了Serializable接口,那么都是可以序列化的。而且Java序列化机制是提供了自定义序列化支持的,只要你实现Externalizable接口即可实现自己的更高性能的序列化算法。Java序列化机制的速度比较慢,而且序列化后的数据占用的内存空间比较大。 2、Kryo序列化机制:Spark也支持使用Kryo类库来进行序列化。Kryo序列化机制比Java序列化机制更快,而且序列化后的数据占用的空间更小,通常比Java序列化的数据占用的空间要小10倍。Kryo序列化机制之所以不是默认序列化机制的原因是,有些类型虽然实现了Seriralizable接口,但是它也不一定能够进行序列化;此外,如果你要得到最佳的性能,Kryo还要求你在Spark应用程序中,对所有你需要序列化的类型都进行注册。
如何使用Kroyo序列
方式一:SparkConf().set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
方式二:如果要注册自定义的类型,那么就使用如下的代码,即可:
Scala版本:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.registerKryoClasses(Array(classOf[Counter] ))
val sc = new SparkContext(conf)
Java版本:
SparkConf conf = new SparkConf().setMaster(...).setAppName(...)
conf.registerKryoClasses(Counter.class)
JavaSparkContext sc = new JavaSparkContext(conf)
使用Kroyo序列的建议:
1、优化缓存大小 如果注册的要序列化的自定义的类型,本身特别大,比如包含了超过100个field。那么就会导致要序列化的对象过大。此时就需要对Kryo本身进行优化。因为Kryo内部的缓存可能不够存放那么大的class对象。此时就需要调用SparkConf.set()方法,设置spark.kryoserializer.buffer.mb参数的值,将其调大。 默认情况下它的值是2,就是说最大能缓存2M的对象,然后进行序列化。可以在必要时将其调大。比如设置为10。 2、预先注册自定义类型 虽然不注册自定义类型,Kryo类库也能正常工作,但是那样的话,对于它要序列化的每个对象,都会保存一份它的全限定类名。此时反而会耗费大量内存。因此通常都建议预先注册号要序列化的自定义的类。
使用场景:
首先,这里讨论的都是Spark的一些普通的场景,一些特殊的场景,比如RDD的持久化,在后面会讲解。这里先不说。
那么,这里针对的Kryo序列化类库的使用场景,就是算子函数使用到了外部的大数据的情况。比如说吧,我们在外部定义了一个封装了应用所有配置的对象,比如自定义了一个MyConfiguration对象,里面包含了100m的数据。然后,在算子函数里面,使用到了这个外部的大对象。
此时呢,如果默认情况下,让Spark用java序列化机制来序列化这种外部的大对象,那么就会导致,序列化速度缓慢,并且序列化以后的数据还是比较大,比较占用内存空间。
因此,在这种情况下,比较适合,切换到Kryo序列化类库,来对外部的大对象进行序列化操作。一是,序列化速度会变快;二是,会减少序列化后的数据占用的内存空间。
四:Spark优化数据结构
目的:使用数据结构是为了减少数据的占用量,从而减少内存的开销。
优化的对象:主要就是优化你的算子函数,内部使用到的局部数据,或者是算子函数外部的数据。都可以进行数据结构的优化。优化之后,都会减少其对内存的消耗和占用。
优化方式:
1、优先使用数组以及字符串,而不是集合类。也就是说,优先用array,而不是ArrayList、LinkedList、HashMap等集合。 比如,有个List<Integer> list = new ArrayList<Integer>(),将其替换为int[] arr = new int[]。这样的话,array既比List少了额外信息的存储开销,还能使用原始数据类型(int)来存储数据,比List中用Integer这种包装类型存储数据,要节省内存的多。 还比如,通常企业级应用中的做法是,对于HashMap、List这种数据,统一用String拼接成特殊格式的字符串,比如Map<Integer, Person> persons = new HashMap<Integer, Person>()。可以优化为,特殊的字符串格式:id:name,address|id:name,address...。 2、避免使用多层嵌套的对象结构。比如说,public class Teacher { private List<Student> students = new ArrayList<Student>() }。就是非常不好的例子。因为Teacher类的内部又嵌套了大量的小Student对象。 比如说,对于上述例子,也完全可以使用特殊的字符串来进行数据的存储。比如,用json字符串来存储数据,就是一个很好的选择。 {"teacherId": 1, "teacherName": "leo", students:[{"studentId": 1, "studentName": "tom"},{"studentId":2, "studentName":"marry"}]} 3、对于有些能够避免的场景,尽量使用int替代String。因为String虽然比ArrayList、HashMap等数据结构高效多了,占用内存量少多了,但是之前分析过,还是有额外信息的消耗。比如之前用String表示id,那么现在完全可以用数字类型的int,来进行替代。 这里提醒,在spark应用中,id就不要用常用的uuid了,因为无法转成int,就用自增的int类型的id即可。(sdfsdfdf-234242342-sdfsfsfdfd)
五:对多次使用的RDD进行持久化操作 或 CheckPoint
对多次运算的RDD进行持久化或放到内存,可以减少对重复计算的代价;
如果要保证在RDD的持久化数据可能丢失的情况下,还要保证高性能,那么可以对RDD进行Checkpoint操作。
对数据的持久化有多重级别:
除了对多次使用的RDD进行持久化操作之外,还可以进一步优化其性能。因为很有可能,RDD的数据是持久化到内存,或者磁盘中的。那么,此时,如果内存大小不是特别充足,完全可以使用序列化的持久化级别,比如MEMORY_ONLY_SER、MEMORY_AND_DISK_SER等。使用RDD.persist(StorageLevel.MEMORY_ONLY_SER)这样的语法即可。
这样的话,将数据序列化之后,再持久化,可以大大减小对内存的消耗。此外,数据量小了之后,如果要写入磁盘,那么磁盘io性能消耗也比较小。
对RDD持久化序列化后,RDD的每个partition的数据,都是序列化为一个巨大的字节数组。这样,对于内存的消耗就小的多了。但是唯一的缺点就是,获取RDD数据时,需要对其进行反序列化,会增大其性能开销。
因此,对于序列化的持久化级别,还可以进一步优化,也就是说,使用Kryo序列化类库,这样,可以获得更快的序列化速度,并且占用更小的内存空间。但是要记住,如果RDD的元素(RDD<T>的泛型类型),是自定义类型的话,在Kryo中提前注册自定义类型。
六:JVM虚拟机垃圾回收
主要是创建少量的对象,以及创建对象的大小。编程中避免大对象。
还有一些jvm的通用方法。都是通用的,可以参考一些通用方法。
七:提高并行度
实际上Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源。才能充分提高Spark应用程序的性能。
Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle的操作,就使用并行度最大的父RDD的并行度即可。
可以手动使用textFile()、parallelize()等方法的第二个参数来设置并行度;也可以使用spark.default.parallelism参数,来设置统一的并行度。
比如说,spark-submit设置了executor数量是10个,每个executor要求分配2个core,那么application总共会有20个core。此时可以设置new SparkConf().set("spark.default.parallelism", "60")来设置合理的并行度,从而充分利用资源。
官方建议设置的并行数量为2-3倍的cpu cores的数量,这样可以使一些计算能力较弱的cpu少计算一些数据。能力好的cpu计算多一些数据。
八:广播共享文件
如果你的算子函数中,使用到了特别大的数据,那么,这个时候,推荐将该数据进行广播。这样的话,就不至于将一个大数据拷贝到每一个task上去。而是给每个节点拷贝一份,然后节点上的task共享该数据。
这样的话,就可以减少大数据在节点上的内存消耗。并且可以减少数据到节点的网络传输消耗。
九:数据本地化
基于移动计算的成本要远远小于移动数据的原则。
数据本地化级别:
数据本地化,指的是,数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别: 1、PROCESS_LOCAL:数据和计算它的代码在同一个JVM进程中。 2、NODE_LOCAL:数据和计算它的代码在一个节点上,但是不在一个进程中,比如在不同的executor进程中,或者是数据在HDFS文件的block中。 3、NO_PREF:数据从哪里过来,性能都是一样的。 4、RACK_LOCAL:数据和计算它的代码在一个机架上。 5、ANY:数据可能在任意地方,比如其他网络环境内,或者其他机架上。
优化方案:
Spark倾向于使用最好的本地化级别来调度task,但是这是不可能的。如果没有任何未处理的数据在空闲的executor上,那么Spark就会放低本地化级别。这时有两个选择:第一,等待,直到executor上的cpu释放出来,那么就分配task过去;第二,立即在任意一个executor上启动一个task。
Spark默认会等待一会儿,来期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去。只要超过了时间,那么Spark就会将task分配到其他任意一个空闲的executor上。
可以设置参数,spark.locality系列参数,来调节Spark等待task可以进行数据本地化的时间。spark.locality.wait(3000毫秒)、spark.locality.wait.node、spark.locality.wait.process、spark.locality.wait.rack。
十: groupByKey 和 ReduceByKey
如果能用reduceByKey,那就用reduceByKey,因为它会在map端,先进行本地combine,可以大大减少要传输到reduce端的数据量,减小网络传输的开销。
只有在reduceByKey处理不了时,才用groupByKey().map()来替代。
十一: shuffle优化
了解下shuffle的过程:
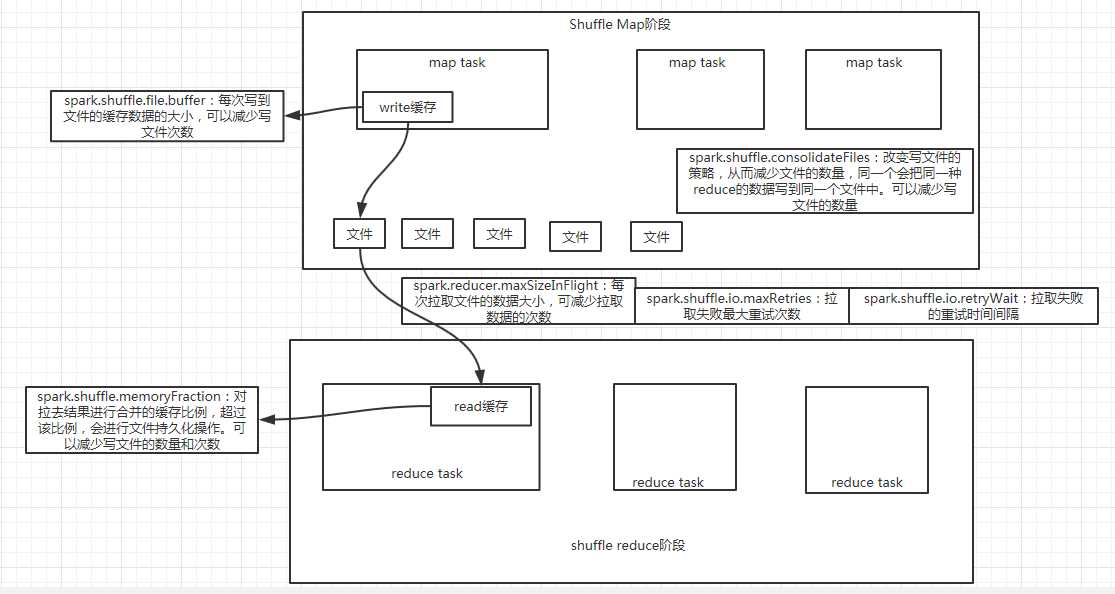
优化参数:
new SparkConf().set("spark.shuffle.consolidateFiles", "true") spark.shuffle.consolidateFiles:是否开启shuffle block file的合并,默认为false spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次 spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s spark.shuffle.memoryFraction:用于reduce端聚合的内存比例,默认0.2,超过比例就会溢出到磁盘上
1- spark.shuffle.consolidateFiles参数优化
没有开启consolidation机制的时候,shuffle write的性能是比较低下的,而且会影响到shuffle read的性能,也会比较低下。
因为在shuffle map端创建的磁盘文件太多了,导致shuffle write要耗费大量的性能到磁盘文件的创建,以及磁盘的io上。对于shuffle read,也是一样的,每个result task可能都需要通过磁盘io读取多个文件的数据,都只shuffle read,性能可能也会受到影响。做主要的还是shuffle write,因为要写的磁盘文件太多。
比如每个节点有100个shuffle map task,10个CPU core是,总共有1000个result task。所以,每个节点上的磁盘文件为100*1000个。
设置为true时,每个cpu为每个result task写一个文件(文件内容是之前的数据进行合并的结果),每个节点上的磁盘文件为10*1000个。
2- spark.reducer.maxSizeInFlight
如果内存足够的话,这个量应该增大,这样,result task拉取的次数会减少(每次拉取数据量增加)。
3- spark.shuffle.file.buffer
可以适量增大,这样每次写入到文件的数据量减少,从而减少写文件的次数。
4- spark.shuffle.io.maxRetries
拉取数据的时候,可能jvm在full GC。
5- spark.shuffle.io.retryWait
可以适当增加时间。为了应对jvm 的full GC。
6- spark.shuffle.memoryFraction
可以适当的调大。
执行reduce task的Excetor中,有一部分内存是用来汇聚各个reduce task拉取的数据,放到map集合中,进行聚合。
当该数据超过总缓存*比例时,会把该内存的数据写入到磁盘上。
7- 如果jvm GC没有调优好,会导致每次gc都需要1min。那么拉取的最大默认时间为3*5s=15s。就会导致频繁的很多文件拉取失败。会报shuffle output file lost。然后DAGScheduler会重试task和stage。最后甚至导致application挂掉。
以上观点基本都借鉴自:中华石杉--spark从入门到精通的观点。
标签:link 观点 and png 一个 tap java tst apach
原文地址:https://www.cnblogs.com/parent-absent-son/p/11749131.html