标签:mit mic orm comm 概念 小结 lis user 覆盖
在 hive 中分区表是很常用的,分桶表可能没那么常用,本文主讲分区表。
分区表
在 hive 中,表是可以分区的,hive 表的每个区其实是对应 hdfs 上的一个文件夹;
可以通过多层文件夹的方式创建多层分区;
通过文件夹把数据分开
分桶表
分桶表中的每个桶对应 hdfs 上的一个文件;
通过文件把数据分开
在查询时可以通过 where 指定分区(分桶),提高查询效率
1. 创建分区表
partitoned by 指定分区,后面加 分区字段 和 分区字段类型,可以加多个字段,前面是父路径,后面是子路径
create table student_p(id int,name string,sexex string,age int,dept string) partitioned by(part string) row format delimited fields terminated by ‘,‘ stored as textfile;
分区表相当于给 表 加了一个字段,然后给这个字段赋予不同的 value,每个 value 对应一个分区,这个 value 对应 hdfs 上文件夹的名字
2. 写入数据
1, zhangsan, f, 30, a,
2, lisi, f, 39, b,
3, wangwu, m, 26, c,
写入两次,每次设置不同的分区
load data local inpath ‘/usr/lib/hive2.3.6/2.csv‘ into table student_p partition(part=321);
load data local inpath ‘/usr/lib/hive2.3.6/2.csv‘ into table student_p partition(part=456);
3. 写入数据后看看长啥样
hive> select * from student_p;
OK
1 zhangsan f 20 henan 321
2 lisi f 30 shanghai 321
3 wangwu m 40 beijing 321
1 zhangsan f 20 henan 456
2 lisi f 30 shanghai 456
3 wangwu m 40 beijing 456
Time taken: 0.287 seconds, Fetched: 6 row(s)
4. hdfs 上看看长啥样
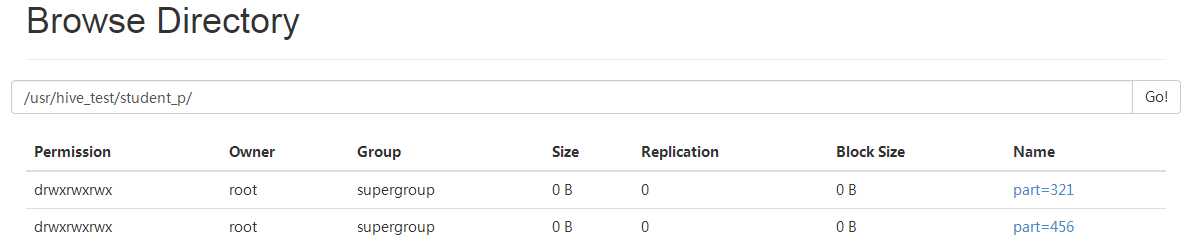
5. 查看某个分区
hive> select * from student_p where part=321;
6. 数据库里看看元数据信息
分区信息保存在 PARTITIONS 表中
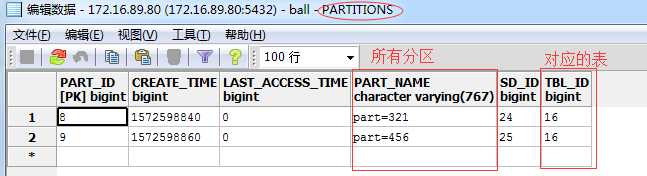
还有其他与 PARTITIONS 相关的表,自己可以看看
小结:每个分区对应一个文件夹,而且这个文件夹必须存储到元数据中;
也就是说,如果这个文件不在元数据中,那么即使他存在,也不是分区表中的一个分区,通过表查询不到
加载数据时会自动增加分区,也可以不加载数据,单独创建分区
hive> alter table student_p add partition(part=999);
hive> alter table student_p add partition(part=555) partition(part=666);

hive> alter table student_p drop partition(part=555); Dropped the partition part=555 OK Time taken: 0.675 seconds
hive> alter table student_p drop partition(part=666), partition(part=999); Dropped the partition part=666 Dropped the partition part=999 OK Time taken: 0.464 seconds
hive> show partitions student_p; OK part=321 part=456 Time taken: 0.28 seconds, Fetched: 2 row(s)
hive> desc formatted student_p; OK # col_name data_type comment id int name string sexex string age int dept string # Partition Information # col_name data_type comment part string # Detailed Table Information Database: hive1101 Owner: root CreateTime: Fri Nov 01 02:00:25 PDT 2019 LastAccessTime: UNKNOWN Retention: 0 Location: hdfs://hadoop10:9000/usr/hive_test/student_p Table Type: MANAGED_TABLE
之前我们讲到如果一个文件夹在表目录下,但是不在元数据中,那么通过表是查不到这个数据的。
那如何把这种数据通过表读出来?必须把他们关联起来,有三种方式
1. 直接上传数据到 hdfs
hive> dfs -mkdir -p /usr/hive_test/student_p/part=888; hive> dfs -put /usr/lib/hive2.3.6/2.csv /usr/hive_test/student_p/part=888;
在 hdfs 上直接建了一个目录,并且这个目录在 表目录下,然后给这个目录上传一个文件
2. 查询该分区数据,无果
3. 修复表
hive> msck repair table student_p; OK Partitions not in metastore: student_p:part=888 Repair: Added partition to metastore student_p:part=888 Time taken: 0.502 seconds, Fetched: 2 row(s)
就是把分区添加到元数据
4. 查询可查到数据
首先执行上面的 1 2 步;
然后给表添加分区,把新建的文件夹添加给表做分区
hive> alter table student_p add partition(part=888);
我们知道 load 是会自动创建分区的,所以这样肯定可以
二级分区,也就是多层分区,也就是多层路径
create table student1102(id int,name string,sexex string,age int,dept string) partitioned by(month string, day int) row format delimited fields terminated by ‘,‘ stored as textfile;
month 一级,day 是month 下一级
load data local inpath ‘/usr/lib/hive2.3.6/2.csv‘ into table student1102 partition(month=‘11‘, day=2);
在 hdfs 一看就知道怎么回事了

hive> select * from student1102 where month=11 and day=2;
加个 and 就可以了
load data inpath ‘/user/tuoming/test/test‘ into table part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘); 追加 load data inpath ‘/user/tuoming/test/test‘ overwrite into table part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘); 覆盖 insert overwrite table part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘) select * from part_test_temp; 覆盖 insert into part_test_3 partition(month_id=‘201805‘,day_id=‘20180509‘) select * from part_test_temp; 追加
参考下面的参考资料
参考资料:
https://blog.csdn.net/afafawfaf/article/details/80249974
标签:mit mic orm comm 概念 小结 lis user 覆盖
原文地址:https://www.cnblogs.com/yanshw/p/11778127.html