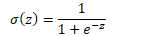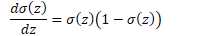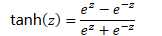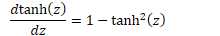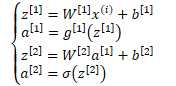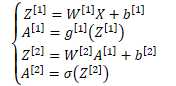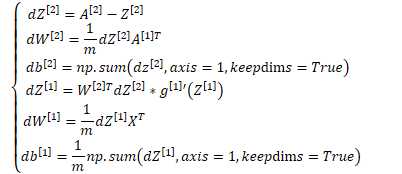标签:com -- info pad 维度 ble round idt log
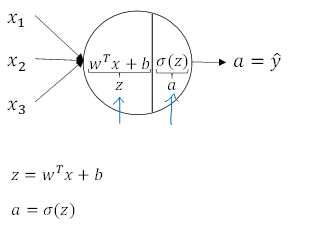
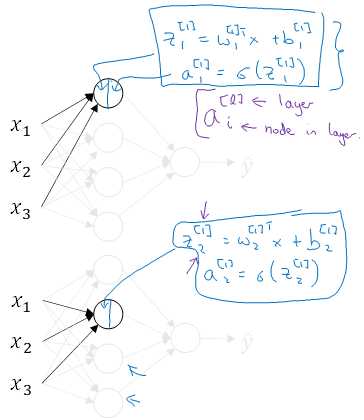
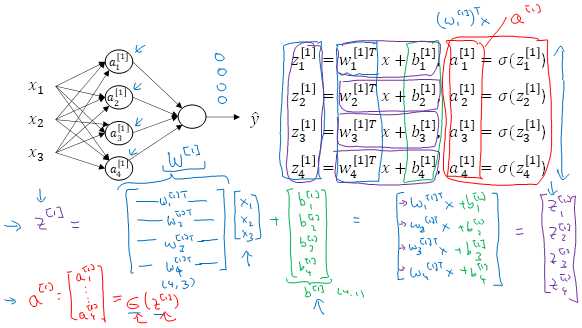
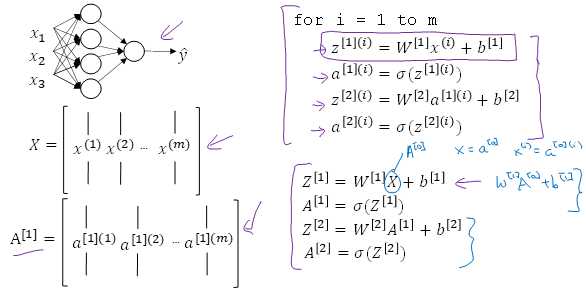
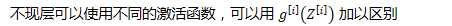
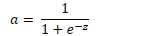
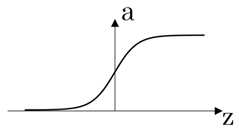
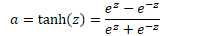
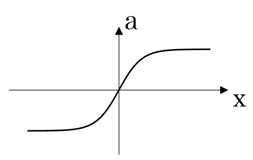
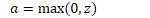
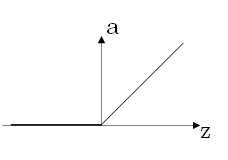
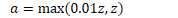
原函数 | 导数 |
|
|
|
|
正向求解过程 | 反向求导数过程 | ||||||||
|
|
当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。
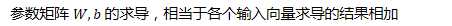
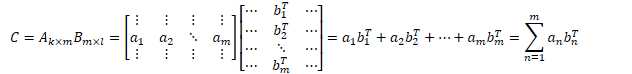
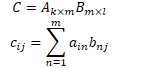
np.random.randn(2,2) * 0.01 |
? ?
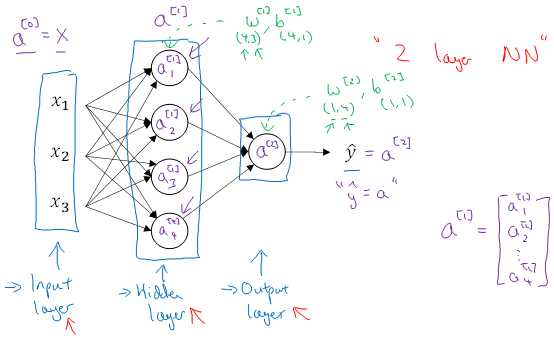
吴恩达deeplearning.ai -- week3 浅层神经网络
标签:com -- info pad 维度 ble round idt log
原文地址:https://www.cnblogs.com/lijunjie9502/p/11778324.html