标签:而且 tran -- word sid ocs pac border 元数据
HDFS是英文Hadoop Distributed File System的缩写,中文翻译为Hadoop分布式文件系统,它是实现分布式存储的一个系统,所以分布式存储有的特点,HDFS都会有,HDFS的架构图:
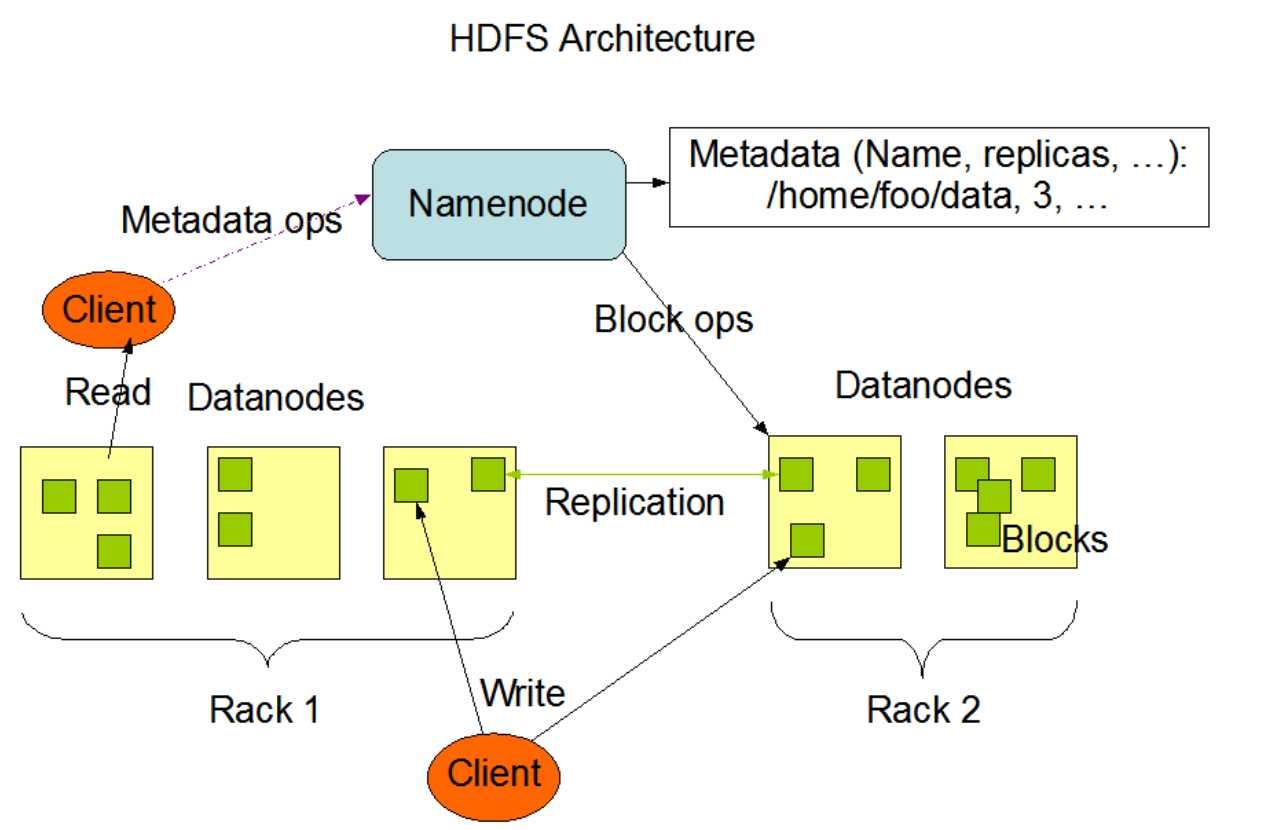
上图中HDFS的NameNode其实就是对应着分布式存储的Storage master,主要是用来存储元数据的,根据这些元数据就可以管理所有的机器节点和数据块
上图的Rack是机架的意思,也就是说机器可以放在不同的机架上
在安装HDFS的时候,除了NameNode和DataNode两个角色外,我们还发现有一个SecondaryNameNode,这个角色主要是为了提高NameNode的性能而存在的,我们后面会详细讲解
HDFS WEB UI

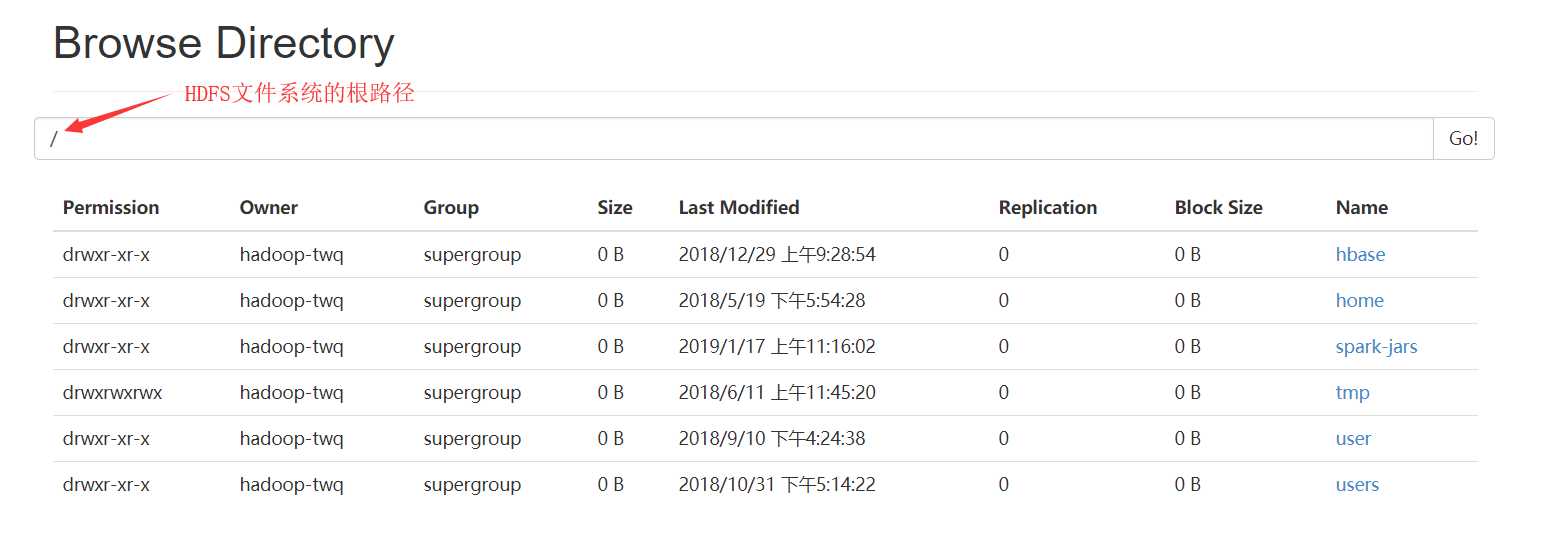
然后就会出现HDFS中的根目录下所有的文件:
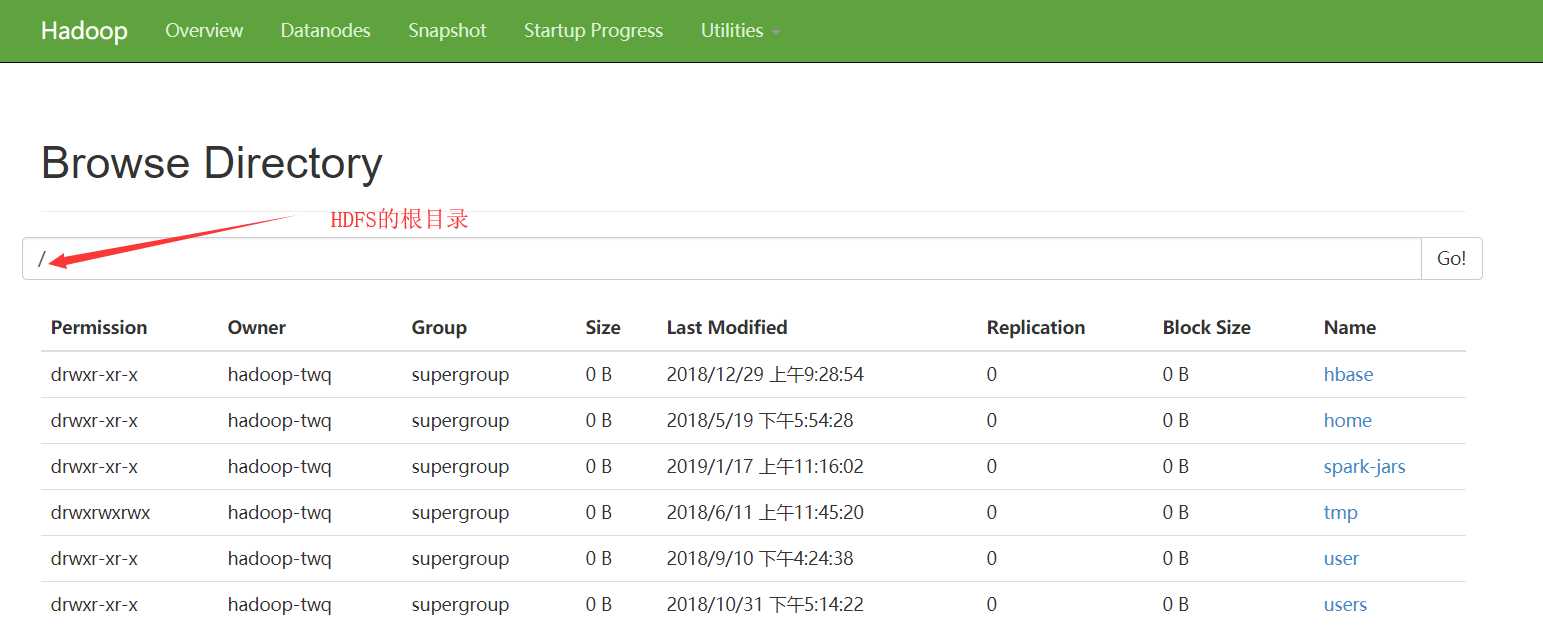
上面的方式是我们常见的访问HDFS文件的方式之一,这种使用的方式也是很方便的。

这篇文章,我们重点分别来详细看一下Overview、Datanodes以及Utilities三个模块
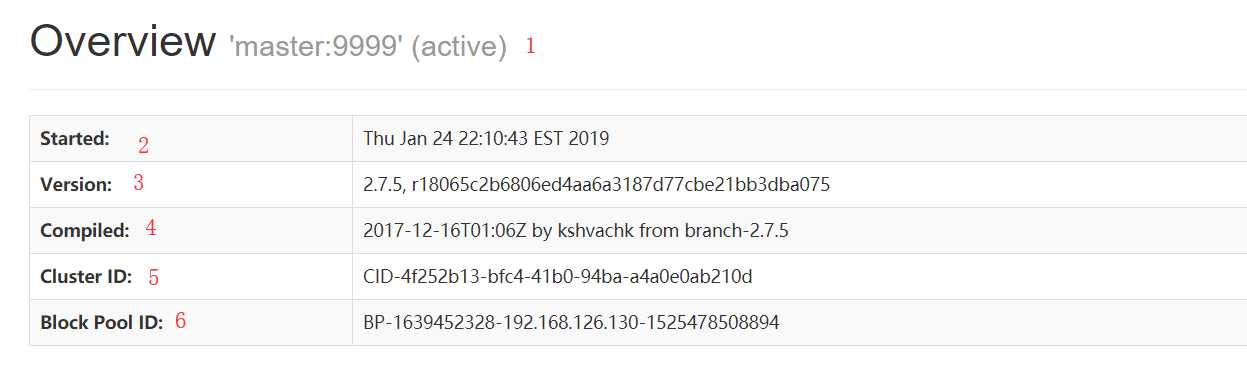
Overview
Summary
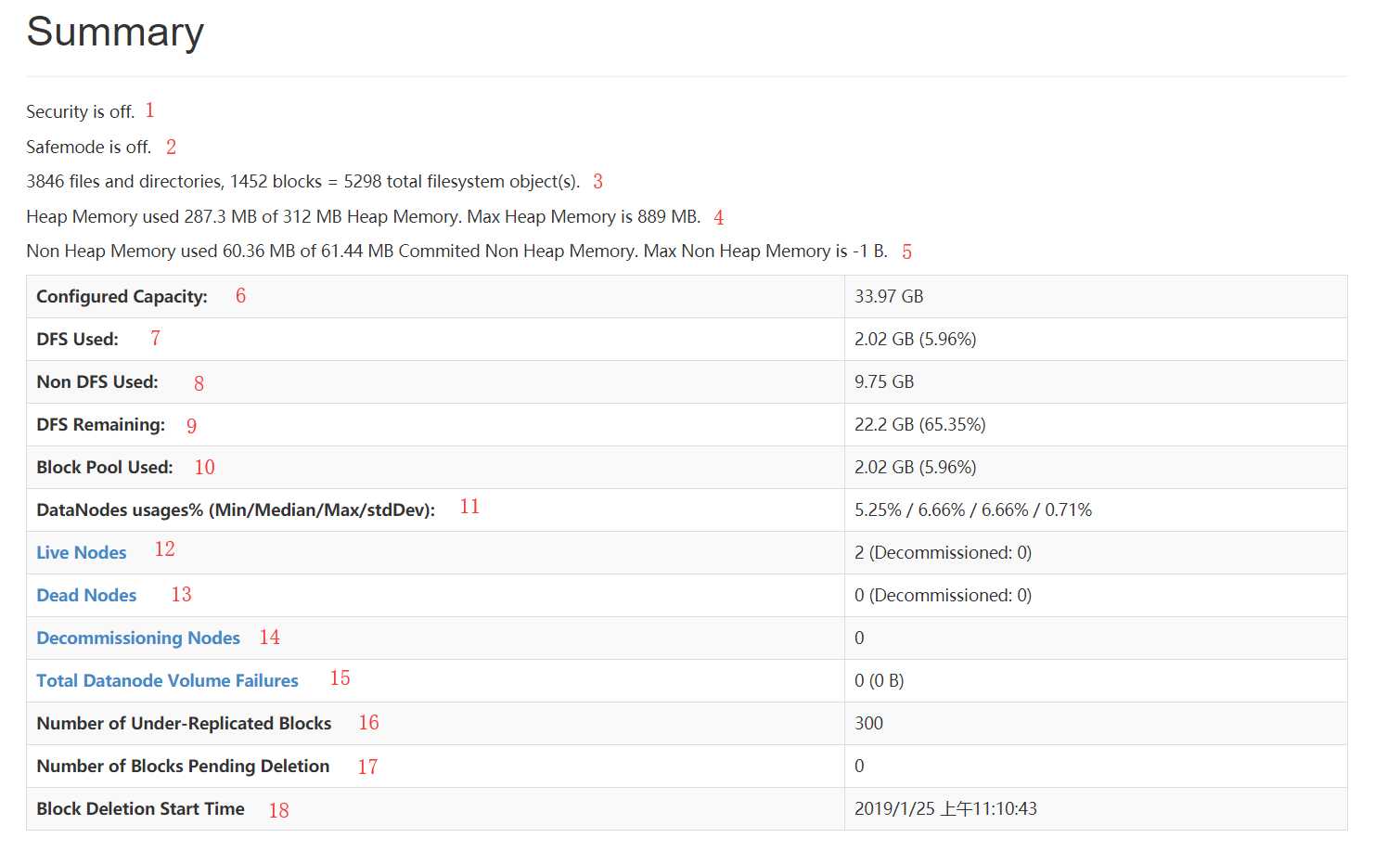
配置dfs.datanode.data.dir就是DataNode数据存储的文件目录
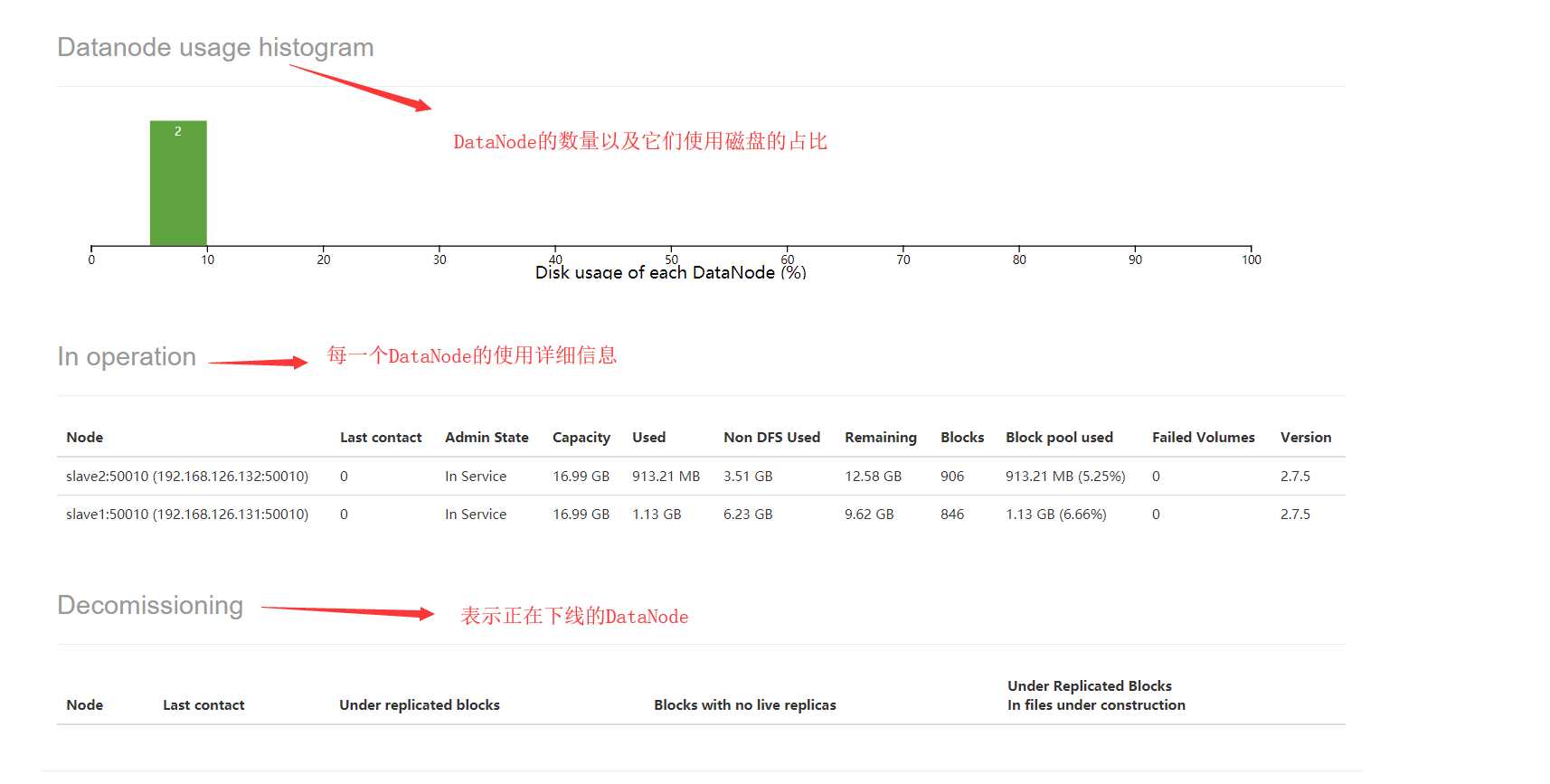
上面有一个Admin State我们有必要说明下,Admin State可以取如下的值:

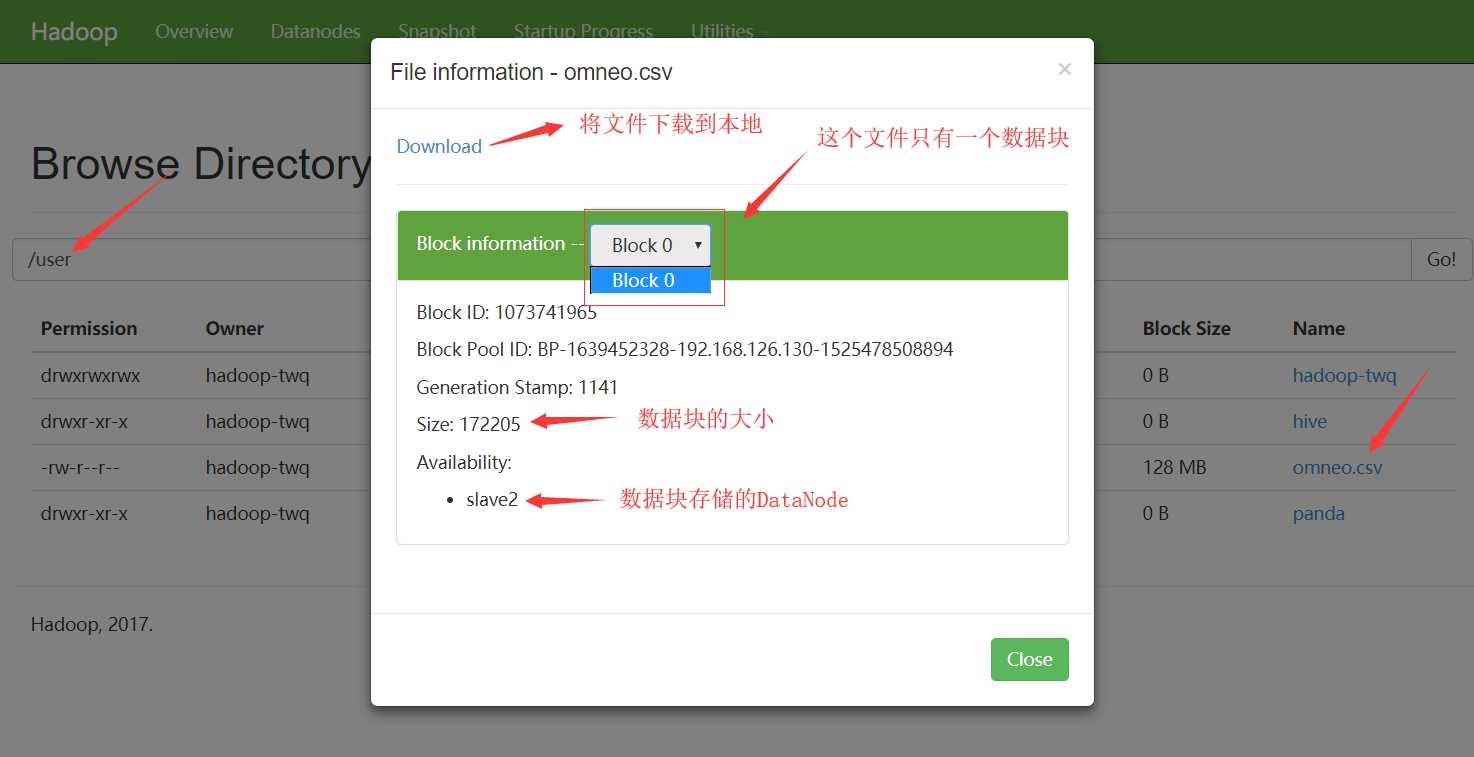
我们这里详细总结下Browse the file system,对于Logs我们在HDFS日志的查看总结中讲解
HDFS Shell命令HDFS提供了和Linux类似的命令来访问文件系统,比如在Linux中想看下文件目录/home/hadoop-twq/test中有哪些文件,我们可以执行:ls /home/hadoop-twq/test
那么在HDFS中也存在ls命令查看某个文件目录中有哪些文件,比如:hadoop fs -ls hdfs://master:9999/user/hadoop-twq/test
当然,我们也可以将hdfs://master:9999去掉,如下:hadoop fs -ls /user/hadoop-twq/test
那为什么可以去掉呢?因为当我们执行hadoop fs的命令的时候,程序会自动去Hadoop的配置core-site.xml中读取配置fs.defaultFS的值## hdfs dfs效果和hadoop fs的效果是一模一样的 hdfs dfs -ls hdfs://master:9999/user/hadoop-twq/test
Hadoop官网的 https://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/FileSystemShell.htmlHDFS文件恢复机制有一个命令我们得特别强调下,那么就是rm的命令,HDFS中的rm命令是删除文件的意思,但是用这个命令删除文件的时候并不是真正的删除,而是将文件放到对应的Trash目录中(其实和window电脑的回收站是一样的意思),但是这个Trash机制默认不是打开的,我们需要在core-site.xml中打开如下的配置:<!--单位是:分钟。默认值是0,表示禁用Trash机制--> <!--下面的意思是保存删除的文件在.Trash文件目录中5分钟--> <property> <name>fs.trash.interval</name> <value>5</value> </property>
那么在一个HDFS文件被删除后,5分钟之内还是可以从Trash目录中恢复出来的。比如,我们删除一个文件:hadoop fs -rm -r /user/hadoop-twq/cmd-20180326
那么上面删除的文件就会move到文件目录hdfs://master:9999/user/hadoop-twq/.Trash/180326230000/user/hadoop-twq/下,保存5分钟,在5分钟之内我们都可以通过下如的命令进行数据的恢复:adoop fs -cp hdfs://master:9999/user/hadoop-twq/.Trash/180326230000/user/hadoop-twq/* /user/hadoop-twq
如果我们确定直接删除文件,并不需要进行保存的话,我们可以选择不保存文件到Trash目录下:hadoop fs -rm -r -skipTrash /user/hadoop-twq/cmd-20180326
Http方式访问HDFS在使用Http访问HDFS之前,我们需要打开webhdfs,可以通过如下的配置打开:<!--打开NameNode和DataNode的 WebHDFS (REST API)--> <!-- 这个参数默认是ture,即默认WebHDFS是打开的--> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
然后,我们可以在Linux上使用命令curl通过http url的方式访问HDFS文件,比如:curl -i "http://master:50070/webhdfs/v1/user/hadoop-twq/cmd/error.txt?op=LISTSTATUS"
返回的是一个Json,如下:HTTP/1.1200 OK Cache-Control: no-cache Expires: Sun,27 Jan 201901:03:02 GMT Date: Sun,27 Jan 201901:03:02 GMT Pragma: no-cache Expires: Sun,27 Jan 201901:03:02 GMT Date: Sun,27 Jan 201901:03:02 GMT Pragma: no-cache Content-Type: application/json Transfer-Encoding: chunked Server:Jetty(6.1.26) { "FileStatuses": {"FileStatus": [ { "accessTime":1543310078655, ## 表示访问时间 "blockSize":134217728, ## 表示设置的数据块的大小(这里是128M) "childrenNum":0, ## 表示含有多少个子文件 "fileId":36514, ## 唯一ID "group":"supergroup", ## 文件所属组 "length":0, ## 文件的大小 "modificationTime":1543310078685, ## 文件修改时间 "owner":"hadoop-twq", ## 文件所有者 "pathSuffix":"", ## 路径后缀 "permission":"644", ## 文件权限 "replication":1, ## 文件对应的数据块的备份数 "storagePolicy":0, ## 存储策略 "type":"FILE" ## 类型,这里是文件 } ] } }
标签:而且 tran -- word sid ocs pac border 元数据
原文地址:https://www.cnblogs.com/tesla-turing/p/11488100.html