标签:plt 小明 函数 优秀 方式 col 返回 axis 分数
通过isnull和notnull方法,可以返回布尔值的对象。
这时通过求和可以获取每列的缺失值数量,再通过求和就可以获得整个DataFrame的缺失值数量
>>> from pandas import Series,DataFrame >>> import pandas as pd >>> import numpy as np >>> df1 = DataFrame([[5,3,5],[1,6,np.nan],["lili",np.nan,"pop"],[np.nan,"a","b"]])
>>> df1 0 1 2 0 5 3 5 1 1 6 NaN 2 lili NaN pop 3 NaN a b
>>> df1.isnull() 0 1 2 0 False False False 1 False False True 2 False True False 3 True False False
>>> df1.notnull() 0 1 2 0 True True True 1 True True False 2 True False True 3 False True True
>>> df1.isnull().sum() 0 1 1 1 2 1 dtype: int64 >>> df1.isnull().sum().sum() 3
>>> df1.info() <class ‘pandas.core.frame.DataFrame‘> RangeIndex: 4 entries, 0 to 3 Data columns (total 3 columns): 0 3 non-null object 1 3 non-null object 2 3 non-null object dtypes: object(3) memory usage: 224.0+ bytes
>>> df1.dropna() 0 1 2 0 5 3 5
>>> df2 0 1 2 3 0 0.0 1.0 2.0 NaN 1 4.0 5.0 6.0 NaN 2 NaN NaN NaN NaN >>> df2.dropna(how="all") 0 1 2 3 0 0.0 1.0 2.0 NaN 1 4.0 5.0 6.0 NaN
>>> df2.dropna(how="all",axis=1) 0 1 2 0 0.0 1.0 2.0 1 4.0 5.0 6.0 2 NaN NaN NaN
通过fillna方法可以将缺失值替换为常数值
>>> df2.fillna(0) 0 1 2 3 0 0.0 1.0 2.0 0.0 1 4.0 5.0 6.0 0.0 3 0.0 0.0 0.0 0.0
在fillna中传入字典结构数据,可以针对不同列填充不同的值,fillna返回的新对象不会对原数据库进行修改,可通过inplace就地进行修改
>>> df2.fillna({1:6,3:0})
0 1 2 3
0 0.0 1.0 2.0 0.0
1 4.0 5.0 6.0 0.0
2 NaN 6.0 NaN 0.0
>>>
>>> df2.fillna({1:6,3:0},inplace=True)
>>> df2
0 1 2 3
0 0.0 1.0 2.0 0.0
1 4.0 5.0 6.0 0.0
2 NaN 6.0 NaN 0.0
>>>
>>> df2.fillna(method="ffill") 0 1 2 3 0 0.0 1.0 2.0 0.0 1 4.0 5.0 6.0 0.0 2 4.0 6.0 6.0 0.0
>>> df2[0] = df2[0].fillna(df2[0].mean()) >>> df2 0 1 2 3 0 0.0 1.0 2.0 0.0 1 4.0 5.0 6.0 0.0 2 2.0 6.0 NaN 0.0 >>>
在DataFrame中,通过duplicated方法判断各行是否有重复数据
>>> data = { ... "name":["张三","李四","张三","小明"], ... "sex":["female","male","female","male"], ... "year":[2001,2002,2001,2002], ... "city":["北京","上海","北京","北京"], ... } >>> >>> df1 = DataFrame(data) >>> df1 name sex year city 0 张三 female 2001 北京 1 李四 male 2002 上海 2 张三 female 2001 北京 3 小明 male 2002 北京 >>> df1.duplicated() 0 False 1 False 2 True 3 False dtype: bool
>>> df1.drop_duplicates() name sex year city 0 张三 female 2001 北京 1 李四 male 2002 上海 3 小明 male 2002 北京 >>>
>>> df1.drop_duplicates(["sex","year"]) name sex year city 0 张三 female 2001 北京 1 李四 male 2002 上海 >>>
>>> df1.drop_duplicates(["sex","year"]) name sex year city 0 张三 female 2001 北京 1 李四 male 2002 上海 >>>
在pandas中,通过replace可完成替换值的功能,也可以对不同值进行多值替换,参数传入方式可以是列表也可以是字典格式
>>> df1.replace("","不详") name sex year city 0 张三 female 2001 北京 1 李四 male 2002 上海 2 张三 不详 2001 不详 3 小明 male 2002 北京 >>>
>>> df1.replace(["",2001],["不详",2002]) name sex year city 0 张三 female 2002 北京 1 李四 male 2002 上海 2 张三 不详 2002 不详 3 小明 male 2002 北京 >>>
>>> df1.replace({"":"不详",2001:2002})
name sex year city
0 张三 female 2002 北京
1 李四 male 2002 上海
2 张三 不详 2002 不详
3 小明 male 2002 北京
>>>
在pandas中,通过map方法可以通过if函数实现分数等级的划分
>>> data = { ... "name":["张三","李四","王五","小明"], ... "math":[79,52,63,92] ... } >>> df2 = DataFrame(data) >>> df2 name math 0 张三 79 1 李四 52 2 王五 63 3 小明 92 >>>
>>> def f(x): ... if x>=90: ... return "优秀" ... elif 70<=x<90: ... return "良好" ... elif 60<=x<70: ... return "合格" ... else: ... return "不合格" ... >>> df2["class"] = df2["math"].map(f) >>> df2 name math class 0 张三 79 良好 1 李四 52 不合格 2 王五 63 合格 3 小明 92 优秀 >>>
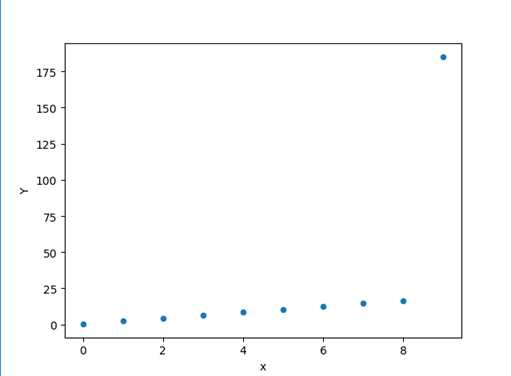
在数据分析中,通常会通过一些可视化的方法去找离群点,这些离群点可能就是异常值。
>>> df3 = DataFrame(np.arange(10),columns=["x"]) >>> df3["Y"]=2*df3["x"]+0.5 >>> df3.iloc[9,1]=185 >>> df3 x Y 0 0 0.5 1 1 2.5 2 2 4.5 3 3 6.5 4 4 8.5 5 5 10.5 6 6 12.5 7 7 14.5 8 8 16.5 9 9 184
>>> import matplotlib.pyplot as plt >>> df3.plot(kind="scatter",x="x",y="Y") <matplotlib.axes._subplots.AxesSubplot object at 0x000001BAE83A8188> >>> plt.show()
标签:plt 小明 函数 优秀 方式 col 返回 axis 分数
原文地址:https://www.cnblogs.com/Tunan-Ki/p/11756322.html