标签:自己 存在 数据 这一 ica 工程师 pes smp localhost
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。本文对其进行部署配置,并安装配置kafkatool对kafka进行监控、查询
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,有如下功能:
1.管理多个kafka集群
2.便捷的检查kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
3.选择你要运行的副本
4.基于当前分区状况进行
5.可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
6.删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
7.Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
8.为已存在的topic增加分区
9.为已存在的topic更新配置
10.在多个topic上批量重分区
11.在多个topic上批量重分区(可选partition broker位置)

1.安装jdk8 jdk-1.8.0_60 2,kafka集群 服务器: 10.0.0.50:12181 10.0.0.60:12181 10.0.0.70:12181 软件: kafka_2.8.0-0.8.1.1 zookeeper-3.3.6 3.系统 Linux kafka50 2.6.32-642.el6.x86_64 #1 SMP Tue May 10 17:27:01 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Github地址:https://github.com/yahoo/kafka-manager
unzip kafka-manager-1.3.3.7.zip -d /data/ cd /data/kafka-manager-1.3.3.7
[root@kafka50 conf]# pwd /data/kafka-manager-1.3.3.7/conf [root@kafka50 conf]# ls application.conf consumer.properties logback.xml logger.xml nohup.out routes 编辑配置文件application.conf #kafka-manager.zkhosts="localhost:2181" ##注释这一行,下面添加一行 kafka-manager.zkhosts="10.0.0.50:12181,10.0.0.60:12181,10.0.0.70:12181"
bin/kafka-manager kafka-manager 默认的端口是9000,可通过 -Dhttp.port,指定端口; -Dconfig.file=conf/application.conf指定配置文件: nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8080 &
启动过程:
 View Code
View Code启动完毕后可以查看端口是否启动,由于启动过程需要一段时间,端口起来的时间可能会延后。
使用ip地址:端口访问
点击【Cluster】>【Add Cluster】打开如下添加集群的配置界面:
输入集群的名字(如Kafka-Cluster-1)和 Zookeeper 服务器地址(如localhost:2181),选择最接近的Kafka版本(如0.8.1.1)
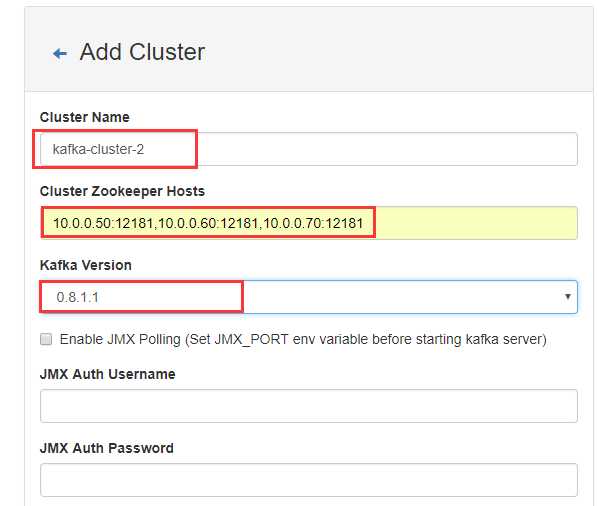
注意:如果没有在 Kafka 中配置过 JMX_PORT,千万不要选择第一个复选框。 Enable JMX Polling 如果选择了该复选框,Kafka-manager 可能会无法启动。
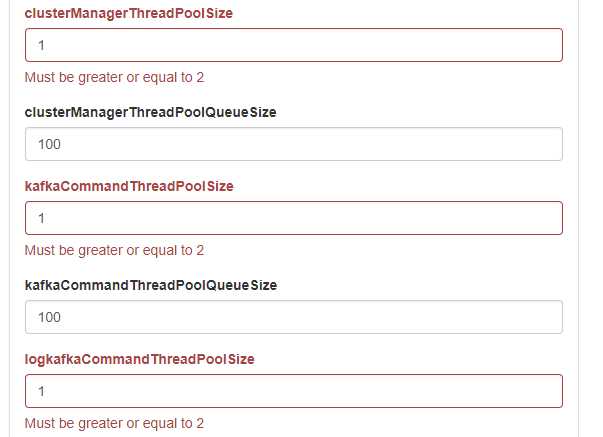
其他broker的配置可以根据自己需要进行配置,默认情况下,点击【保存】时,会提示几个默认值为1的配置错误,需要配置为>=2的值。提示如下。
新建完成后,运行界面如下:
TOPIC list
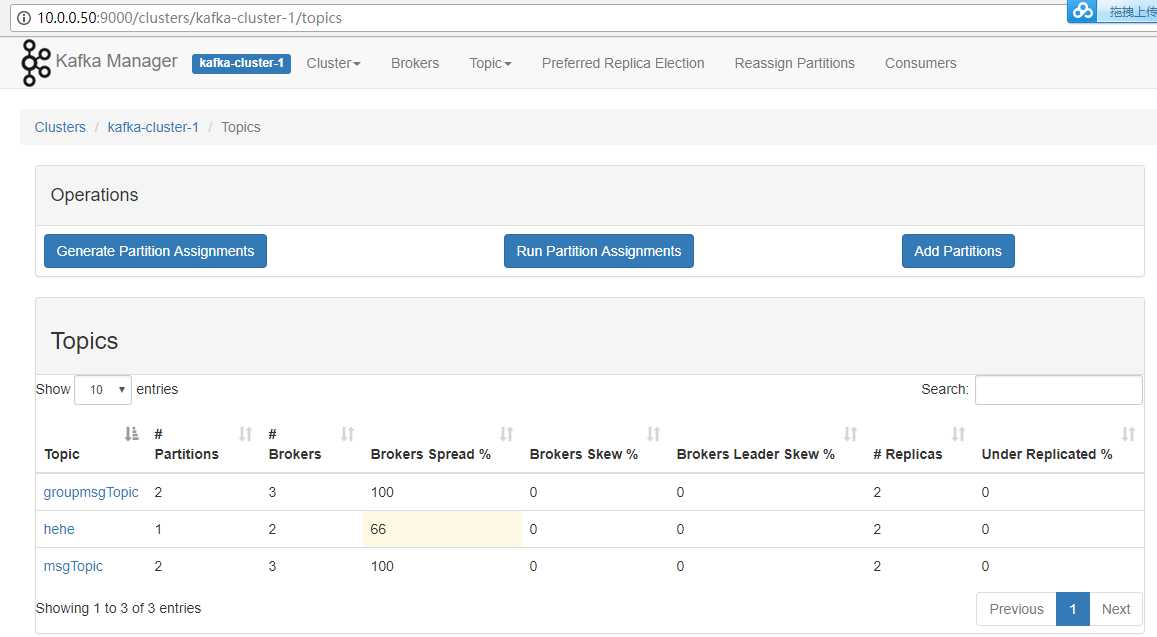
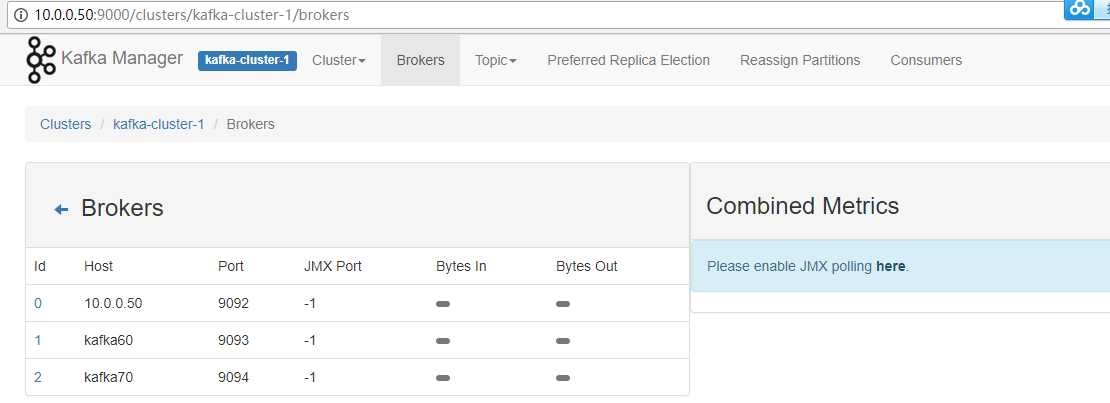
点击【Topic】>【Create】可以方便的创建并配置主题。如下显示。
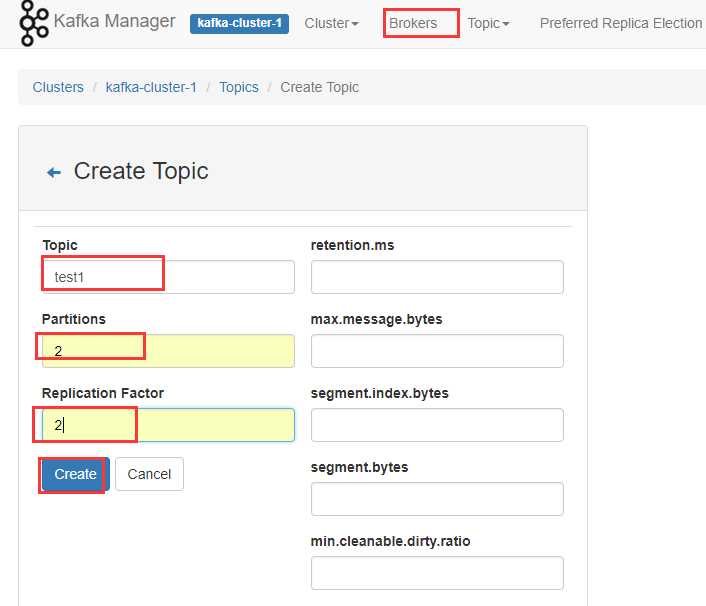
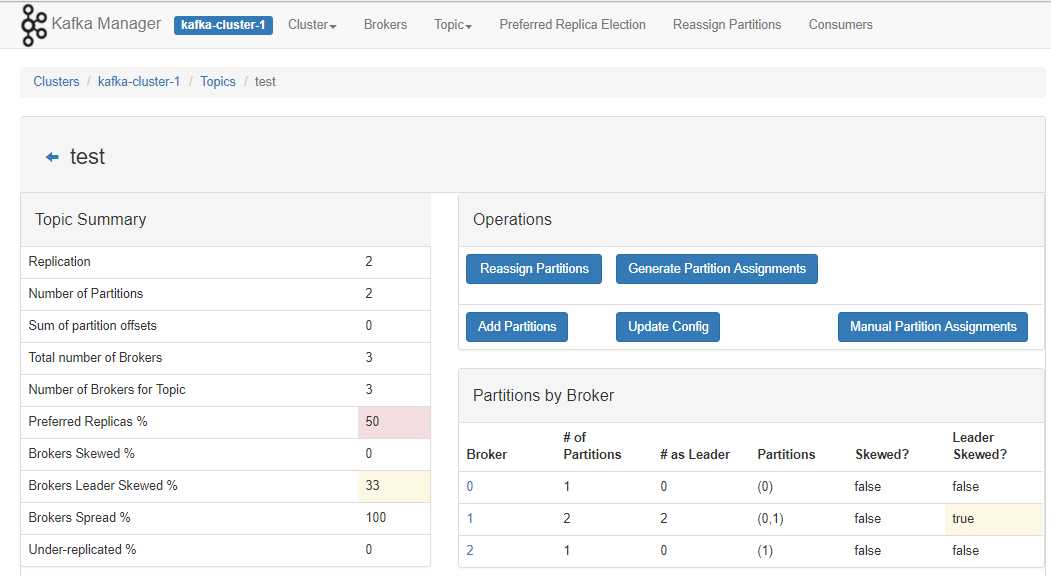
接下来我们根据一张图讲解
在上图一个Kafka集群中,有两个服务器,每个服务器上都有2个分区。P0,P3可能属于同一个主题,也可能是两个不同的主题。 如果设置的Partitons和Replication Factor都是2,这种情况下该主题的分步就和上图中Kafka集群显示的相同,此时P0,P3是同一个主题的两个分区。P1,P2也是同一个主题的两个分区,Server1和Server2其中一个会作为Leader进行读写操作,另一个通过复制进行同步。 如果设置的Partitons和Replication Factor都是1,这时只会根据算法在某个Server上创建一个分区,可以是P0~4中的某一个(分区都是新建的,不是先存在4个然后从中取1个)。
这里我们都设置为2,点击【Create】然后进入创建的这个主题,显示如下。
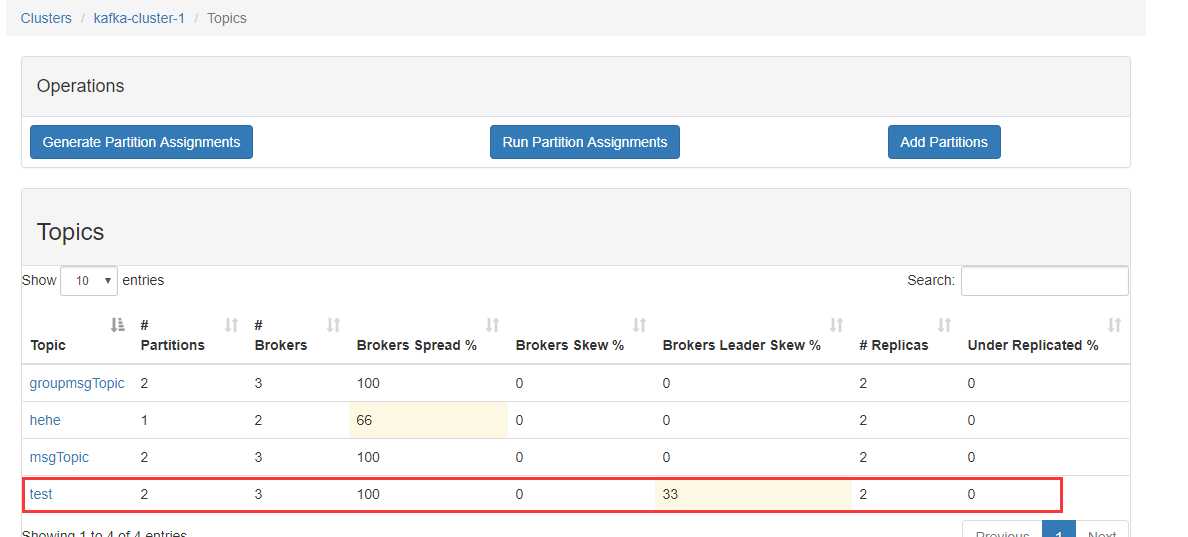
点击【topic】下面的主题名称,即可查看主题
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
下载kafkatool对kafka上的数据进行监控、查看
kafkatool下载地址:http://www.kafkatool.com/download.html
下载适合自己系统的版本即可
安装完成后运行kafkatool
无需注册,直接试用
选择File下的 Add New Connection
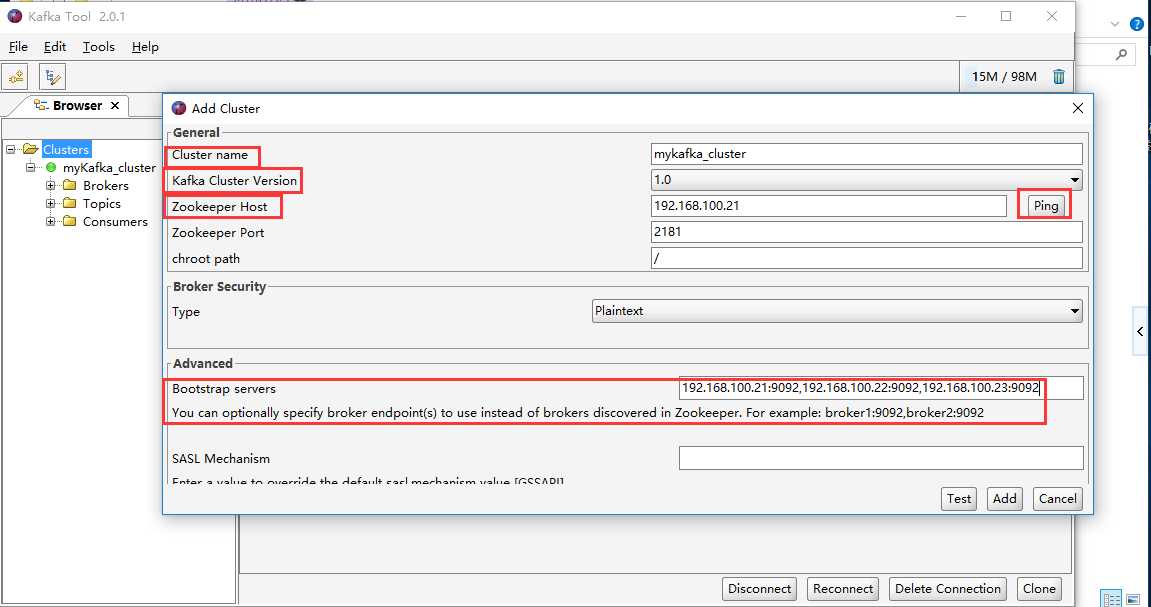
设置完了,点击Test测试是否能连接,连接通了,然后点击Add,添加完成设置。出现如下界面
配置以字符串的形式显示kafka消息体
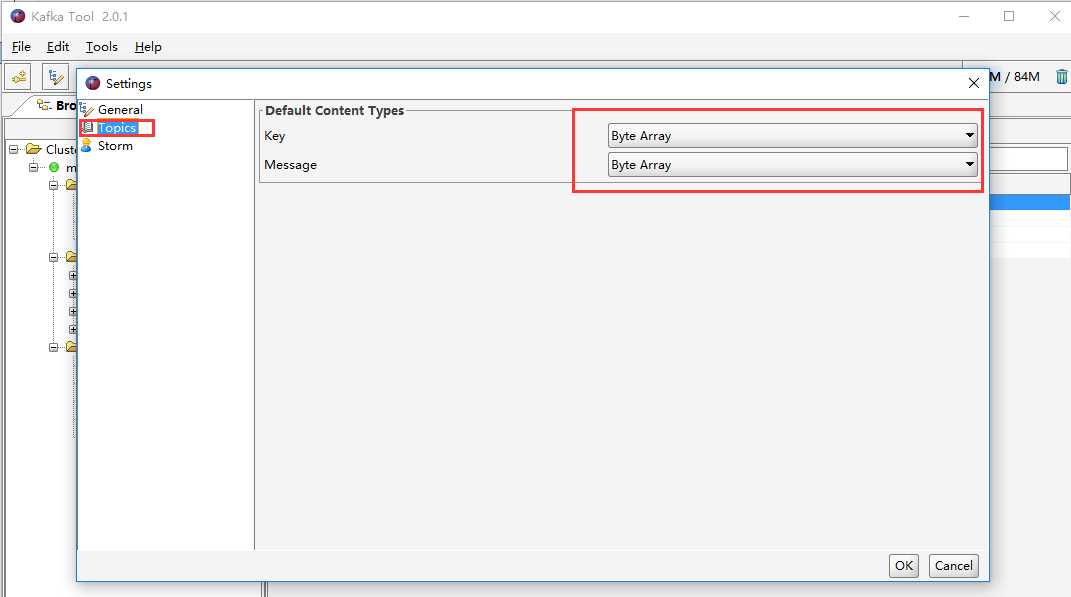
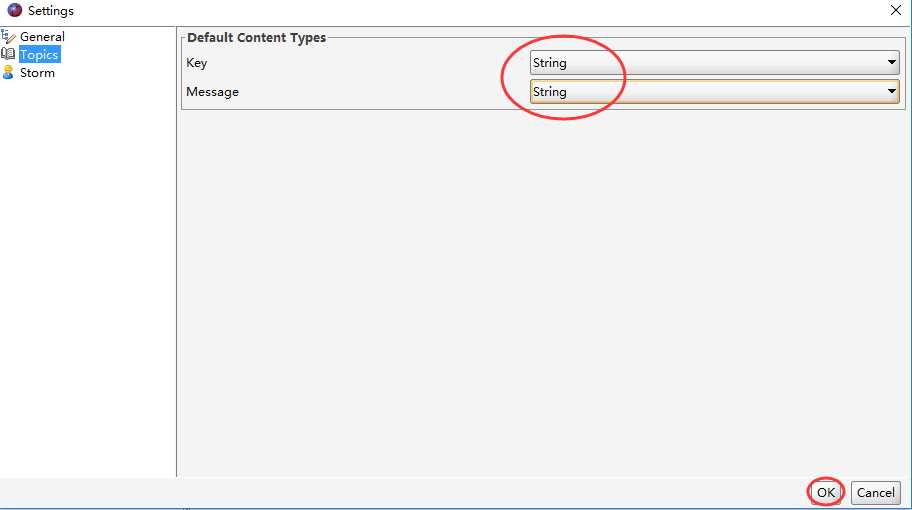
或者通过如下界面配置
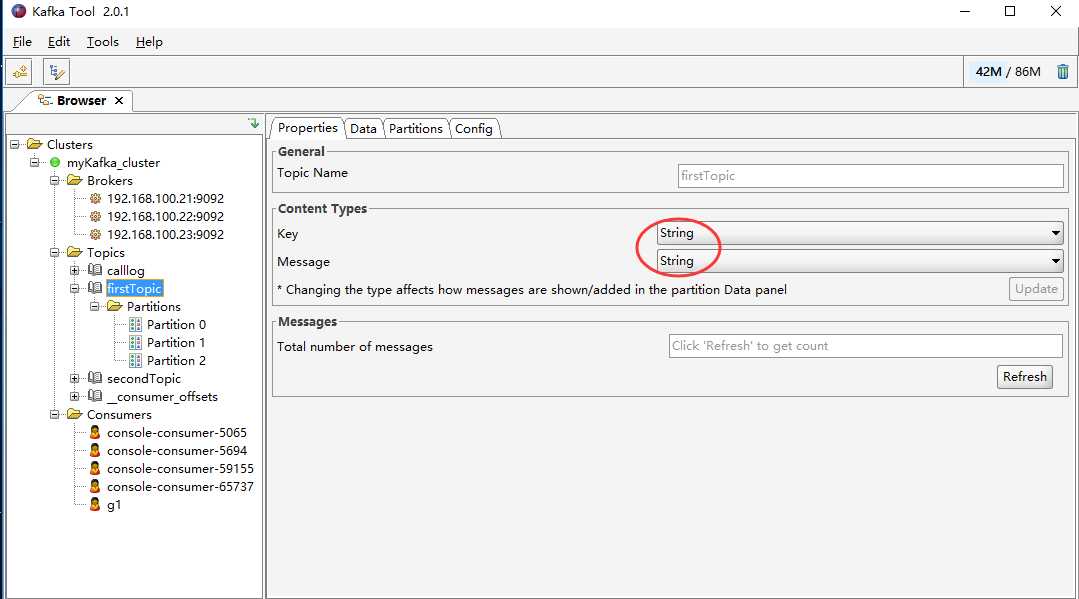
再次查看kafka的数据:
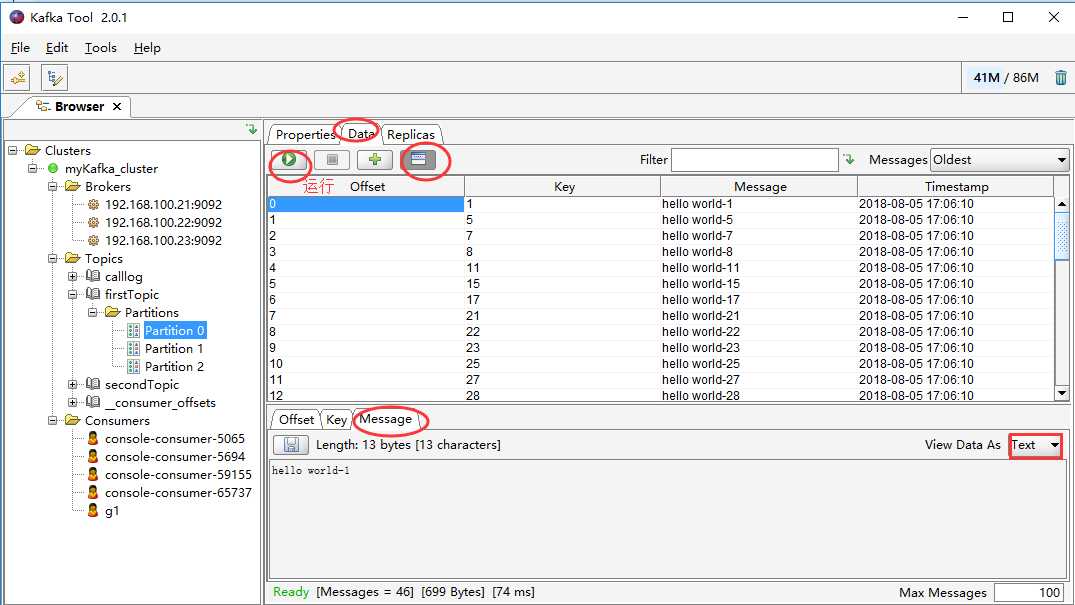
具体显示格式根据发布者上传到kafka上的数据格式为准,包括json格式、AVRQ格式等。格式不同显示信息不同。
标签:自己 存在 数据 这一 ica 工程师 pes smp localhost
原文地址:https://www.cnblogs.com/alliswell2king/p/11777233.html
