标签:词典 修饰词 京东 exp 语言 处理 info 准确率 针对
---恢复内容开始---
我的工程实践项目为《基于情感词典的文本情感分析》,情感分析是指通过机器学习或者自然语言处理技术,从文本中分析出人们对实体或属性所表达的观点、情感、评价、态度和情绪,情感分析也被称为情感挖掘、意见挖掘、观点抽取等。文本情感分析的主要任务是判断文本的情感倾向性,即对作者表达的情感是积极的还是消极的,正面的还是负面的,褒义的还是贬义的判断,因此也被情感分类。基于情感词典的文本情感分类,是对人的记忆和判断思维的最简单的模拟。其原理通过考察并分析文本中所有的具有情感色彩的词语,并对这些词语以及修饰词的情感强度进行量化加权来计算整个文本情感倾向的方法。其具体的实现方法为:首先对输入文本进行分词和去除停用词,然后将每个处理过的分词与构建的情感词典进行匹配,最后根据匹配结果得到文本的情感极性。主要的用例有:
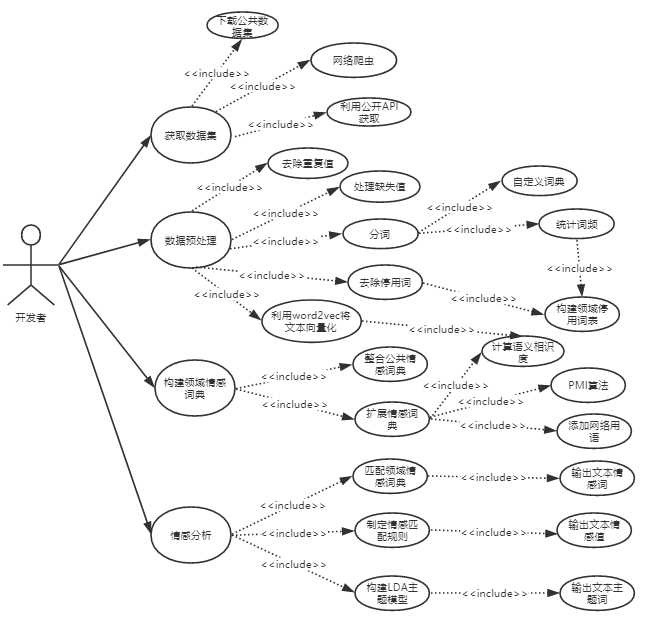
High level use case:
Expanded use case:
标签:词典 修饰词 京东 exp 语言 处理 info 准确率 针对
原文地址:https://www.cnblogs.com/L-xuan/p/11780051.html