标签:抓取 info 资源下载 request png start 取出 lines ESS
一、架构图
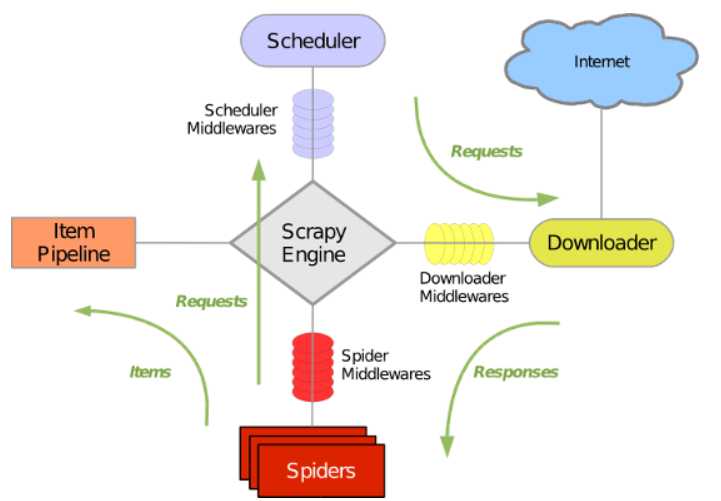
二、流程
1、引擎从调度器中取出一个URL,用于抓取
2、引擎把URL封装成一个请求(start_requests) 传递给下载器
3、下载器把资源下载下来,并封装成Response
4、爬虫解析(parse) Response
5、解析出实体(yield Item),交给pipelines中的process_item方法
6、解析出URL(yield Response),则把URL交给调度器等待抓取
标签:抓取 info 资源下载 request png start 取出 lines ESS
原文地址:https://www.cnblogs.com/wt7018/p/11749856.html