标签:权限 image 直接 获取 算法 输入 性能 数据收集 传统
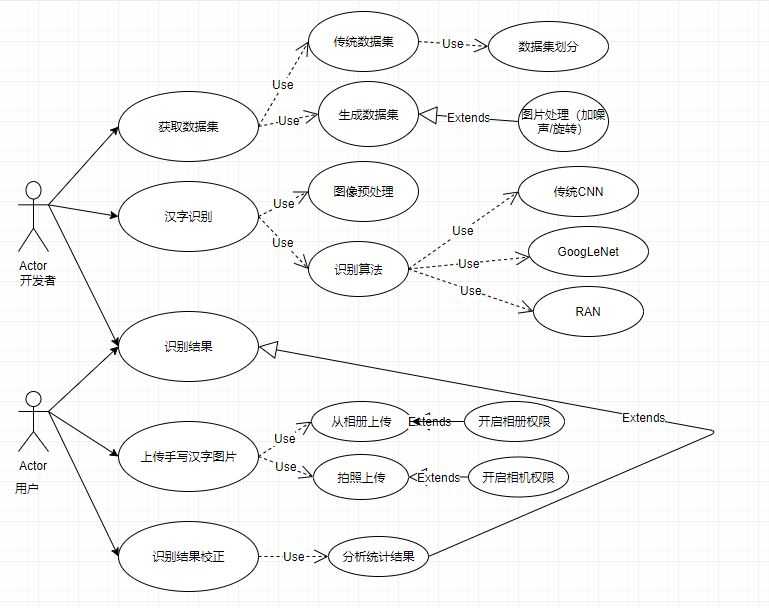
我的工程实践项目为手写汉字识别。用例是关键的需求输入,因此在画用例图前要进行需求识别:确定用例图涉及的系统,Actor,服务(用例)以及它们之间的关联。
<< include >> 表示子用例是父用例的一部分,通常强调离开这个特性,父用例无法达成目标或失去意义;
<< extend >> 表示子用例是父用例的可选场景或技术特征;
<< include >> 箭头指向子用例;<< extend >> 箭头指向父用例。箭头表示的依赖关系。
一、抽取Abstract use case
对工程实践项目分析,抽象用例有:
获取数据集:可以直接使用现有的数据集,也在现有数据集的基础上进一步生成数据集;
汉字识别:在预处理后,可以采用不同的算法进行识别;
识别结果:主要是对识别结果进行展示,并且通过分析进一步优化算法;
上传待识别图片:用户上传待识别的汉字图片;
识别结果校正:通过用户数据收集,可以不断优化。
二、确定用例范围High level use case
获取数据集:传统数据集或生成数据集;
汉字识别:预处理算法此处不赘述,主要用到的识别算法有传统CNN、GoogLeNet和RAN(Radical Analysis Network)
识别结果:结果展示;
上传待识别图片:从相册上传数据或拍照上传数据;
识别结果校正:分析统计结果后,传回开发者进行操作。
三、Expanded use case分析
图像处理:包括图像压缩、旋转、加噪声等操作,用于扩充数据集;
权限申请:涉及隐私安全,需要动态申请;
数据统计分析:对项目性能的进一步优化。
四、用例图
标签:权限 image 直接 获取 算法 输入 性能 数据收集 传统
原文地址:https://www.cnblogs.com/wendyyu/p/11779806.html