标签:llb atomic return count http duration generic ipaddress imp
聚合函数
关键字:aggregate
from django.db.models import Max,Min,Sum,Count,Avg
关键字:annotate
统计每一本书的作者个数
models.Book.objects.annotate(author_num = Count(‘author‘)).values(‘title‘)统计每一个出版社卖的最便宜的书的价格
models.Book.objects.annotate(price_min=Min(‘book__price‘)).values(‘price_min‘)统计不止一个作者的图书
models.Book.objects.annotate(author_num = Count(‘author‘)).values(‘author_num‘).filter(author__num__gt=1) 查询各个作者出的书的总价格
models.Author.objects.annotate(sum_price = Sum(‘book__price‘)).values(‘sum_price‘)查询卖出数大于库存数
models.Book.objects.filter(maichu__gt=F(‘kucun‘))将所有的书的价格全部提高100元
models.Book.objects.update(price=F(‘price‘)+ 100)将所有书的名字后面都加上爆款
from django.db.models.functions import Concat
from django.db.models import Value
ret3=models.Product.objects.update(name=Concat(F(‘name‘),Value(‘爆款‘)))查询书籍名称是python入门或者价格是54的书
models.Book.objects.filter(Q(title=‘python入门‘)|Q(price=54))查询书籍名称不是python入门或者价格是54的书
models.Book.objects.filter(~Q(title=‘python入门‘)|Q(price=54))查询条件由用户输入决定
q = Q()
q.connector = ‘or‘ #将默认and,改为or
q.children.append((‘title‘,‘python‘))
q.children.append((‘kucun‘,666))
res = models.Book.objects.filter(q)字符串左边跟变量名书写的格式一模一样
‘AutoField‘: ‘integer AUTO_INCREMENT‘,
‘BigAutoField‘: ‘bigint AUTO_INCREMENT‘,
‘BinaryField‘: ‘longblob‘,
‘BooleanField‘: ‘bool‘,
‘CharField‘: ‘varchar(%(max_length)s)‘,
‘CommaSeparatedIntegerField‘: ‘varchar(%(max_length)s)‘,
‘DateField‘: ‘date‘,
‘DateTimeField‘: ‘datetime‘,
‘DecimalField‘: ‘numeric(%(max_digits)s, %(decimal_places)s)‘,
‘DurationField‘: ‘bigint‘,
‘FileField‘: ‘varchar(%(max_length)s)‘,
‘FilePathField‘: ‘varchar(%(max_length)s)‘,
‘FloatField‘: ‘double precision‘,
‘IntegerField‘: ‘integer‘,
‘BigIntegerField‘: ‘bigint‘,
‘IPAddressField‘: ‘char(15)‘,
‘GenericIPAddressField‘: ‘char(39)‘,
‘NullBooleanField‘: ‘bool‘,
‘OneToOneField‘: ‘integer‘,
‘PositiveIntegerField‘: ‘integer UNSIGNED‘,
‘PositiveSmallIntegerField‘: ‘smallint UNSIGNED‘,
‘SlugField‘: ‘varchar(%(max_length)s)‘,
‘SmallIntegerField‘: ‘smallint‘,
‘TextField‘: ‘longtext‘,
‘TimeField‘: ‘time‘,
‘UUIDField‘: ‘char(32)‘,class MyCharField(models.Field):
def __init__(self,max_length,*args,**kwargs):
self.max_length = max_length
super().__init__(max_length=max_length,*args,**kwargs)
def db_type(self, connection):
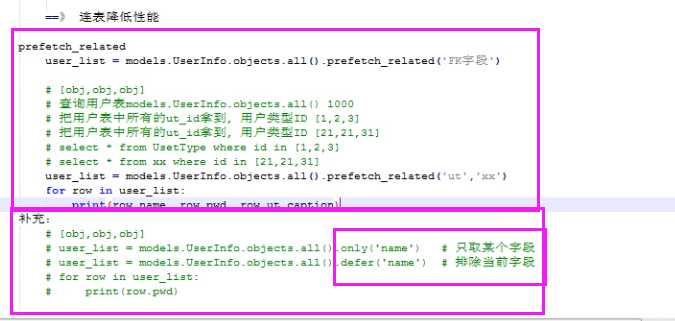
return ‘char(%s)‘%self.max_lengthonly会将口号内的字段对应的值 直接封装到返回给你的对象中 点该字段 不需要再走数据库
一旦你点了不在括号内的字段 就会频繁的去走数据库查询
defer和only互为反关系,defer会将括号内的字段排除之外,将其他字段对应的值 直接封装到返回给你的对象中,点该其他字段 不需要再走数据库,一旦你点了在括号内的字段 就会频繁的去走数据库查询
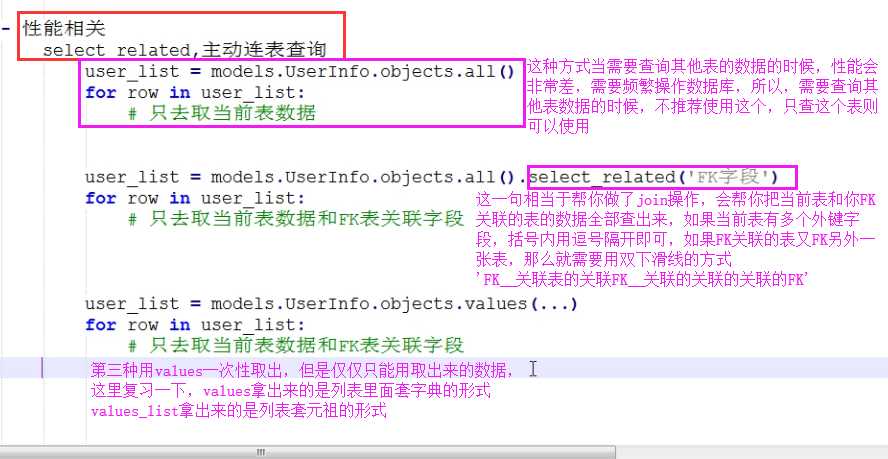
select_related会自动帮你做连表操作,然后连表之后的数据全部查询出来封装给对象
select_related括号内只能放外键字段,并且多对多字段除外
如果括号内所关联的外键字段还有外键字段,还可以继续连表
select_related(外键字段__外键字段__外键字段...)prefetch_relate看似是连表操作,其实是子查询,内部不做连表,小号的资源就在查询次数上,但是给用户感觉不出来
ACID:原子性、一致性、隔离性、持久性
from django.db import transaction
with transaction.atomic():
#在该代码块中所写的orm语句 同属于一个事务
#缩进出来之后自动结束
Django框架——模型(models)层之ORM查询(二)
标签:llb atomic return count http duration generic ipaddress imp
原文地址:https://www.cnblogs.com/lulingjie/p/11774276.html