标签:def 返回 img yun end 自身 代码 lease 基本
原文:https://segmentfault.com/a/1190000011425787?utm_source=tag-newest
核心思想:把出现过的字符串映射到记号上,这样就可能用较短的编码来表示长的字符串,实现压缩
比如对于字符串 ABABAB 可以看到字串 AB 在后面重复了,就可以用一个特殊的记号表示 AB ,比如使用 2,原来的字符串就表示为 AB22 ,那么 2 就可以称为 AB 的记号
那么如果规定 0 表示 A,1 表示 B,实际上最后得到的压缩后的数据为一个记号流 0122 ,这样就有了一个记号和字符串的映射表,即字典
如下:
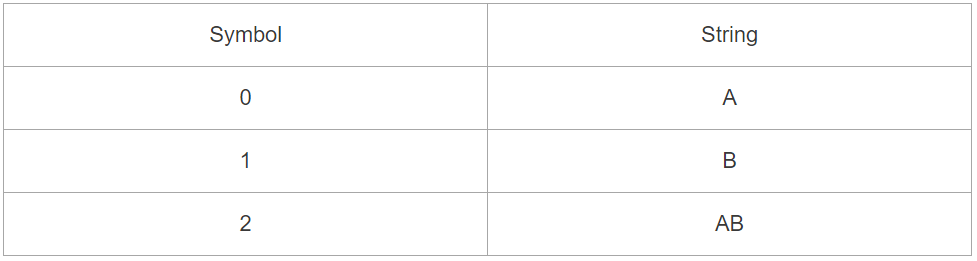
压缩后的编码 0122 ,根据字典就可以解码为原字符了
但是在真正的 LZW 中,A 和 B 是用 ASCII 码表示的
LZW 初始会有一个默认的字典,包含了所有 256 个 8 bit 字符,单个字符的记号就是它自身,用数字表示就是 ASCII 值
在编码过程中加入的新的记号的映射,从256开始,称为扩展表
AB 不也用 2 表示?ABABAB 编码过程:
0122 的时候,解码器首先通过 01 直接解析出最前面 A 和 B,并且生成表项 2->AB,这样才能将后面出现的 2 都解析为 AB算法
- 初始状态,字典里只有所有的默认项,例如 0->a,1->b,2->c。此时P 和 C都是空的
- 读入新的字符 C,与 P 合并形成字符串 P+C
- 在字典里查找 P+C,
- 如果 P+C 在字典里,P=P+C
- 如果 P+C 不在字典里,将 P的记号输出;在字典中为 P+C建立一个记号映射;更新 P=C
- 返回步骤 2 重复,直到读完所有字符
P 是当前维护的,可以被编码为记号的子串。注意 P 是可以被编码为记号,但还并未输出。
新的字符 C 不断被读入并添加到 P 的尾部,只要 P+C 仍然能在字典里找到,就不断增长更新 P=P+C,这样就能将一个尽可能长的字串 P 编码为一个记号,这就是压缩的实现
压缩 ababcababac
初始状态字典:
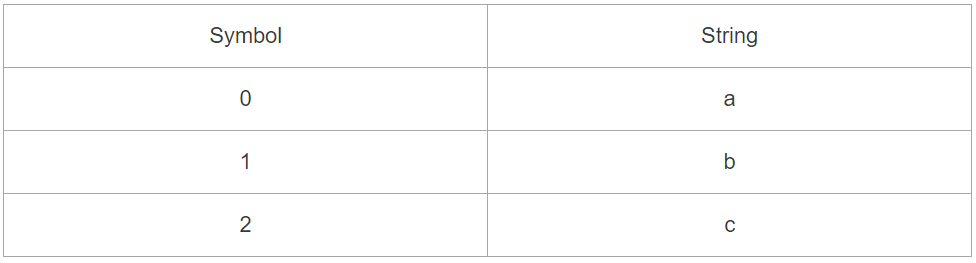
开始编码
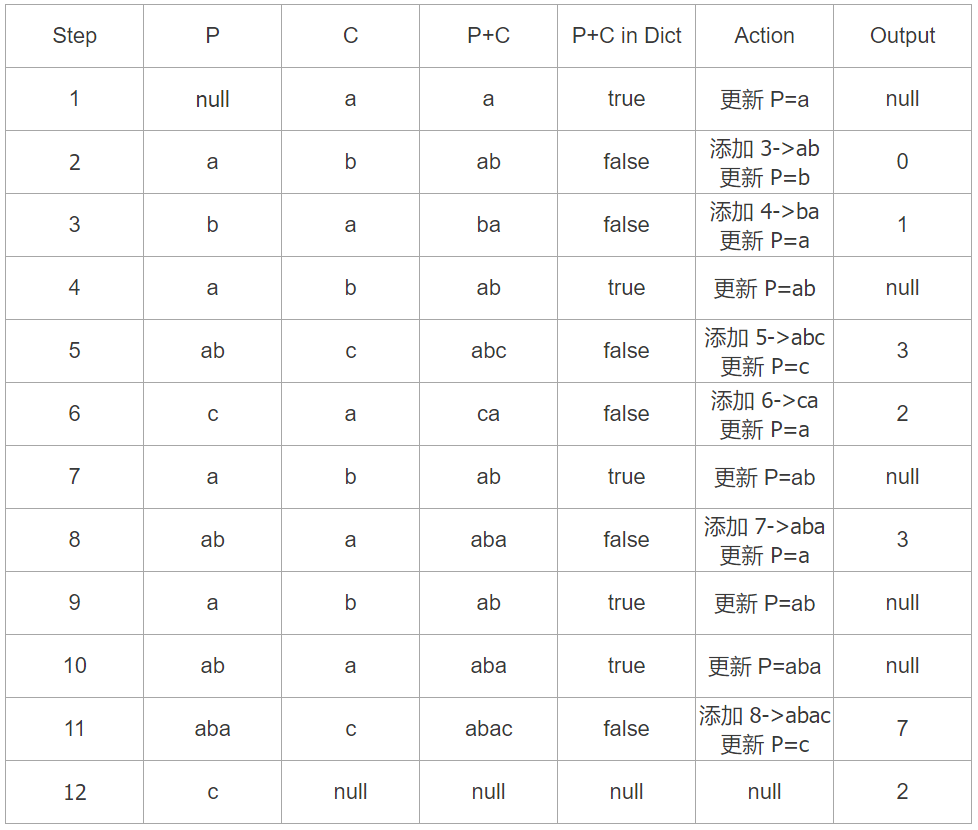
结果为 0132372
注意编码过程中的第 3-4 步,第 7-8步 以及8-10步,子串 P 发生了增长,直到新的 P+C 无法在字典中找到,则将当前的 P 输出,P 则更新为单字符 C,重新开始增长
下面的代码是用 0->A,1->B,2->C,作为基本编码表的
s = input("Please input a string: ")
def init(s):
dict = {}
tmp = []
for i in s:
if i not in tmp:
tmp.append(i)
# print(tmp)
j = 0
for i in range(len(tmp)):
t = str(j)
dict[tmp[i]] = t
j = j + 1
# print(dict)
return dict
def encoding(s):
r = []
table = init(s)
P = ''
for i in range(len(s)):
C = s[i]
t = P+C
if t in table.keys():
P = t
continue
if t not in table.keys():
# t=AB
table[t] = str(len(table))
r.append(table[P])
P = C
if i == len(s)-1:
r.append(table[s[i]])
print("After compress: " + ''.join(r))
print("coding table is: ")
print(table)
encoding(s)标签:def 返回 img yun end 自身 代码 lease 基本
原文地址:https://www.cnblogs.com/peri0d/p/11770450.html