标签:djang 教程 三种方式 clu 开放 variable play com 函数
#注册drf INSTALLED_APPS = [ # ... ‘api.apps.ApiConfig‘, ‘rest_framework‘, ] ? #配置数据库 DATABASES = { ‘default‘: { ‘ENGINE‘: ‘django.db.backends.mysql‘, ‘NAME‘: ‘dg_proj‘, ‘USER‘: ‘root‘, ‘PASSWORD‘: ‘123‘, } } """ 在任何(根或者app)的__init__文件中声明数据库 import pymysql pymysql.install_as_MySQLdb() """ #国际化 提示时间等从英语转化为汉字 LANGUAGE_CODE = ‘zh-hans‘ TIME_ZONE = ‘Asia/Shanghai‘ USE_I18N = True USE_L10N = True USE_TZ = False ? # 开放图像路经,后面还有他用,这个配置和静态文件路径配置非常相似,暴露图像资源 MEDIA_URL = ‘/media/‘ MEDIA_ROOT = os.path.join(BASE_DIR, ‘media‘)
# 主路由 from django.conf.urls import url, include from django.contrib import admin from django.views.static import serve #开放静态文件 from django.conf import settings urlpatterns = [ url(r‘^admin/‘, admin.site.urls), url(r‘^api/‘, include(‘api.urls‘)), url(r‘^media/(?P<path>.*)‘, serve, {‘document_root‘: settings.MEDIA_ROOT}), ] # 固定写法 url + serve + {‘document_root‘: ‘路径‘} # 可以点进serve源码,功能注释有样式解释 ? # 子路由 from django.conf.urls import url from . import views urlpatterns = [ url(r‘^books/$‘, views.Book.as_view()), url(r‘^books/(?P<pk>.*)/$‘, views.Book.as_view()), url(r‘^publishes/$‘, views.Publish.as_view()), url(r‘^publishes/(?P<pk>.*)/$‘, views.Publish.as_view()), url(r‘^v2/books/$‘, views.V2Book.as_view()), url(r‘^v2/books/(?P<pk>.*)/$‘, views.V2Book.as_view()), ]
auth组件中我们自定义的user表继承abstractuser而不是继承他的功能更丰富的子类user,为什么?因为我们自定义user表是想创建我们自己的user表,不想创建auth_user表,如果继承user那么会自动创建auth_user表,而我们继承abstractser,不会创建auth_user表,只会创建我们自己的user表
# 1) 点进User from django.contrib.auth.models import User # 2)User继承AbstractUser,点进去 class User(AbstractUser): class Meta(AbstractUser.Meta): swappable = ‘AUTH_USER_MODEL‘ # 3)AbstractUser源码里发现有下面的元类 class Meta: verbose_name = _(‘user‘) verbose_name_plural = _(‘users‘) # 该models类被加载后,也不会在数据库创建表,所有基类都应该有下面这个声明 abstract = True
""" Book表:name、price、img、authors、publish、is_delete、create_time ? Publish表:name、address、is_delete、create_time Author表:name、age、is_delete、create_time ? AuthorDetail表:mobile, author、is_delete、create_time BaseModel基表 is_delete、create_time 上面四表继承基表,可以继承两个字段 """
# 将那些大家共有的字段封装成一个基类,所有类都继承该基类, # 记得在元类中声明 abstract = True ,声明不要在数据库中创建该表 class BaseModel(models.Model): is_delete = models.BooleanField(default=False) create_time = models.DateTimeField(auto_now_add=True) ? # 设置 abstract = True 来声明基表,作为基表的Model不会在数据库中形成对应的表 class Meta: abstract = True
https://www.cnblogs.com/xp1315458571/p/11552738.html#_label1
# django脚本话启动 import os, django os.environ.setdefault("DJANGO_SETTINGS_MODULE", "dg_proj.settings") # 加载django配置 django.setup() # 起socket
# 启动django项目有几种方式: # 通过manage.py启动的时候其实是加载了项目环境配置而已, # 项目上线后启动wsgi.py也可以启动项目,因为它内部也有环境配置,现在不行 # 我们自己建启动脚本,放入上面的配置即可在这里启动
sql中多表关系:https://www.cnblogs.com/xp1315458571/p/11384183.html
原生django的orm中多表关系:https://www.cnblogs.com/xp1315458571/p/11557880.html#_label1
1、外键位置:
一对多 - 外键放多的一方,ForeignKey
一对一 - 从逻辑正反向考虑,如作者表与作者详情表,作者删除级联删除详情,详情删除作者依旧存在,所以建议外键在详情表中,
多对多 - 外键在关系表中
2、ORM正向反向连表查询:
正向:通过外键字段 通过详情对象查作者eg: author_detial_obj.author
# detail = models.AuthorDetail.objects.first()
# print(detail.mobile)
# print(detail.author.name)
反向:通过related_name的值 通过作者对象查详情eg:author_obj.detail
# author = models.Author.objects.first()
# print(author.name)
# 声明 related_name=‘detail‘后这样查询,没有声明必须用类名小写查询,这个会报错
# print(author.detail.mobile)
#这个是原始查法,即反向查询类名小写,如果声明 related_name=‘detail‘后,这个就会报错
# print(author.authordetail.mobile)
注:依赖代码见下方4中作者详情表
3、连表操作关系-级联:
1)作者删除,详情级联 - on_delete=models.CASCADE
2)作者删除,详情置空 - null=True, on_delete=models.SET_NULL
3)作者删除,详情重置 - default=0, on_delete=models.SET_DEFAULT
4)作者删除,详情不动 - on_delete=models.DO_NOTHING
注:拿作者与作者详情表举例
4、外键关联字段的参数 - 断关联 db_constraint=False,
原本通过外键是连在一起的,这样有个弊端就是连在一起的表多了很容易形成环,当你想删除一张表的时候必须把有关联的也删除,都形成环了还怎么下手,所以就有了断链接一说,
虽然连接断开了想删谁就删谁,但是依旧不影响连表查询
#i)作者详情表中的 class AuthorDetail(BaseModel): """mobile, author、is_delete、create_time""" mobile = models.CharField(max_length=11) author = models.OneToOneField( # 这个继承ForeignKey,必须设置on_delete to=‘Author‘, db_constraint=False, # 声明False后就是断关联了 related_name=‘detail‘, #反向查询用这个值,即 作者对象.detail 即可 on_delete=models.CASCADE, # 级联删除,1.x中默认的可不写,2.x中必须写 ) #ii)图书表中的 class Book(BaseModel): """name、price、img、authors、publish、is_delete、create_time""" name = models.CharField(max_length=64) price = models.DecimalField(max_digits=5, decimal_places=2) img = models.ImageField(upload_to=‘img‘, default=‘img/default.jpg‘) publish = models.ForeignKey( #外键必须设置on_delete to=‘Publish‘, db_constraint=False, related_name=‘books‘, on_delete=models.DO_NOTHING, ) authors = models.ManyToManyField( #多对多和一对一不一样,这个是在第三张额外关系表中有两个外键,自己本身并未继承外键,不能设置on_delete to=‘Author‘, db_constraint=False, related_name=‘books‘ ) #注:ManyToManyField不能设置on_delete, #OneToOneField(内部继承外键)、ForeignKey必须设置on_delete(django1.x系统默认级联,但是django2.x必须手动明确)

from django.db import models # 图书管理系统:Book、Author、AuthorDetail、Publish """ Book表: name、price、img、authors、publish、is_delete、create_time Publish表: name、address、is_delete、create_time Author表: name、age、is_delete、create_time AuthorDetail表: mobile, author、is_delete、create_time """ # 1) 基表 class BaseModel(models.Model): is_delete = models.BooleanField(default=False) create_time = models.DateTimeField(auto_now_add=True) # 作为基表的Model不能在数据库中形成对应的表,设置 abstract = True class Meta: abstract = True class Book(BaseModel): """name、price、img、authors、publish、is_delete、create_time""" name = models.CharField(max_length=64) price = models.DecimalField(max_digits=5, decimal_places=2) img = models.ImageField(upload_to=‘img‘, default=‘img/default.jpg‘) publish = models.ForeignKey( to=‘Publish‘, # 不写默认为True即有关联,改为False即断开连接,依然可以联表查询,但是删除表时就不用考虑关联表了 db_constraint=False, # 断关联 related_name=‘books‘, # 反向查询字段:publish_obj.books 就能访问所有出版的书 on_delete=models.DO_NOTHING, # 设置连表操作关系 ) authors = models.ManyToManyField( to=‘Author‘, db_constraint=False, related_name=‘books‘ ) # 序列化插拔式属性 - 完成连表查询 #通过设置这样的插拔属性,跨表查询再也不难了,一个表里就可以直接得到其他关联表所有属性 #其他地方比如序列化中选择参与序列化字段,用到这些属性就加上,不需要时就去掉该属性,非常方便 @property #将方法伪装成属性,也就是说Book类有了publish_name属性,不要这个装饰器也可以,官方文档推荐使用,更健壮 def publish_name(self): return self.publish.name # 正向查询通过外键publish @property def author_list(self): return self.authors.values(‘name‘, ‘age‘, ‘detail__mobile‘).all() # authors是正向的字段名,detail__mobile是反向查询字段加orm双下划线查询,本来是类名小写authordetail的,因为规定了反向查询字段,就用反向字段代替类名小写 #不好的一点是,传给前端的字典数据中该k为detail__mobile,而不是mobile # 之前在书籍表里是无法跨两张表查询到作者号码,但是这样自定义插拔就可以实现,简化了跨表查询 class Meta: db_table = ‘book‘ verbose_name = ‘书籍‘ verbose_name_plural = verbose_name def __str__(self): return self.name class Publish(BaseModel): """name、address、is_delete、create_time""" name = models.CharField(max_length=64) address = models.CharField(max_length=64) class Meta: db_table = ‘publish‘ verbose_name = ‘出版社‘ verbose_name_plural = verbose_name def __str__(self): return self.name class Author(BaseModel): """name、age、is_delete、create_time""" name = models.CharField(max_length=64) age = models.IntegerField() class Meta: db_table = ‘author‘ verbose_name = ‘作者‘ verbose_name_plural = verbose_name def __str__(self): return self.name class AuthorDetail(BaseModel): """mobile, author、is_delete、create_time""" mobile = models.CharField(max_length=11) author = models.OneToOneField( to=‘Author‘, db_constraint=False, related_name=‘detail‘, on_delete=models.CASCADE, ) class Meta: db_table = ‘author_detail‘ verbose_name = ‘作者详情‘ verbose_name_plural = verbose_name def __str__(self): return ‘%s的详情‘ % self.author.name
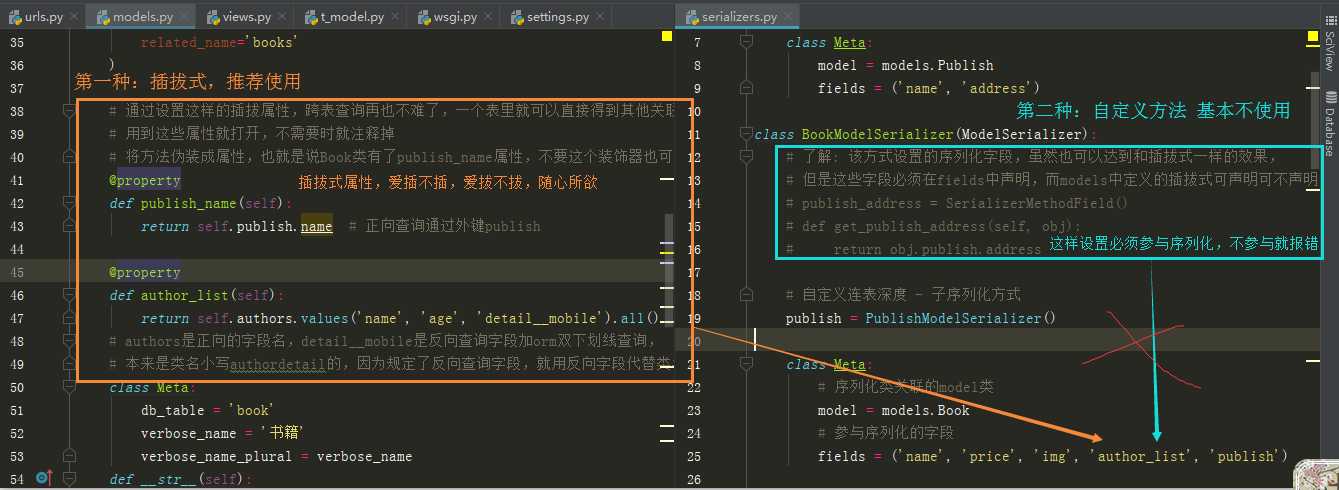
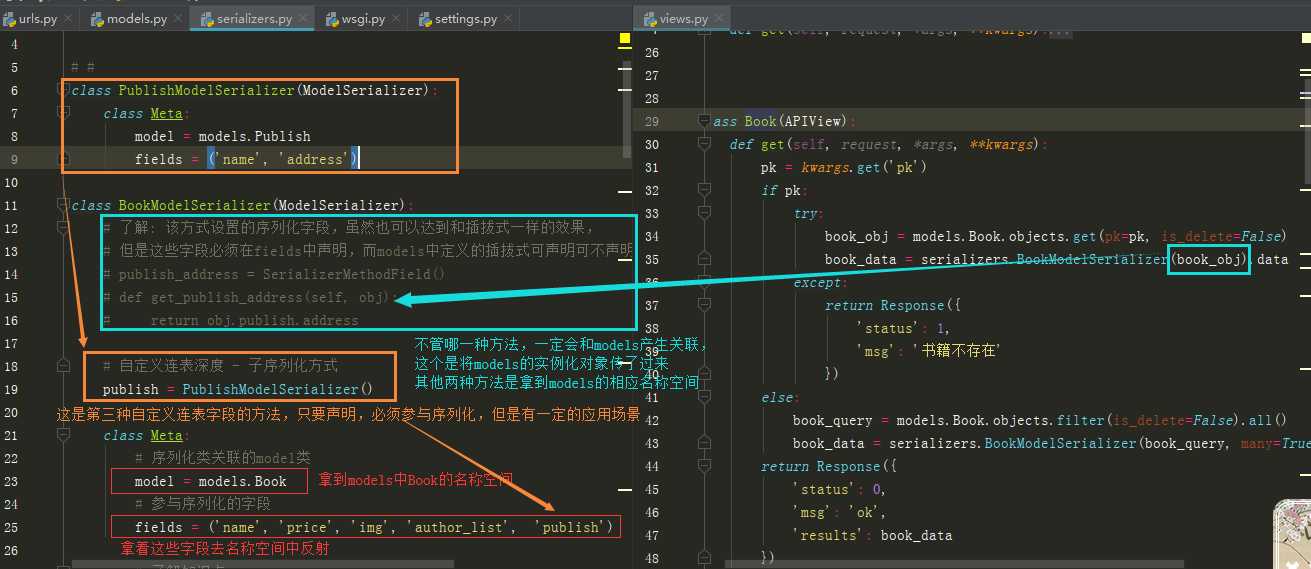
from rest_framework.serializers import ModelSerializer, SerializerMethodField from rest_framework.exceptions import ValidationError from . import models # 可以单独作为Publish接口的序列化类,也可以作为Book序列化外键publish辅助的序列化组件 class PublishModelSerializer(ModelSerializer): class Meta: model = models.Publish fields = (‘name‘, ‘address‘) class BookModelSerializer(ModelSerializer): # 了解 不用: 该方式设置的序列化字段,虽然也可以达到和插拔式一样的效果, # 但是这些字段必须在fields中声明,而models中定义的插拔式可声明可不声明 # publish_address = SerializerMethodField() # def get_publish_address(self, obj): # return obj.publish.address # 自定义连表深度 - 子序列化方式 - 该方式不能参与反序列化,使用在序列化反序列化共存时,不能书写 publish = PublishModelSerializer() class Meta: # 序列化类关联的model类 model = models.Book # 自定义参与序列化的字段,指谁打谁,随意推荐这种 fields = (‘name‘, ‘price‘, ‘img‘, ‘author_list‘, ‘publish‘) # 了解知识点 # 所有字段,都不常用了解即可 # fields = ‘__all__‘ # 与fields不共存,exclude排除哪些字段 # exclude = (‘id‘, ‘is_delete‘, ‘create_time‘) # 自动连表深度,本来查到的结果外键关联信息是代码形式,如0/1,规定深度可以显示外键关联表的具体信息如:男/女 # depth = 1
class Book(APIView): def get(self, request, *args, **kwargs): pk = kwargs.get(‘pk‘) if pk: try: book_obj = models.Book.objects.get(pk=pk, is_delete=False) # 删除的用户就不用查了 book_data = serializers.BookModelSerializer(book_obj).data except: return Response({ ‘status‘: 1, ‘msg‘: ‘书籍不存在‘ }) else: book_query = models.Book.objects.filter(is_delete=False).all() book_data = serializers.BookModelSerializer(book_query, many=True).data return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: book_data })
urlpatterns = [ url(r‘^books/$‘, views.Book.as_view()), url(r‘^books/(?P<pk>.*)/$‘, views.Book.as_view()), ]
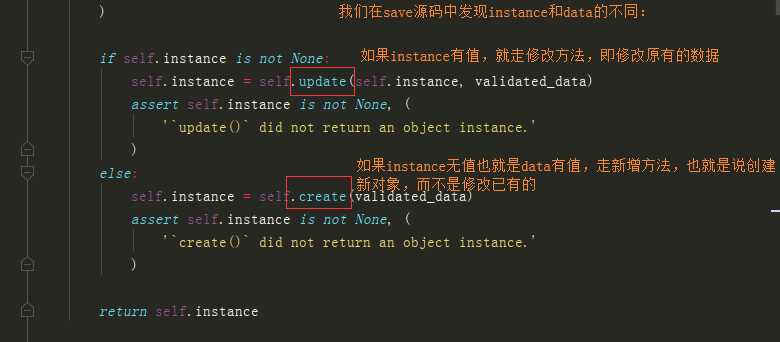
""" 1)设置必填与选填序列化字段,设置系统校验规则 2)为需要额外校验的字段提供局部钩子函数,如果该字段不入库,且不参与全局钩子校验,可以将值取出校验 3)为有联合关系的字段们提供全局钩子函数,如果某些字段不入库,可以将值取出校验 4) # ModelSerializer类已经帮我们实现了 create 与 update 方法,不需重写 """ class BookModelDeserializer(ModelSerializer): class Meta: model = models.Book fields = (‘name‘, ‘price‘, ‘publish‘, ‘authors‘) # extra_kwargs 固定语法 用来定义反序列化字段的 系统校验规则 和返回错误信息 # 例如fields中有img字段,前端就算不传图片也不会报错,因为有默认值的字段默认可以不传, # 想规定必须要,就可以在下面加入‘img‘: {‘required‘: True,‘error_messages‘: {‘required‘: ‘必填项‘}} extra_kwargs = { ‘name‘: { ‘required‘: True, ‘min_length‘: 1, ‘error_messages‘: { ‘required‘: ‘必填项‘, ‘min_length‘: ‘太短‘, } } } # 真正强大的不是系统校验规则而是全局和局部钩子 # 局部钩子 def validate_name(self, value): # 书名不能包含 g 字符 if ‘g‘ in value.lower(): raise ValidationError(‘该g书不能出版‘) return value # 全局钩子 def validate(self, attrs): publish = attrs.get(‘publish‘) name = attrs.get(‘name‘) if models.Book.objects.filter(name=name, publish=publish): raise ValidationError({‘book‘: ‘该书已存在‘}) return attrs ? # ModelSerializer类已经帮我们实现了 create 与 update 方法 ?
class Book(APIView): def post(self, request, *args, **kwargs): request_data = request.data book_ser = serializers.BookModelDeserializer(data=request_data) # raise_exception=True:当校验失败,马上终止当前视图方法,抛异常返回给前台,可以在is_valid源码参数中看到,这样写就不能自定义response了 book_ser.is_valid(raise_exception=True) book_obj = book_ser.save() return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: serializers.BookModelSerializer(book_obj).data })
urlpatterns = [ url(r‘^books/$‘, views.Book.as_view()), url(r‘^books/(?P<pk>.*)/$‘, views.Book.as_view()), ]
""" 1) fields中设置所有序列化与反序列化字段 2) extra_kwargs划分只序列化或只反序列化字段 write_only:只反序列化 read_only:只序列化 自定义字段默认只序列化(read_only) 3) 设置反序列化所需的 系统、局部钩子、全局钩子 等校验规则 4)一般的序列化我们只需要这一个整合的序列化类就可以,一个序列化类对应一个视图类,一个视图类对应六大接口 除非说要求贼高,比如权限不一样得到字段不一样时序列化和反序列化就必须分开处理了 """ class V2BookModelSerializer(ModelSerializer): class Meta: model = models.Book fields = (‘name‘, ‘price‘, ‘img‘, ‘author_list‘, ‘publish_name‘, ‘publish‘, ‘authors‘) extra_kwargs = { ‘name‘: { # 这些系统校验规则依然可以有 ‘required‘: True, ‘min_length‘: 1, ‘error_messages‘: { ‘required‘: ‘必填项‘, ‘min_length‘: ‘太短‘, } }, ‘publish‘: { ‘write_only‘: True #只参与反序列化,入库 }, ‘authors‘: { ‘write_only‘: True }, ‘img‘: { ‘read_only‘: True, # 只参与序列化,出库,即使你前台传了我也不用只用默认的(你只传路经我怎么知道该路径下有没有,不能走字符串上传,必须走文件上传来实现) }, ‘author_list‘: { ‘read_only‘: True, # 自定义字段只序列化,出库 }, ‘publish_name‘: { ‘read_only‘: True, } } #钩子和分开写时是一样的 def validate_name(self, value): # 书名不能包含 g 字符 if ‘g‘ in value.lower(): raise ValidationError(‘该g书不能出版‘) return value ? def validate(self, attrs): publish = attrs.get(‘publish‘) name = attrs.get(‘name‘) if models.Book.objects.filter(name=name, publish=publish): raise ValidationError({‘book‘: ‘该书已存在‘}) return attrs
class V2Book(APIView):
# 单查:有pk # 群查:无pk def get(self, request, *args, **kwargs): pk = kwargs.get(‘pk‘) if pk: try: book_obj = models.Book.objects.get(pk=pk, is_delete=False) book_data = serializers.V2BookModelSerializer(book_obj).data except: return Response({ ‘status‘: 1, ‘msg‘: ‘书籍不存在‘ }) else: book_query = models.Book.objects.filter(is_delete=False).all() book_data = serializers.V2BookModelSerializer(book_query, many=True).data return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: book_data })
# 单增:传的数据是与model对应的字典 # 群增:传的数据是 装多个 model对应字典 的列表 def post(self, request, *args, **kwargs): request_data = request.data if isinstance(request_data, dict): many = False elif isinstance(request_data, list): many = True else: return Response({ ‘status‘: 1, ‘msg‘: ‘数据有误‘, }) book_ser = serializers.V2BookModelSerializer(data=request_data, many=many) # 当校验失败,马上终止当前视图方法,抛异常返回给前台 book_ser.is_valid(raise_exception=True) book_result = book_ser.save() return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: serializers.V2BookModelSerializer(book_result, many=many).data }) ?
# 单删:有pk # 群删:有pks | {"pks": [1, 2, 3]} # 删除不需要走序列化,没有数据交互,只是更改了状态码 # 走delete请求过来直接跳到这里 def delete(self, request, *args, **kwargs): pk = kwargs.get(‘pk‘) if pk: pks = [pk] else: pks = request.data.get(‘pks‘) if models.Book.objects.filter(pk__in=pks, is_delete=False).update(is_delete=True): #这个是有返回值的,返回值是受影响的行数,可以点进update源码看一下 return Response({ ‘status‘: 0, ‘msg‘: ‘删除成功‘, }) return Response({ ‘status‘: 1, ‘msg‘: ‘删除失败‘, })
""" 1) 前台提供修改的数据要入库,就需要校验,校验的数据应该在实例化“序列化类对象”时,赋值给data 2)要修改,就必须明确被修改的模型类对象,即修改谁,并在实例化“序列化类对象”时,赋值给instance 3)整体修改,所有校验规则有required=True的字段,都必须提供,因为在实例化“序列化类对象”时,参数partial默认为False 注:如果partial值设置为True,就是可以局部改 1)单整体修改,一般用put请求: V2BookModelSerializer( instance=要被更新的对象, data=用来更新的数据, partial=默认False,必须的字段全部参与校验 ) 2)单局部修改,一般用patch请求: V2BookModelSerializer( instance=要被更新的对象, data=用来更新的数据, partial=设置True,必须的字段都变为选填字段 ) 注:partial设置True的本质就是使字段 required=True 校验规则失效 """

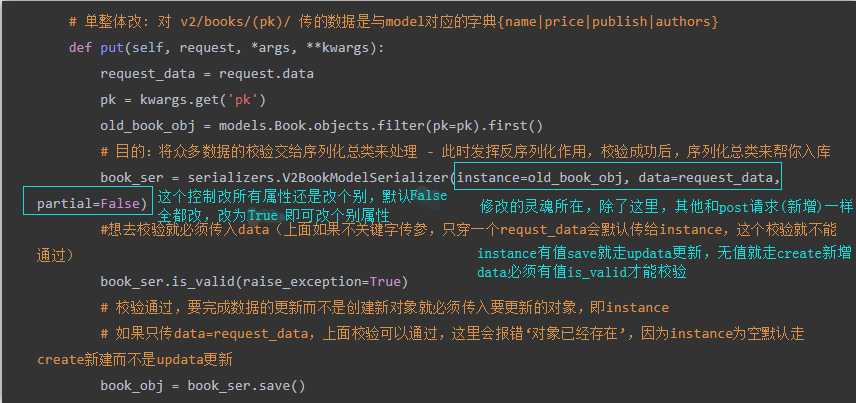
# 单整体改: 对 v2/books/(pk)/ 传的数据是与model对应的字典{name|price|publish|authors} def put(self, request, *args, **kwargs): request_data = request.data pk = kwargs.get(‘pk‘) old_book_obj = models.Book.objects.filter(pk=pk).first() # 目的:将众多数据的校验交给序列化总类来处理 - 此时发挥反序列化作用,校验成功后,序列化总类来帮你入库 book_ser = serializers.V2BookModelSerializer(instance=old_book_obj, data=request_data, partial=False) #想去校验就必须传入data(上面如果不关键字传参,只穿一个requst_data会默认传给instance,这个校验就不能通过) book_ser.is_valid(raise_exception=True) # 校验通过,要完成数据的更新而不是创建新对象就必须传入要更新的对象,即instance # 如果只传data=request_data,上面校验可以通过,这里会报错‘对象已经存在’,因为instance为空默认走create新建而不是updata更新 book_obj = book_ser.save() return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: serializers.V2BookModelSerializer(book_obj).data })
# 重点:ListSerializer与ModelSerializer建立关联的是: # ModelSerializer的Meta类的 - list_serializer_class
# 重写upadte class V2BookListSerializer(ListSerializer): def update(self, instance, validated_data): # print(instance) # 要更新的对象们;[obj1,obj2,...] # print(validated_data) # 更新的对象对应的数据们 [{},{},...] # print(self.child) # 服务的模型序列化类 - V2BookModelSerializer for index, obj in enumerate(instance): self.child.update(obj, validated_data[index]) return instance # 原模型序列化类变化 class V2BookModelSerializer(ModelSerializer): class Meta: # ... # 群改,需要设置 自定义ListSerializer,重写群改的 update 方法 list_serializer_class = V2BookListSerializer # ...
class V2Book(APIView): # 单局部改:对 v2/books/(pk)/ 传的数据,数据字段key都是选填 # 单改请求数据 {name:123} # 群局部改:对 v2/books/ 传的数据,数据字段key都是选填 # 群该请求数据 - [{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}] def patch(self, request, *args, **kwargs): request_data = request.data pk = kwargs.get(‘pk‘) # 无论是修改单还是多个对象,统一按照多来处理,many=True,只不过单是多的特例 # 将单改,群改的数据都格式化成 pks=[要需要的对象主键标识] | request_data=[每个要修改的对象对应的修改数据] if pk and isinstance(request_data, dict): # 单改,url有pk,数据是字典 pks = [pk, ] request_data = [request_data, ] elif not pk and isinstance(request_data, list): # 群改,url无pk,数据是字典的列表 pks = [] for dic in request_data: # 遍历前台数据[{pk:1, name:123}, {pk:3, price:7}, {pk:7, publish:2}],拿一个个字典 pk = dic.pop(‘pk‘, None) if pk: pks.append(pk) else: return Response({ ‘status‘: 1, ‘msg‘: ‘数据有误‘, }) else: return Response({ ‘status‘: 1, ‘msg‘: ‘数据有误‘, }) ? # pks与request_data数据筛选, # 1)将pks中的没有对应数据的pk与数据已删除的pk移除,request_data中对应索引位上的数据也移除 # 2)将合理的pks转换为对应 objs objs = [] new_request_data = [] for index, pk in enumerate(pks): try: # pk对应的数据合理,将合理的对象存储-数据得存在且没有删除 obj = models.Book.objects.get(pk=pk,is_delete=False) objs.append(obj) # 对应索引的数据就需要保存下来 new_request_data.append(request_data[index]) except: # 重点:反面教程—循环内部永远不要操作列表长度,你把3弹出,4变成3,下次循环去循环4找不到,报错 # 不能弹出,那么我们就变减为增,在上面操作 # pk对应的数据有误,将对应索引的data中request_data中移除 # index = pks.index(pk) # 列表取索引 # request_data.pop(index) continue ? book_ser = serializers.V2BookModelSerializer(instance=objs, data=new_request_data, partial=True, many=True)
# 可局部改 partial=True,群 要声明 many=True
# 一旦设置了many=True,反序列化情况下的create、update就不再调用ModelSerializer的
# 而是调用 ModelSerializer.Meta.list_serializer_class 指向的 ListSerializer 类的create、update
# ListSerializer默认只实现了群增的create,要实现群改,必须重写update,
book_ser.is_valid(raise_exception=True) # 校验不通过自动抛异常 book_objs = book_ser.save() ? return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: serializers.V2BookModelSerializer(book_objs, many=True).data })
urlpatterns = [ url(r‘^v2/books/$‘, views.V2Book.as_view()), url(r‘^v2/books/(?P<pk>.*)/$‘, views.V2Book.as_view()), ]
# 1)在视图类中实例化序列化对象时,可以设置context内容 # 2)在序列化类中的局部钩子、全局钩子、create、update方法中,都可以用self.context访问视图类传递过来的内容 ? ? # 需求: # 1) 在视图类中,可以通过request得到登陆用户request.user # 2) 在序列化类中,要完成数据库数据的校验与入库操作,可能会需要知道当前的登陆用户,但序列化类无法访问request # 3) 在视图类中实例化序列化对象时,将request对象传递进去
class Book(APIView): def post(self, request, *args, **kwargs): book_ser = serializers.BookModelSerializer(data=request_data,context={‘request‘:request}) book_ser.is_valid(raise_exception=True) book_result = book_ser.save() return Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: serializers.BookModelSerializer(book_result).data })
class BookModelSerializer(ModelSerializer): class Meta: model = models.Book fields = (‘name‘, ‘price‘) def validate_name(self, value): # 局部狗子 print(self.context.get(‘request‘).method) # get、patch、post、delete等 return value
# 1.我们发现在我们写的各种方法中要频繁地返回各种response,形式大概一样,能不能封装起来呢? # 常规的response数据格式: Response({ ‘status‘: 0, ‘msg‘: ‘ok‘, ‘results‘: [], ‘token‘: ‘‘ # 可能有一个或多个类似这样的额外的key-value数据,所以加上**kwargs参数 },status=http_status,headers=headers,exception=True|False)
# 2.看response源码找灵感 def __init__(self, data=None, status=None,template_name=None, headers=None, exception=False, content_type=None): super().__init__(None, status=status)
from rest_framework.response import Response ? class APIResponse(Response): # 模板不用要,因为我们封装就是给我们自己项目用,都是json,content_type默认json,也不要 def __init__(self, data_status=0, data_msg=‘ok‘, results=None, http_status=None, headers=None, exception=False, **kwargs): # data的初始状态:状态码与状态信息 data = { ‘status‘: data_status, ‘msg‘: data_msg, } # data的响应数据体 # results可能是False、0等数据,这些数据某些情况下也会作为合法数据返回 if results is not None: data[‘results‘] = results # data响应的其他内容 # if kwargs is not None: # for k, v in kwargs.items(): # setattr(data, k, v) # data[k]=v # 这样也行 data.update(kwargs) # 直接这样更新增加键值对更简单 ? super().__init__(data=data, status=http_status, headers=headers, exception=exception)
from utils.response import APIResponse ? **...... # 封装前写法++++++++++++++++++++++++++++++++++++ # return Response({ # ‘status‘: 0, # ‘msg‘: ‘ok‘, # ‘results‘: serializers.V2BookModelSerializer(book_objs, many=True).data # }) ? # 采用 自定义二次封装 (返回Json格式) 的响应对象 ++++++++++++++++++++++++++++ book_objs_data = serializers.V2BookModelSerializer(book_objs, many=True).data return APIResponse(1, ‘ooo‘, token="123.abc.xyz", results=book_objs_data, http_status=201) # 位置传参或者关键字传参,额外
对应不上的都放进kwargs
ModelSerializer(重点) 基表 测试脚本 多表关系建外键 正反查 级联 插拔式连表 序列化反序列化整合 增删查 封装response
标签:djang 教程 三种方式 clu 开放 variable play com 函数
原文地址:https://www.cnblogs.com/xp1315458571/p/11695596.html
