标签:col 必须 update 销售额 stat base 第一个 难点 命中
一 什么是事务?有什么用?
事务的特性ACID
事务提供了一种机制,可用来将一系列数据库更改归入一个逻辑操作。更改数据库后,所做的更改可以作为一个单元进行提交或取消。事务可确保遵循原子性、一致性、隔离性和持续性(ACID)这几种属性,以使数据能够正确地提交到数据库中。
1)原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作 要么都发生,要么都不发生。
2)一致性(Consistency)一个事务中,事务前后数据的完整性必须保持一致。
3)隔离性(Isolation)多个事务,事务的隔离性是指多个用户并发访问数据库时, 一个用户的 事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离。
4)持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变 就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
二 事务的并发会产生的问题有哪些
1.脏读
一个事务正在对数据进行更新操作,但是更新还未提交,另一个事务这时也来操作这组数据,并且读取了前一个事务还未提交的数据,而前一个事务如果操作失败进行了回滚,后一个事务读取的就是错误的数据,这样就造成了脏读
2.不可重复读
一个事务多次读取同一个数据,在该事务还未结束时,另一个事务也对该数据进行 了操作,而且在第一个事务两次读取之间,第二个事务对数据进行了更新,那么第一个 事务前后两个读取到的数据是不同的,这样就造成了不可重复读
3.幻读
第一个数据正在查询某一条数据,这时,另一个事务又插入了一条符合条件的数据,第一个事务在第二次查询符合同一条件的数据时,发现多了一条前一次查询时没有的数据,仿佛幻觉一样,这就是幻读
三 不可重复读和幻读的区别
不可重复读是指在同一查询事务中多次进行,由于其他提交事务所做的修改和删除,每次返回不同的结果集,此时发生不可重复读
幻读是指在同一查询事务中多次进行,由于其他提交的事务所做的插入操作,每次返回不同的结果集,此时发生幻读表面上看,区别就在于不可重复读能看见其他事务提交的修改和删除,而幻读能看见其他事务提交的插入
四 spring 事务隔离级别
1.default:(默认)
默认隔离级别,使用数据库默认的事务隔离级别
2.read_uncommitted:(读未提交)
这是事务最低的隔离级别,他允许另外一个事务可以看到这个事务未提交的数据,这种隔离级别会产生脏读,不可重复读和幻读
3.read_committed(读已提交)
保证一个事务修改的数据提交后才能被另外一个事务读取,另外一个事务不能读取该事务未提交的数据.这种事务隔离级别可以避免脏读,但是可能会出现不可重复读和幻读
4.repeatable_read(可重复读)
这种事务级别可以防止脏读,不可重复读.但是可能出现幻读.他除了保证一个事务不能读取另一个事务未提交的数据外,还保证了不可重复读
5.Serializable 串行化
这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。防止了脏读、不可重复读、幻读
总结:
脏读 不可重复读 幻读
读未提交 会 会 会
读已提交 不会 会 会
可重复读 不会 不会 会
串行化 不会 不会 不会
五 spring事务的传播行为
1.requierd
如果有事务那么加入事务,没有的话新建一个
2.not_supported
不开启事务
3.requires_new
不管是否存在事务,都创建一个新的事务,原来的挂起,新的执行完,继续执行老事务
4.mandatory
必须在一个已有的事务中执行,否则抛出异常
5.never
必须在一个没有的事务中执行,否则抛出异常
6.supports
如果其他bean调用这个方法,在其他bean中声明事务,那就用事务.如果其他bean没有声明事务那就不用事务
7.PROPAGATION_NESTED
如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则按REQUIRED属性执行。
六 Spring声明式事务的回滚机制
在Spring 的事务框架中推荐的事务回滚方法是,在当前执行的事务上下文中抛出一个异常。如果异常未被处理,当抛出异常调用堆栈的时候,Spring 的事务框架代码将捕获任何未处理的异常,然后并决定是否将此事务标记为回滚。
在默认配置中,Spring 的事务框架代码只会将出现runtime, unchecked 异常的事务标记为回滚;也就是说事务中抛出的异常时RuntimeException或者是其子类,这样事务才会回滚(默认情况下Error也会导致事务回滚)。在默认配置的情况下,所有的 checked 异常都不会引起事务回滚。如果有需要,可以通过rollback-for 和no-rollback-for进行指定。
七 分布式环境下如何处理事务
分布式事务处理是很难保证acid的。一般做法是牺牲一致性,满足可用性和分区容错。采用的方式可以是二阶段提交,由于二阶段提交存在着诸如同步阻塞、单点问题、数据不一致、宕机等缺陷,所以还可以采用TCC(补偿事务)的方式实现,TCC核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段,本质也是2阶段提交,缺点也比较明显的,在确认和补偿时都有可能失败,一些业务流程可能用TCC不太好定义及处理。分布式事务还可以基于 mq(消息队列)/rpc(远程方法调用)实现最终一致性。还有Mycat可以通过用户会话Session中设置autocommit=false启动事务,通过设置ServerConnection中变量txInterrupted=true来控制是否事务异常需要回滚。在Mycat中的事务是一种二阶段提交事务方式,但是从实际应用场景出发这种出现故障的概率还是比较小的,因此这种实现方式可以满足很多应用需求,但如果出现问题,会很麻烦。但在分库分表,立即可见的应用上是不能满足业务需求的,所以分布式事务需要根据具体业务的需要权衡取舍的。
分享文章:
根据微服务架构的鼻祖 Martin Fowler 的忠告,微服务架构中应当尽量避免分布式事务。然而,在某些领域,分布式事务如同宿命中的对手无法避免。
根据微服务架构的鼻祖 Martin Fowler 的忠告,微服务架构中应当尽量避免分布式事务。然而,在某些领域,分布式事务如同宿命中的对手无法避免。
在工程领域,分布式事务的讨论主要聚焦于强一致性和最终一致性的解决方案。
典型方案包括:
一致性理论
分布式事务的目的是保障分库数据一致性,而跨库事务会遇到各种不可控制的问题,如个别节点永久性宕机,像单机事务一样的 ACID 是无法奢望的。
另外,业界著名的 CAP 理论也告诉我们,对分布式系统,需要将数据一致性和系统可用性、分区容忍性放在天平上一起考虑。
两阶段提交协议(简称2PC)是实现分布式事务较为经典的方案,但 2PC 的可扩展性很差,在分布式架构下应用代价较大,eBay 架构师 Dan Pritchett 提出了 BASE 理论,用于解决大规模分布式系统下的数据一致性问题。
BASE 理论告诉我们:可以通过放弃系统在每个时刻的强一致性来换取系统的可扩展性。
01.CAP 理论
在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)3 个要素最多只能同时满足两个,不可兼得。其中,分区容忍性又是不可或缺的。
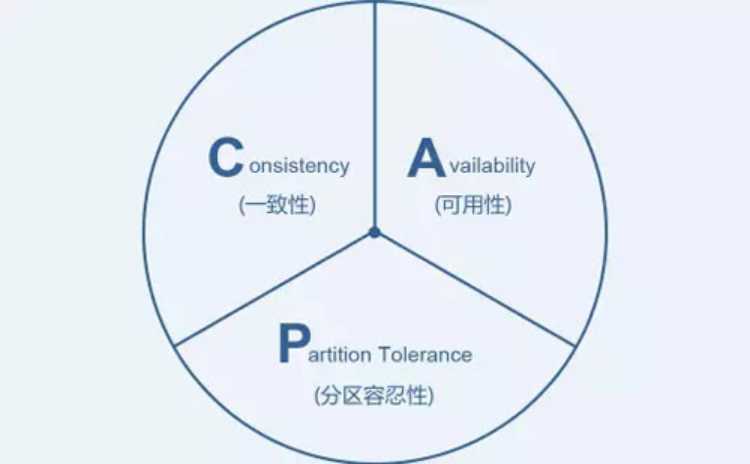
举例:Cassandra、Dynamo 等,默认优先选择 AP,弱化 C;HBase、MongoDB 等,默认优先选择 CP,弱化 A。
02.BASE 理论
核心思想:
一致性模型
数据的一致性模型可以分成以下三类:
分布式系统数据的强一致性、弱一致性和最终一致性可以通过 Quorum NRW 算法分析。
分布式事务解决方案
01.2PC 方案——强一致性
2PC 的核心原理是通过提交分阶段和记日志的方式,记录下事务提交所处的阶段状态,在组件宕机重启后,可通过日志恢复事务提交的阶段状态,并在这个状态节点重试。
如 Coordinator 重启后,通过日志可以确定提交处于 Prepare 还是 Prepare All 状态。若是前者,说明有节点可能没有 Prepare 成功,或所有节点 Prepare 成功但还没有下发 Commit,状态恢复后给所有节点下发 RollBack。
若是 Prepare All 状态,需要给所有节点下发 Commit,数据库节点需要保证 Commit 幂等。
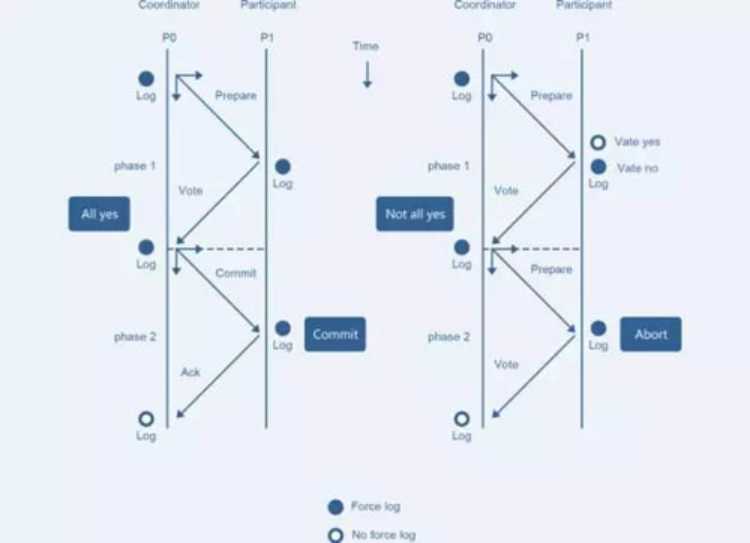
2PC 方案的三个问题:
升级的 3PC 方案旨在解决这些问题,主要有两个改进:
但三阶段提交也存在一些缺陷,要彻底从协议层面避免数据不一致,可以采用 Paxos 或者 Raft 算法。
02.eBay 事件队列方案——最终一致性
eBay 的架构师 Dan Pritchett,曾在一篇解释 BASE 原理的论文《Base:An Acid Alternative》中提到一个 eBay 分布式系统一致性问题的解决方案。
它的核心思想是将需要分布式处理的任务通过消息或者日志的方式来异步执行,消息或日志可以存到本地文件、数据库或消息队列,再通过业务规则进行失败重试,它要求各服务的接口是幂等的。
描述的场景为,有用户表 user 和交易表 transaction,用户表存储用户信息、总销售额和总购买额。交易表存储每一笔交易的流水号、买家信息、卖家信息和交易金额。如果产生了一笔交易,需要在交易表增加记录,同时还要修改用户表的金额。
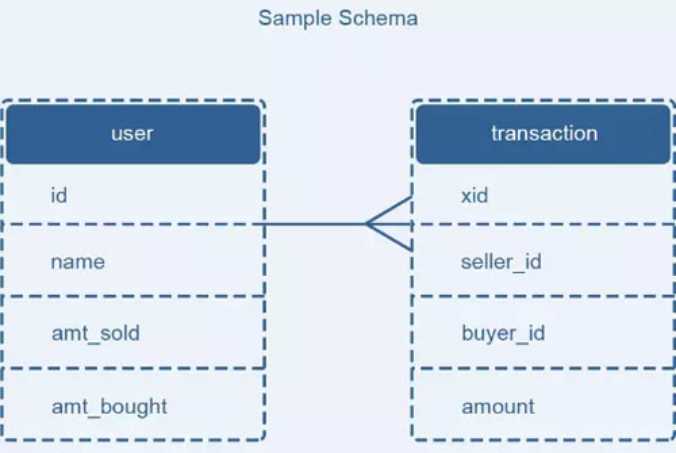
论文中提出的解决方法是将更新交易表记录和用户表更新消息放在一个本地事务来完成,为了避免重复消费用户表更新消息带来的问题,增加一个操作记录表 updates_applied 来记录已经完成的交易相关的信息。
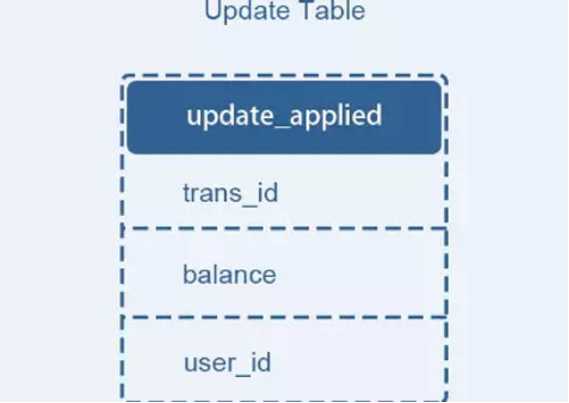
这个方案的核心在于第二阶段的重试和幂等执行。失败后重试,这是一种补偿机制,它是能保证系统最终一致的关键流程。
03.TCC (Try-Confirm-Cancel)补偿模式——最终一致性
某业务模型如图,由服务 A、服务 B、服务 C、服务 D 共同组成的一个微服务架构系统。服务 A 需要依次调用服务 B、服务 C 和服务 D 共同完成一个操作。
当服务 A 调用服务 D 失败时,若要保证整个系统数据的一致性,就要对服务 B 和服务 C 的 invoke 操作进行回滚,执行反向的 revert 操作。回滚成功后,整个微服务系统是数据一致的。
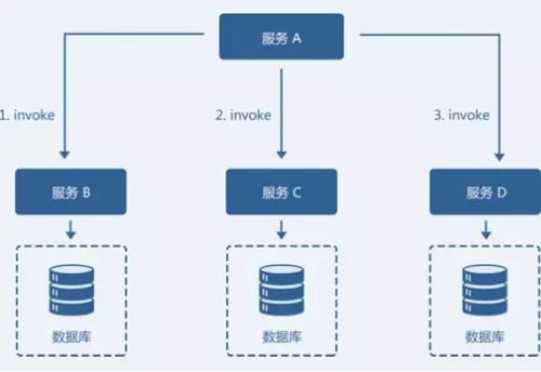
实现的三个关键要素:
实现的两个难点:
04.缓存数据最终一致性
在我们的业务系统中,缓存(Redis 或者 Memcached)通常被用在数据库前面,作为数据读取的缓冲,使得 I/O 操作不至于直接落在数据库上。
以商品详情页为例,假如卖家修改了商品信息,并写回到数据库,但是这时候用户从商品详情页看到的信息还是从缓存中拿到的过时数据,这就出现了缓存系统和数据库系统中的数据不一致的现象。
要解决该场景下缓存和数据库数据不一致的问题,我们有以下两种解决方案:
选择建议
在面临数据一致性问题的时候,首先要从业务需求的角度出发,确定我们对于三种一致性模型的接受程度,再通过具体场景来决定解决方案。
从应用角度看,分布式事务的现实场景常常无法规避,在有能力给出其他解决方案前,2PC 也是一个不错的选择。
对购物转账等电商和金融业务,中间件层的 2PC 最大问题在于业务不可见,一旦出现不可抗力或意想不到的一致性破坏。
如数据节点永久性宕机,业务难以根据 2PC 的日志进行补偿。金融场景下,数据一致性是命根,业务需要对数据有百分之百的掌控力。
建议使用 TCC 这类分布式事务模型,或基于消息队列的柔性事务框架,这两种方案都在业务层实现,业务开发者具有足够掌控力,可以结合 SOA 框架来架构,包括 Dubbo、Spring Cloud 等。
标签:col 必须 update 销售额 stat base 第一个 难点 命中
原文地址:https://www.cnblogs.com/yh2two/p/11782465.html