标签:理解 img 资源 根据 info 区别 style image ssd
RetinaNet,SSD,YOLOv3,Faster R-CNN等都是Anchor-based的检测器,即需要预定义的Anchor boxes来进行训练。FCOS是一种Anchor-free和Proposal-free的检测器,即不需要预定义Anchor boxes来进行训练,从而节省了对计算资源的占用。
根据我的理解,FCOS和Faster R-CNN的区别主要表现在:
(1) Faster R-CNN是每个点提出N个Proposal,N一般等于9(预设了3种长宽比例,3种尺寸因此是9个Proposal),每一个Proposal的类别如何确定呢?就需要计算Proposal和GT Box的IOU了,IOU达到一定的程度,Proposal就算是这个GT Box的类,要求这个Proposal回归到这个GT Box;而FCOS每个点只提出一个Proposal,这个Proposal的类别如何确定?就是这个点在哪一个GT Box里面,它提出的Proposal就属于哪一个GT Box的类,当然也要求这个Proposal回归到这个GT Box。但是感觉Faster R-CNN的分类更好训练一些,毕竟Proposal和GT Box有比较大的IOU,FCOS靠近GT Box中心的点的类还比较好训练,距离中心比较远的点估计不好训练吧。

(2) FCOS多出来一个Center-ness:
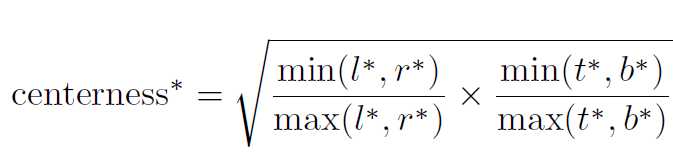
这是因为距离目标中心越远的位置预测出的Proposal质量越低,所以FCOS增加了一个分支预测Center-ness,越靠近GT Box的中心,这个Center-ness的值就越接近1。

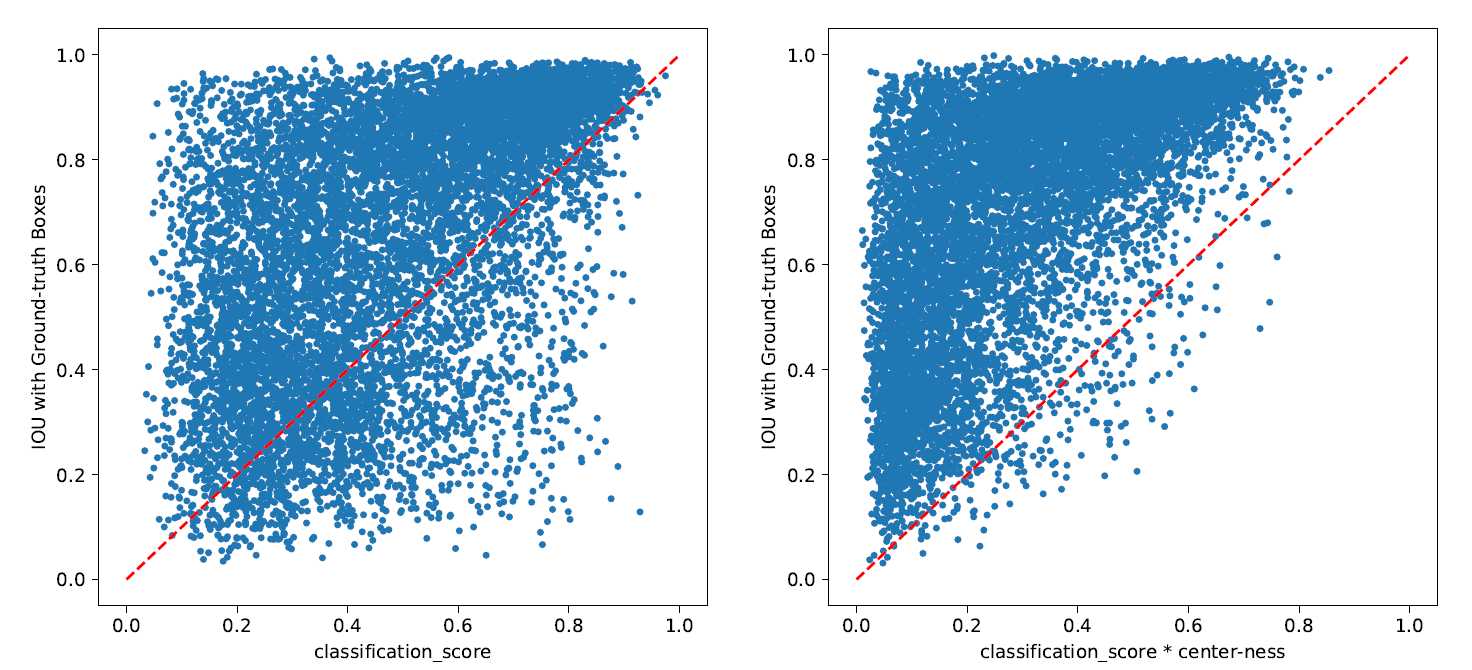
预测的时候结合对应的分类分数以及Center-ness的值来对Proposal进行排序,从而抑制了距离目标中心越远的位置预测出的Proposal,这种方法是很巧妙的,值得借鉴。
标签:理解 img 资源 根据 info 区别 style image ssd
原文地址:https://www.cnblogs.com/mstk/p/11768684.html