标签:res 例子 查找 之间 情况 HERE log src 拷贝
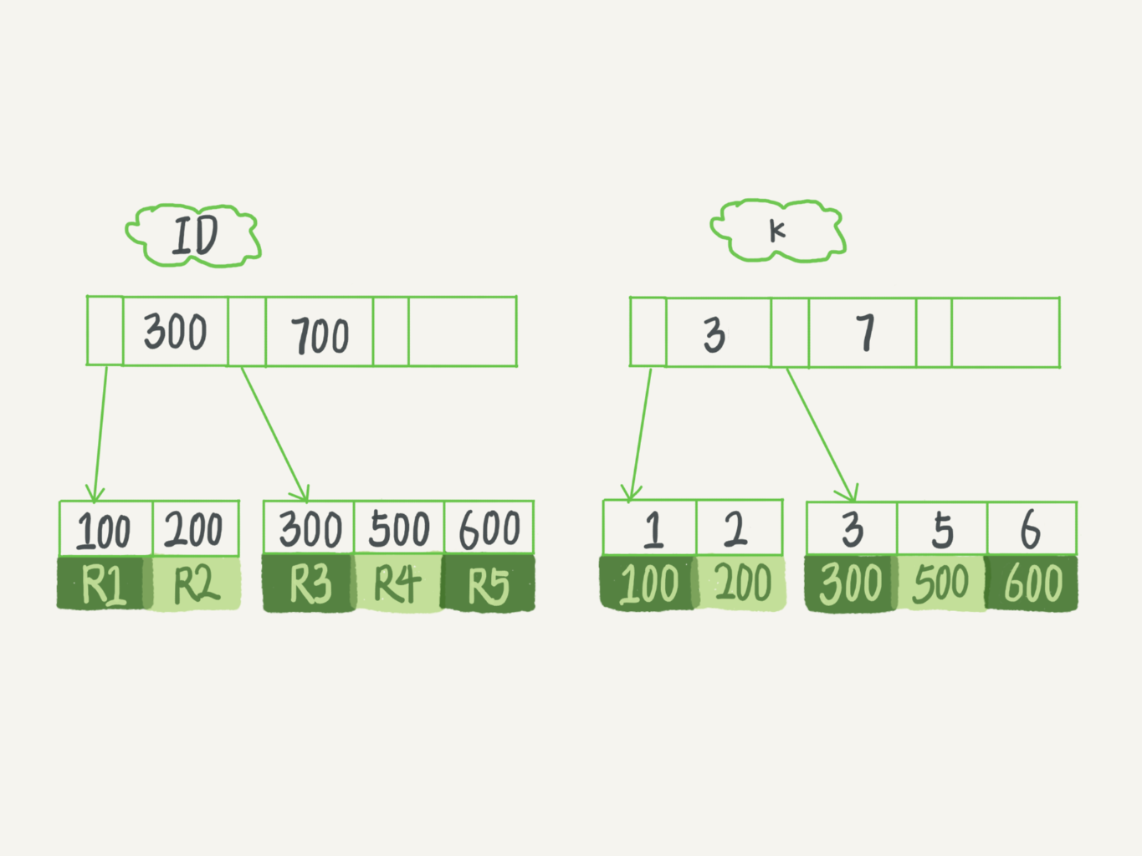
SQL
select id from zx where k=3普通索引
查询k索引树这个数据,当查到(3,300)的时候,还会继续查找下一个记录,如果下一个记录k不是3了就结束了
唯一索引
区别就在于查到(3,300)就直接结束,因为是唯一索引,它知道肯定是唯一的
结论
如果记录是唯一的,那么普通索引和唯一索引的区别很小,普通索引就多了一次查询下一个记录
InnoDB的数据是按数据页为单位来读写的,就是说,读取一条数据的时候,不是只读取一条记录到内存,而是以页为单位读取到内存中,在InnoDB中,数据页的大小是默认16KB。
假如要查询k=5的记录,会把k=5部分的数据页读到内存,读下一个数据的时候就会在数据页取了,这样的话性能就会高很多,要是下一个数据不在数据页中了,那么就再去硬盘中读取数据页,但是这种情况是很少的。
当要更新一个记录的时候,如果数据所在的数据页在内存中,那么就直接在数据页上面更新,如果数据页不在内存,那么InooDB就会将这些更新缓存在change buffer中,这样就不需要从内存中读取数据页了。在下次查询的时候,将数据页读入到内存的时候,然后执行change buffer里面的更新操作,这个过程叫做merge。
注意
其实change buffer是持久化数据,也就是说它可以存在硬盘上,在内存上也有拷贝。
当数据在数据页
插入一条新记录(4,100)
唯一索引:会确认数据页中有3,5之间没有4,没有就插入
普通索引:找到3和5之间的位置直接插入
这个的区别也不大
当数据页不在内存中
唯一索引:需要将数据页读到内存中,然后判断,数据页中有3,5之间没有4,没有就插入
普通索引:直接把更新记录写到change buffer里面
这个区别会大一点,因为涉及到了磁盘的读取了
经过上面你就会发现,这两个玩意儿好像啊,有点区分不开的感觉,其实它们是两个东西,直接举个例子
例子
insert into t(id,k) values(id1,k1),(id2,k2);加入要插入两条数据
1.数据一的数据页在内存中,直接更新到内存
2.数据二的数据页没有,那么就存在change buffer中
3.将上面两个记录记在了redo log中
redo log可以理解成,记录上面的操作是否操作完成,因为只有当数据真正更新到硬盘上,才算更新完毕。
https://time.geekbang.org/column/article/70848
标签:res 例子 查找 之间 情况 HERE log src 拷贝
原文地址:https://www.cnblogs.com/zx125/p/11749304.html